AppWorld 训练相关
📅 发表于 2026/03/16
🔄 更新于 2026/03/16
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
Appworld-AgentRL
#GPVO
#Skill-Augmented GRPO
#AgentEvolver
#SALT
#ProST
#Leave-One-Out PPO
🌺 论文摘要
❓问题背景
📕核心方法
✍️实验设置
基础模型
训练任务/数据
评测任务/数据
算法/策略
超参
🍑关键结果
模型效果
重要结论
关键贡献
⛳ 未来方向
🌺 论文摘要
参考链接
核心方法 (SAGE, Skill Augmented GRPO for Self-Evolution)
技能库 + 持续学习 RL框架。
Sequential Rollout:2任务链 训练,Task1生成技能被Task2使用,实现持续学习。
结果奖励 + 技能生成/使用奖励。仅当技能被后续任务成功复用时才给予额外奖励。
训练流程:Claude构造专家数据 -> SFT冷启动 -> SAGE RL训练。
模型效果(Qwen2.5-32B, SFT+RL, AppWorld)
SAGE Test-Normal TGC 72,SGC 60。
性能超过基线GRPO SGC 51.8,GPT4o/Claude3.5 + React,SGC 32.1,SGC 41
SAGE比GRPO步数Tokens更少。12.1 vs 16.4,1475 vs 3613
关键结论
复杂的API调用序列简化为单函数调用,提高准确率,大幅降低推理成本。 何时如何使用Skill。必须做SFT+RL:仅靠Prompt无法让开源模型用好技能库。 专家SFT数据提供格式先验,RL进一步优化策略。必须做SFT冷启动:(SGC指标) 直接RL 25.6,SFT 41.7,SFT+RL 60.7。Query简单,n-gram 检索SKill 效果就挺好。3个任务链并未提升性能。关键贡献
Tool-use Agent 的 SAGE 框架,同场景序列学习 + Skill思想。在新环境中难以利用历史经验持续优化的问题。❓ 问题背景
持续学习难题
局限于特定场景。新环境时,难通过积累经验来持续自我提升。技能库 (Skill Library) 的挑战
技能库方法主要依赖 LLM Prompting(如 Voyager, Agent Skill Induction)。缺点: 依赖基座模型能力:对指令遵循要求高,开源模型难以稳定生成/调用技能。格式不统一:通常将任务执行和技能提炼分开,增加了上下文开销和推理延迟。缺乏针对性优化:没有专门针对生成高质量技能进行 RL 训练。📕 核心方法
统一的交互格式
CodeAct 框架。解决任务时,将常用的操作序列封装为 Python 函数 (Skill)。定义函数 -> 存入库 -> 后续步骤/任务中调用函数。事后总结技能,这种方式即时生效且减少Token消耗。
