Agent基础概念 (李宏毅笔记)
📅 发表于 2025/05/13
🔄 更新于 2025/05/13
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
agent
#agent
#function call
#tool use
#memory
#planning
#reasonning
学习李宏毅老师agent课程的笔记。
类似于RL,人类给定Goal,期望Agent能自主完成任务。
观察环境执行Action不断循环,直到完成任务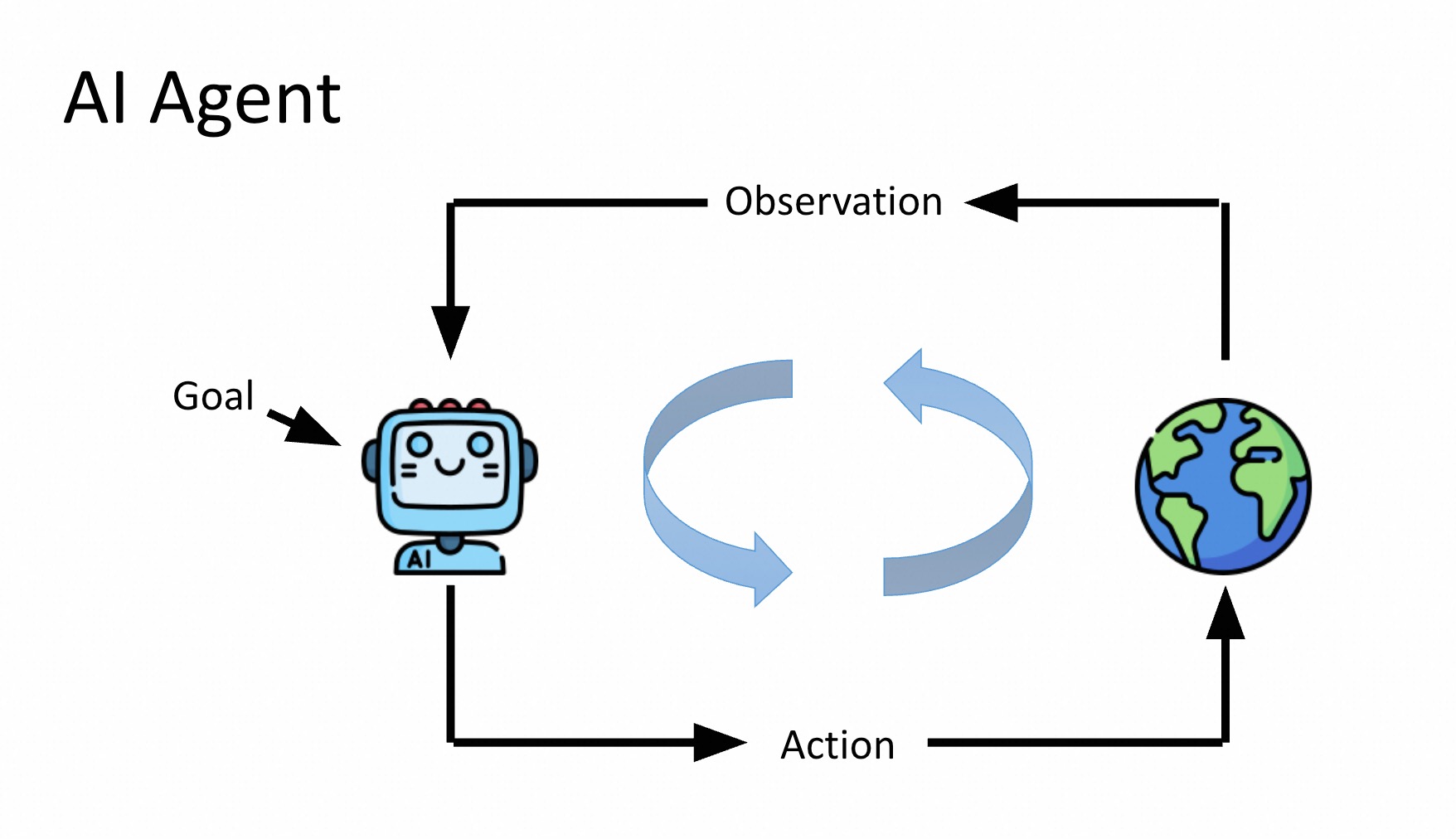
AI Agents are programs where LLM outputs control the workflow.