1. Sequential Rollout
Scenario 结构(每个场景包含3个相似任务)。任务链 先解决 生成技能存入库 更新后的技能库 目的:模拟真实场景下的持续学习,强制模型学习如何复用前一个任务的经验。2. Skill-Integrated Reward (技能集成奖励)
Outcome 奖励: 任务成功1,失败0。Skill 奖励: 技能生成奖励:如果 生成的技能帮助成功解决奖励 技能使用奖励:如果 成功使用了 完成任务,则奖励 惩罚:模型未生成代码 直接结束,给予 -1.0 惩罚。3. 训练策略
算法:GRPO (Group Relative Policy Optimization)。优势计算:基于任务链的期望回报,不使用 KL 惩罚。✍️ 实验设置
基础模型
Qwen2.5-32B-Instruct数据集
难度 1-2),未使用难度3数据。24个场景。1.1k 轨迹数据。 Claude 3.5 + Skill Agent,拒绝采样,筛选任务成功+有效利用技能的数据。训练策略
技能定义和调用格式。2个任务 组成链做Sequential Rollout。评估指标
训练参数
🍑 关键结果
模型效果(Qwen2.5-32B, SFT+RL, AppWorld)
SAGE Test-Normal TGC 72,SGC 60。
Base GRPO: TGC 69.2,SGC 51.8。GPT-4o +ReAct: SGC 32.1Claude 3.5 Sonnet +ReAct :SGC 41.1SAGE比GRPO步数Tokens更少。12.1 vs 16.4,1475 vs 3613
关键结论
复杂的API调用序列简化为单函数调用,提高准确率,大幅降低推理成本。 何时如何使用Skill。必须做SFT+RL:仅靠Prompt无法让开源模型用好技能库。 专家SFT数据提供格式先验,RL进一步优化策略。必须做SFT冷启动:(SGC指标) 直接RL 25.6,SFT 41.7,SFT+RL 60.7。3个任务链并未提升性能。Skill 检索方式对比
Same Scenario: SGC 60.7%Query N-gram 检索: SGC 60.1% (几乎无损)Embedding 检索:SGC 59.5%简单的N-gram检索在AppWorld 这种指令相似度高的场景下非常有效。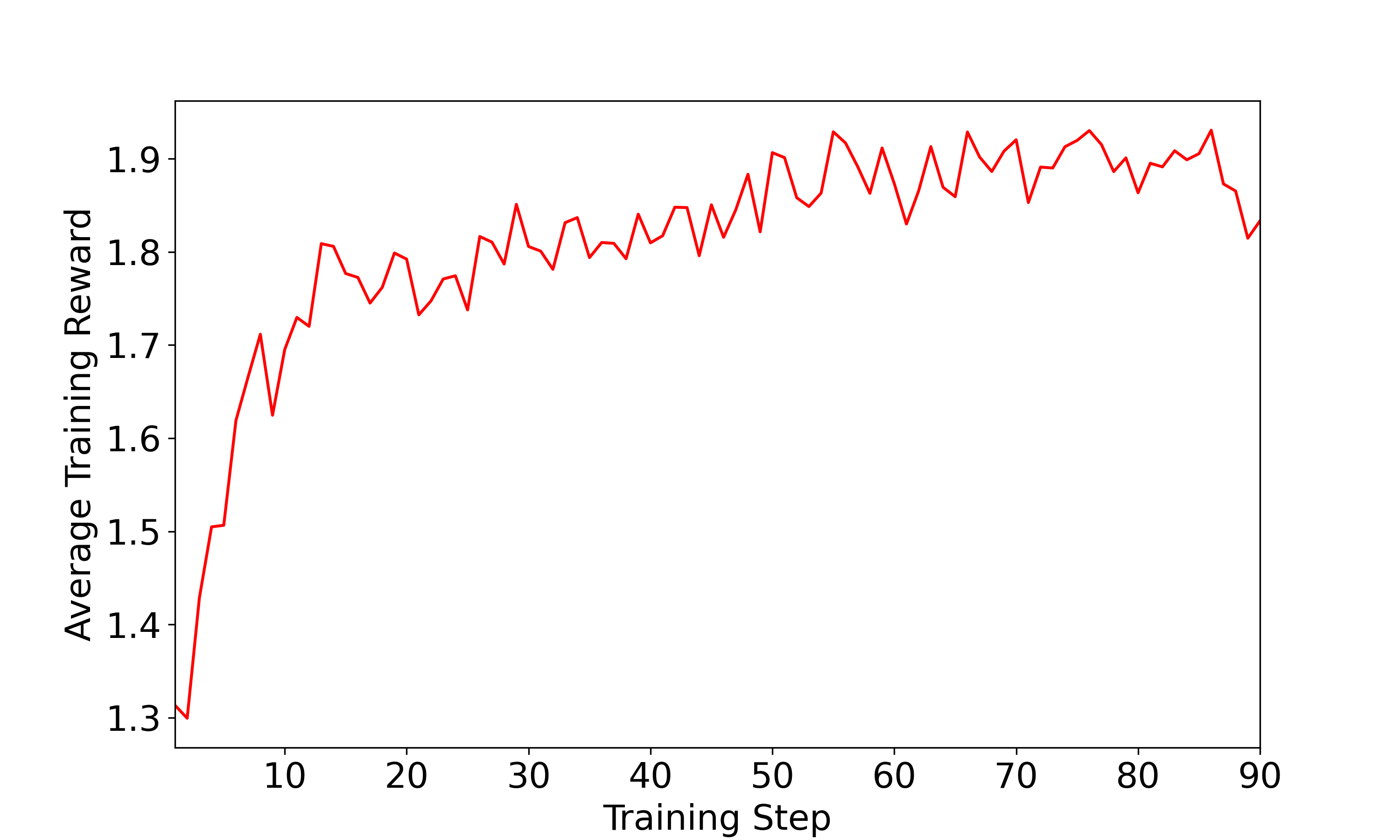
⛳ 未来方向
技能检索增强
同一场景、简单检索。功能语义的专用检索器,以应对跨场景的技能复用。任务链长度扩展
3个任务链并未提升性能,可能因为奖励分配不均、梯度方差变大等原因。长序列信用分配问题。更通用的技能库
AppWorld-API。更开放的 Code Agent 或 Web Agent 场景。🌺 论文摘要
参考链接
核心方法
AgentEvolver 框架:无需人工数据,通过环境交互实现自主进化。三大核心机制: Self-Questioning (自提问):好奇心驱动探索环境 -> 合成任务 -> 任务筛选,解决数据匮乏。Self-Navigating (自导航):构建经验池 -> 检索经验 -> 混合Rollout,解决探索效率低。Self-Attributing (自归因):LLM Judge进行步骤级归因(Good/Bad) -> 细粒度奖励,解决奖励稀疏。基础设施:Context Manager (支持滑动窗口、自管理上下文等模板)。模型效果 (Qwen2.5-14B-Instruct)
TGC (Task Goal Completion) avg@8 达 48.7% (Base 18.0%),best@8 达 69.4%。66.5% (Base 41.6%)。55% (40步 vs 90步)。重要结论
Self-Questioning 贡献最大,解决了"学什么"的问题。Self-Attributing 提供了密集的中间奖励,显著提升了样本效率。经验内化 (Implicit RL) 比单纯的 In-Context Learning 效果更好且上限更高。关键贡献
Agent自进化流程 (E -> Task -> Trajectory -> Policy),不再依赖昂贵的人工标注数据。❓问题背景
成本高昂与效率低下
依赖人工数据:现有Agent训练通常需要人工构建任务数据集(SFT数据)。RL探索效率低:传统RL在复杂工具调用环境中依赖随机探索,成功率低,样本利用率差。奖励稀疏:长程任务通常只有最终成败反馈,缺乏中间步骤信用分配。目标
零人工干预的Agent能力提升。未知环境中自主发现任务、积累经验并自我优化。📕核心方法
流程
环境Profile(实体、属性、操作)进行好奇心驱动的随机游走。探索轨迹抽象为(Query, Reference Solution) Pair。实时过滤:词法去重。事后过滤:使用Agent重放验证可行性,剔除幻觉任务。作用
交互Sandbox(无任务环境)转化为Proxy Task Distribution(训练任务集)。Reference Solution,用于后续的Reward计算。经验获取 (Offline)
成功或失败的经验(What to do / What not to do)。经验池 (Experience Pool),形式为自然语言描述。经验混合 Rollout (Online)
检索:根据当前Task检索Top-K经验。混合策略:Prompt中插入经验),其余为Vanilla Rollout。目的:平衡利用(Exploitation,利用经验走捷径)与探索(Exploration,发现新路径)。Mask 经验Loss
Mask 经验Token的Loss双通道奖励设计
LLM Judge 对每一步做打分:GOOD (+1) 或 BAD (-1)。Trajectory-level 标准化,避免长轨迹方差过大。合成奖励
Dense Reward,显著加速收敛。✍️实验设置
基础模型
Qwen2.5-7B-Instruct, Qwen2.5-14B-InstructQwen-Max / Qwen3-235B评测基准
TGC (Task Goal Completion)。算法配置
GRPO 变体。0.1~0.2。🍑关键结果
模型效果(AppWorld, Test-Normal TGC avg@8指标)
Qwen2.5-14B TGC 由 18.8 -> 48.7模型效果(BFCL v3, avg@8指标)
消融实验 (14B)
样本效率
40步 即可达 90步 90%的性能。细粒度信用分配对加速收敛的关键作用。⛳ 未来方向
上下文管理
Context Manager 的不同模板(滑动窗口vs自主压缩)对性能影响大。更智能Memory管理机制。经验利用的权衡
在推理时有效,但在训练时可能导致过拟合,降低泛化探索能力。Guidance 和 Intrinsic Reasoning。多Agent协同
多角色(如Planner-Executor)的联合进化。🌺 论文摘要
参考链接
核心方法
SALT 框架:基于轨迹图构建的细粒度优势分配机制。核心思想:将多个生成的轨迹合并为轨迹图 (Trajectory Graph)。 合并 (Merge):不同轨迹中相同状态和动作的节点合并。分支 (Diverge):不同动作导致路径分叉。优势重估:基于图结构计算每个Step的优势,而非简单广播整个轨迹的最终回报。 共享步骤(出现在成功和失败中)-> 中性优势。关键步骤(仅出现在成功轨迹中)-> 高优势。轻量级插件:无缝集成至 GRPO/RLOO,无需额外Reward Model,无需人工标注。模型效果 (Qwen2.5-1.5B/7B/32B)
69.0% 提升至 80.5% (+11.5%)。64.6% 提升至 66.2%。20.9% (Base GRPO 17.0%)。重要结论
细粒度信贷分配:解决了长程任务中好坏动作纠缠导致梯度冲突的问题。计算开销极低:相比Rollout和Update,SALT引入的开销可忽略不计。无需Critic模型:适用于 Group-Based RL (如 GRPO) 的纯 Policy 优化场景。关键贡献
基于结果稀疏奖励进行Step-level 优势估计的通用方法 SALT。❓问题背景
长程任务挑战
稀疏的最终奖励 (Outcome-based rewards)。粗粒度信用分配 (Coarse-grained Credit Assignment)
最终回报直接广播给轨迹中的每一个 Step。成功轨迹中可能包含冗余/错误步骤(被错误奖励)。失败轨迹中可能包含正确步骤(被错误惩罚)。训练不稳定,策略更新存在梯度冲突,难以收敛到最优解。📕核心方法
1. 轨迹图构建 (Trajectory Graph Construction)
历史状态 和 当前动作 相同,则将它们视为图中的同一个节点。有向无环图 (DAG),揭示了哪些步骤是跨轨迹共享的,哪些是独有的。2. 细粒度优势计算 (Step-level Advantage)
共享节点 (Shared Nodes):出现在多条轨迹(包括成功和失败)中,说明该步骤对结果区分度低,应给予平均/中性优势。独有节点 (Distinct Nodes):仅出现在高分轨迹中的步骤可能是关键成功因素,应给予高优势。3. 轻量化与兼容性
✍️实验设置
基础模型
1.5B, 7B, 32B。训练/评测任务
算法/策略
RLOO, GRPO。RLOO+SALT, GRPO+SALT。超参配置
🍑关键结果
ALFWorld 显著提升
Qwen2.5-1.5B: Qwen2.5-7B: AppWorld 高难度任务突破
Qwen2.5-32B:效率分析
消融实验
⛳ 未来方向
局限性
潜在应用
🌺 论文摘要
参考链接
核心方法
ProST: 多智能体的课程学习微调策略,渐进式引入子任务。多智能体:Orchestrator(规划)、Executor(执行/写代码)、Critic(反馈)。模型效果(Qwen2.5-14B + ProSFT + 多角色)
TGC 达42.3,SGC达26.8,Test-Challenge TGC 14.1, SGC 5.8。重要结论
ProST > SFT > Base:所有模型尺寸,ProST训练的多智能体均优于标准SFT。
14B-MA(ProST) 效果优于 32B-SA(Base),小模型组合可胜单体大模型,推理FLOPs更低。
资源给规划者比较好:规划-执行-评估,14B-7B-7B 显著优于 7B-14B-14B。
关键贡献
❓问题背景
小模型做复杂任务存在挑战
AppWorld 复杂+长交互:需要规划、编码、API调用和错误恢复GPT4效果好但成本高。SLM小模型成本低,但效果不好。现有SFT存在局限性
长轨迹学习困难:直接在完整轨迹上SFT,难学会中间的子任务,易灾难性遗忘或逻辑断层。角色专业化不足:虽拆为多智能体,但单SLM难同时掌握角色的细微差别和长程依赖。效率与效果的权衡
多智能体在计算成本与任务完成率之间权衡的系统研究。📕核心方法
核心思想
课程学习,让模型先学简单的/局部的,再学复杂的/全局的。训练早期,只暴露部分子任务。随Epoch增加,逐步扩展输入上下文,直到覆盖完整轨迹。训练流程
Epoch 0:仅训练特定的子任务子集(例如子任务 2, 3),屏蔽其他。Epoch i:引入更多子任务(例如从子任务 2 扩展到 1-3)。Final Epoch:训练包含所有子任务的完整轨迹。优先掌握核心逻辑,再处理长依赖。Mask错误动作的Loss
正确步骤和自我修正成功步骤的Loss。Mask错误步骤的Loss,避免模型学习错误的推理路径。角色分工
子任务序列(ReAct模式)。处理执行失败,动态调整计划。接收子任务,编写Python代码调用AppWorld API。自我纠错循环。Executor反复失败时介入,审查代码和环境反馈,提供自然语言建议。数据合成Pipeline
Llama-3.3-70B 生成高质量的单智能体轨迹(Rejection Sampling)。Claude-3.7-Sonnet 把单智能体轨迹重写为多智能体训练数据。实际执行验证,确保正确性。✍️实验设置
基础模型
Qwen-2.5-Coder (7B, 14B, 32B) —— 核心实验模型(代码能力强)。Llama-3.1-8B, Phi-4 —— 验证泛化性(推理能力强)。基准测试 (AppWorld)
Test-Normal (域内测试) 和 Test-Challenge (域外测试/OOD)。评估指标
TGC (任务目标完成率), SGC (场景目标完成率)。Inference FLOPs,推理时的浮点运算次数,用于衡量真实的计算开销对比基线
Single Agent (SA): Base, SFTMulti-Agent (MA): Base, SFT, ProST(Ours)🍑关键结果
模型效果(Qwen2.5-14B + ProSFT + 多角色)
TGC 达42.3,SGC达26.8,Test-Challenge TGC 14.1, SGC 5.8。关键结论
ProST > SFT > Base:所有模型尺寸,ProST训练的多智能体均优于标准SFT。
14B-MA(ProST) 效果优于 32B-SA(Base),小模型组合可胜单体大模型,推理FLOPs更低。
资源给规划者比较好:规划-执行-评估,14B-7B-7B 显著优于 7B-14B-14B。
⛳ 未来方向
局限性
显存开销:虽然FLOPs(时间成本)降低了,但同时加载3个模型对GPU显存要求很高。数据依赖:严重依赖闭源模型(Claude 3.7)进行数据的多智能体转换。未来探索
OOD 泛化:Test-Challenget提升少,如何让Agent适应未见API是关键。动态资源分配:根据任务难度动态选择不同大小的模型角色。更通用的课程:其他长周期Agent任务(如SWE-bench)上的ProST应用。🌺 论文摘要
参考链接
核心方法
LOOP: 留一法算优势 + 去掉std + PPO Off-Policy + PPO Clip + Token级建模AppWorld 训练数据筛选:去掉难度3场景、再去掉6场景模型效果(Qwen2.5-32B-Inst, AppWorld)
TestNormal:TGC 达71.3分,SGC 达53.6分。整体均超过其他方法。重要结论
per-token > per-turn > per-traj,71.3 > 64.1 > 53.3组内std归一化 会降低9pt:71.3 -> 61.9 移除KL惩罚有效果:Test-C TGC 从 22.4 -> 26.6Loop 优于 GRPO:71.3 > 58。LOOP 非归一化 优于 GRPO 归一化 ?Loop 优于 PPO:71.3 > 50.8。Critic 不好训,易引入误差关键贡献
各方法对比实验❓问题背景
LLM Agent处理真实任务效果不行
python环境可能交互40轮、32k长度。stateful、多领域、多app、环境API交互现有模型效果不好RLOO 缺点
同策略算法,样本效率低。Trajetory-Level 建模,但Token-Level 通常更稳定一些。RL建模:llm token-level MDP
1. REINFORCE算法
参考笔记:REINFORCE、REINFORC++算法、优势AC算法
策略梯度,优势决定更新方向。优势大于0,鼓励;优势小于0,抑制。
2. RLOO 算法
参考笔记:RLOO
REINFORCE+留一法计算优势,无需Critic和Ref模型。
3. 本文LOOP 算法
RLOO + 异策略,具体引入PPO信任域,提升样本效率。4. GRPO 算法
5. PPO 算法
6. 其他非RL
不断筛选好样本,来微调模型。PPO 建模方式
Per-轨迹:把整个序列看成1个动作,计算1个总的重要性权重。GSPO 序列级IS权重
Per-Token:把每个词看成1个动作,为每个词 单独计算重要性权重。更稳定、平滑。
PPO Loss 计算方式
Seq-Level-Loss:PPO Seq-level-Loss, GSPO Seq-Level-LossToken-Level-Loss:DAPO Token-Level-LossPPO CLIP 粒度
per-trajectory:1条轨迹计算1个IS权重。
per-turn:为每个回合计算1个IS权重。
per-token:为每个token单独计算1个IS权重。
买东西,1个app,8个动作,每回合最多1个参数场景和任务
多样化复杂逻辑:邮件、支付、音乐、购物、打电话、文件系统等。9个真实app,457个API调用,单API最多17个参数。250个场景,每个场景有3个任务,总计750个任务。1-3档。训练评测数据量
训练:35场景,105个任务。Level 1-2-3:36, 36, 18
Dev:20场景,60任务。Level 1-2-3:30, 24, 3
Test-Normal:56场景,168任务。Level 1-2-3:57, 48, 63
Test-Challenge:139场景,417任务。复杂、新APP。Level 1-2-3:72, 150, 195
评测维度
1套单元测试,3个维度事情已完成:任务所要求的环境状态成功执行无副作用:没有对环境或APP造成额外的修改答案正确:agent最终答案和标准答案一致评估指标
任务目标完成率场景目标完成率3个任务全部完成,才算场景完成。状态
初始隐藏状态:Python REPL状态、模拟数据库等,智能体看不见,
上下文:user prompt
所有token序列:大模型生成token + 环境返回token,是agent可观察的历史信息。
动作
状态转移
LLM生成token 环境返回token轨迹概率
优化目标
📕核心方法
PPO Off-Policy 提高样本效率
多轮次训练ppo_epochs轮,训练多轮。重要性权重来做分布修正。ppo_epochs=1,则LOOP退化成RLOO。小批量学习多个mini-batch,进行多次梯度更新。PPO Clip 保证更新稳定
PPO-Clip 限制更新策略幅度 保证稳定标准差
不稳定的任务上,标准差大除以标准差,会削弱或抑制那些偶然成功的高奖励学习信号。差异
除以标准差。不除以标准差。LOOP 实验
不除以标准差好,能更有效地从不稳定的、探索性的行为中学习。相关算法
不除以标准差,避免难度偏差。Global std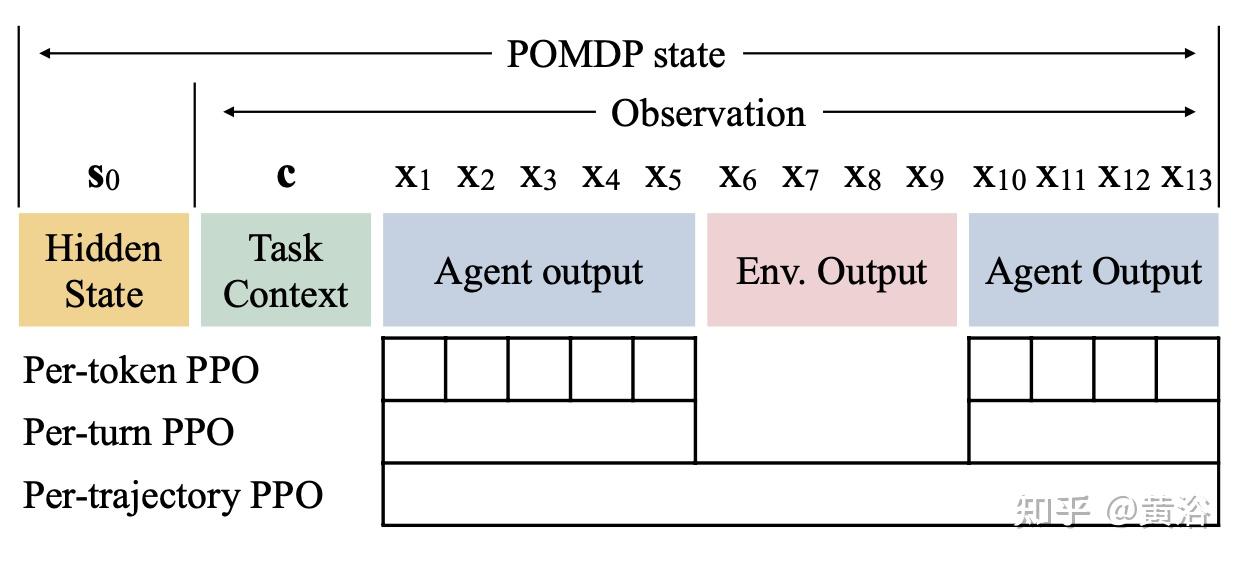
✍️实验设置
奖励函数
单元测试通过比例。no sparse训练数据
筛选出24场景,共72任务。先去掉难度3场景,只用难度1和2(35 -> 30)。 去掉6个场景:30 -> 24。其他超参
训练40轮,测试50轮。40个任务、每次学习40*6=240条序列1500 token;环境单次:3000 token。训练50epoch,取最好的checkpoint。基础模型
训练任务/数据
筛选后的训练数据:24个场景,共72个任务。评测任务/数据
Test-normal, Test-Challenge算法/策略
LOOP, LORA训练超参
🍑关键结果
模型效果(Qwen2.5-32B-Inst, AppWorld)
TestNormal:TGC 达71.3分,SGC 达53.6分。重要结论
per-token > per-turn > per-traj,71.3 > 64.1 > 53.3组内std归一化 会降低9pt:71.3 -> 61.9 移除KL惩罚有效果:Test-C TGC 从 22.4 -> 26.6Loop 优于 GRPO:71.3 > 58。LOOP 非归一化 优于 GRPO 归一化 ?Loop 优于 PPO:71.3 > 50.8。Critic 不好训,易引入误差关键贡献
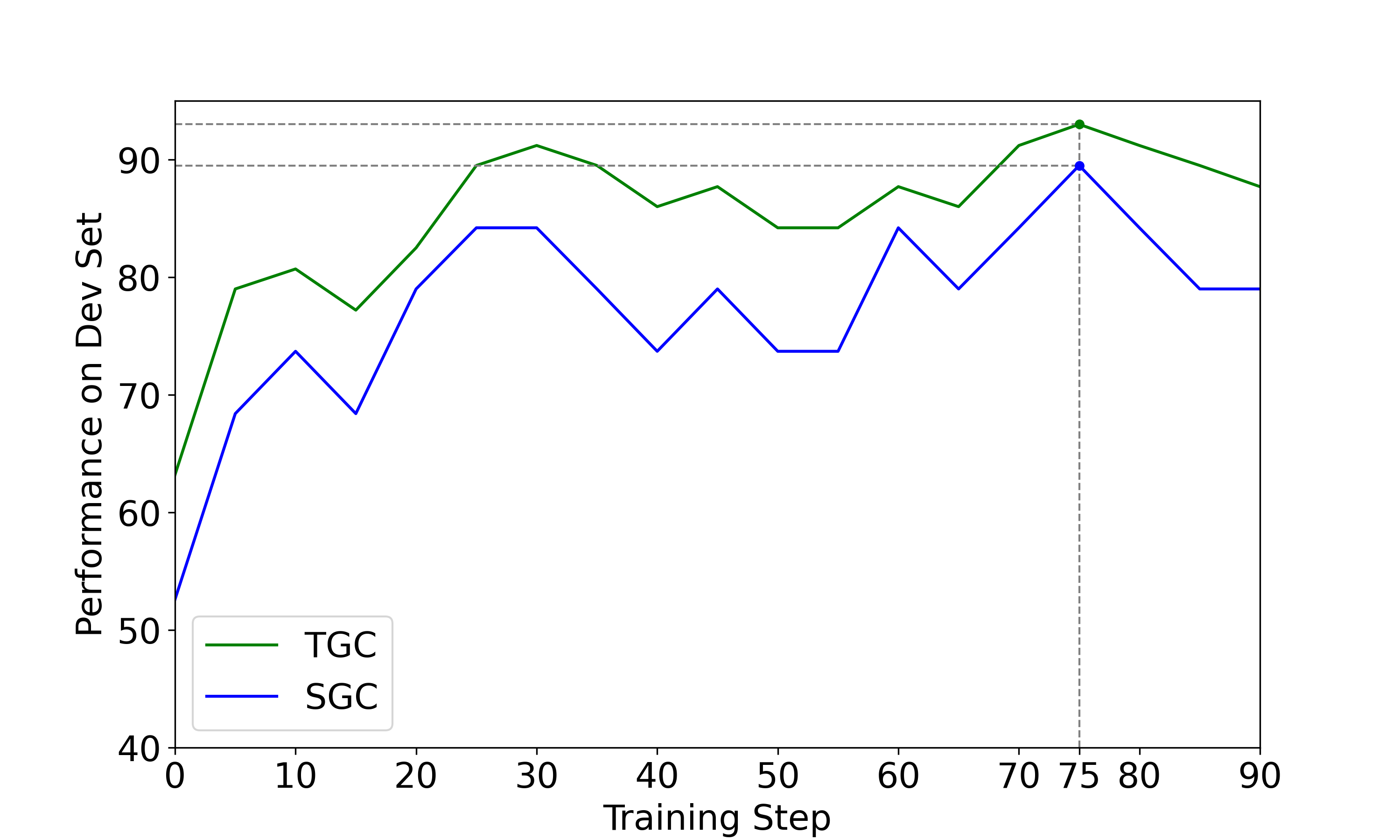
莽撞到谨慎:不必要代码执行减少6倍,避免了次优loop想当然到查文档:调用特定APP接口时,API文档查询增加60%瞎猜到求证:毫无根据的假设减少了30倍,虚构密码等重要位置减少了6倍脆弱到坚韧:失败后放弃次数减少3倍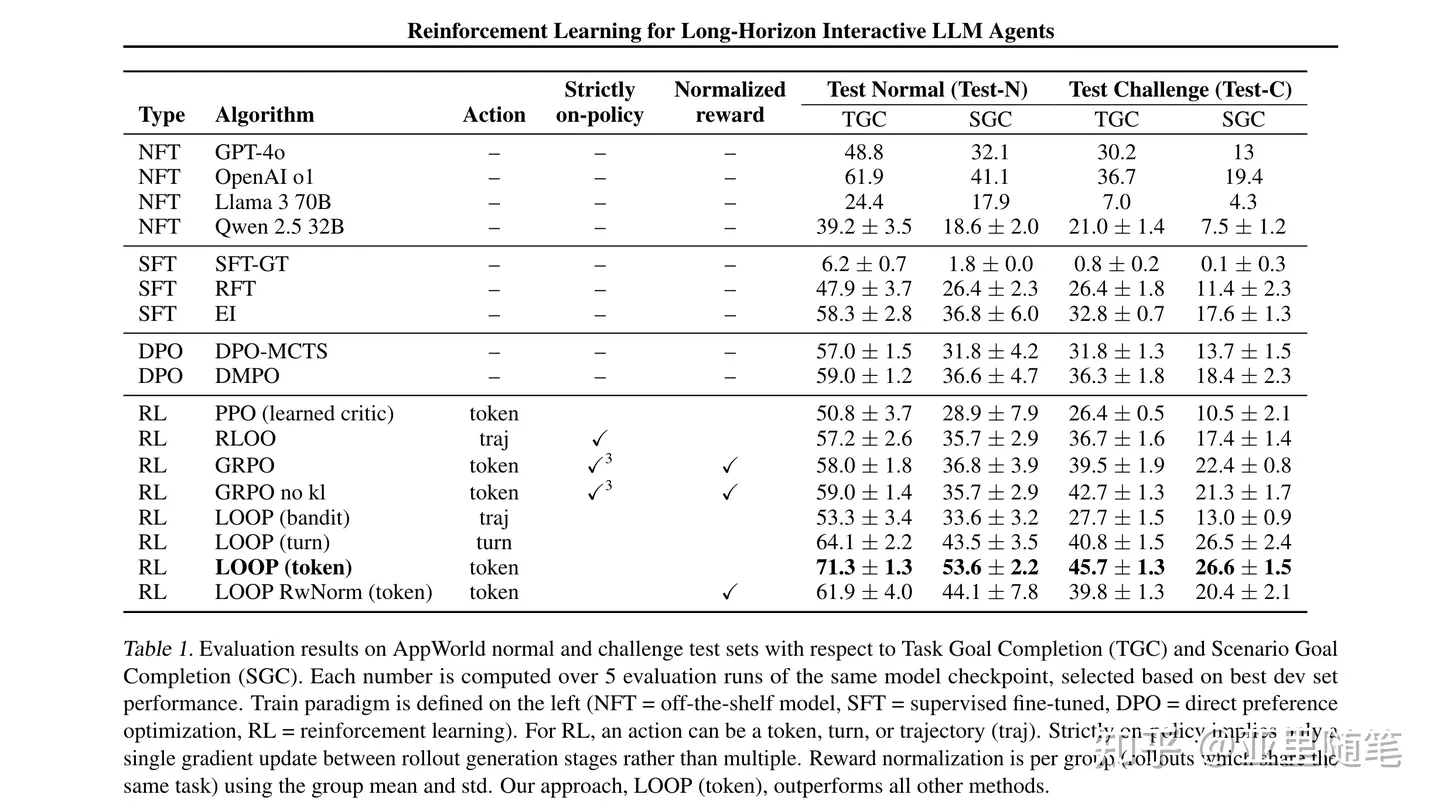

⛳未来方向
性能还不够好,提升成功率。目前仅70%完成。需提升真实复杂情况。 多模态能力:看懂网页截图、图表等。