| Agency Level | Description | Short name | Example Code |
|---|---|---|---|
| ☆☆☆ | 模型输出和流程无关 | Simple processor | process_llm_output(llm_response) |
| ★☆☆ | 输出简单的if else | Router | if llm_decision(): path_a() else: path_b() |
| ★★☆ | LLM output controls 函数执行 | Tool call | run_function(llm_chosen_tool, llm_chosen_args) |
| ★★☆ | LLM output controls iteration and program continuation | Multi-step Agent | while llm_should_continue(): execute_next_step() |
| ★★★ | One agentic workflow can start another agentic workflow | Multi-Agent | if llm_trigger(): execute_agent() |
| ★★★ | LLM acts in code, can define its own tools / start other agents | Code Agents | def custom_tool(args): ... |
直接使用 LLM来构建Agent
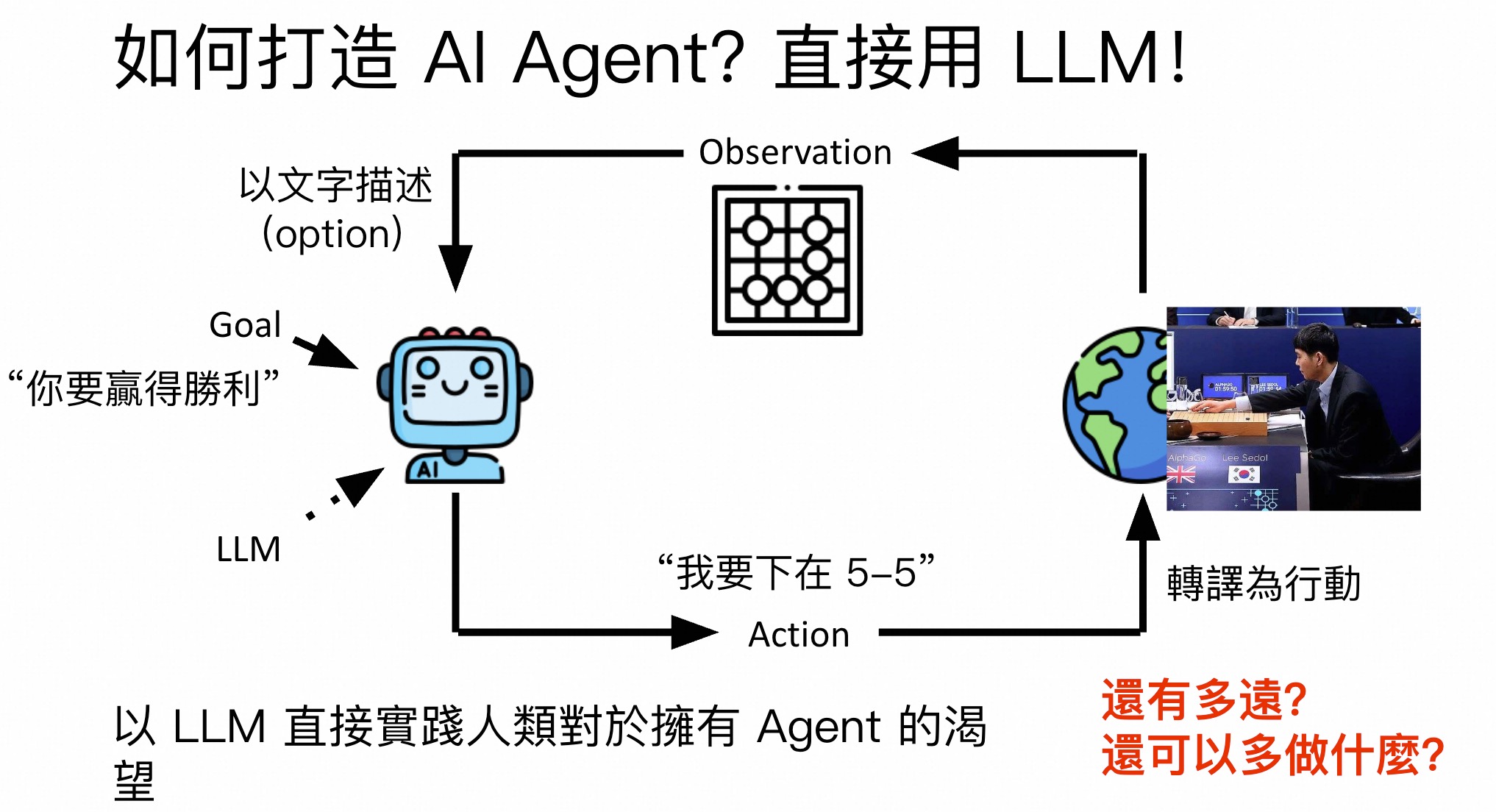
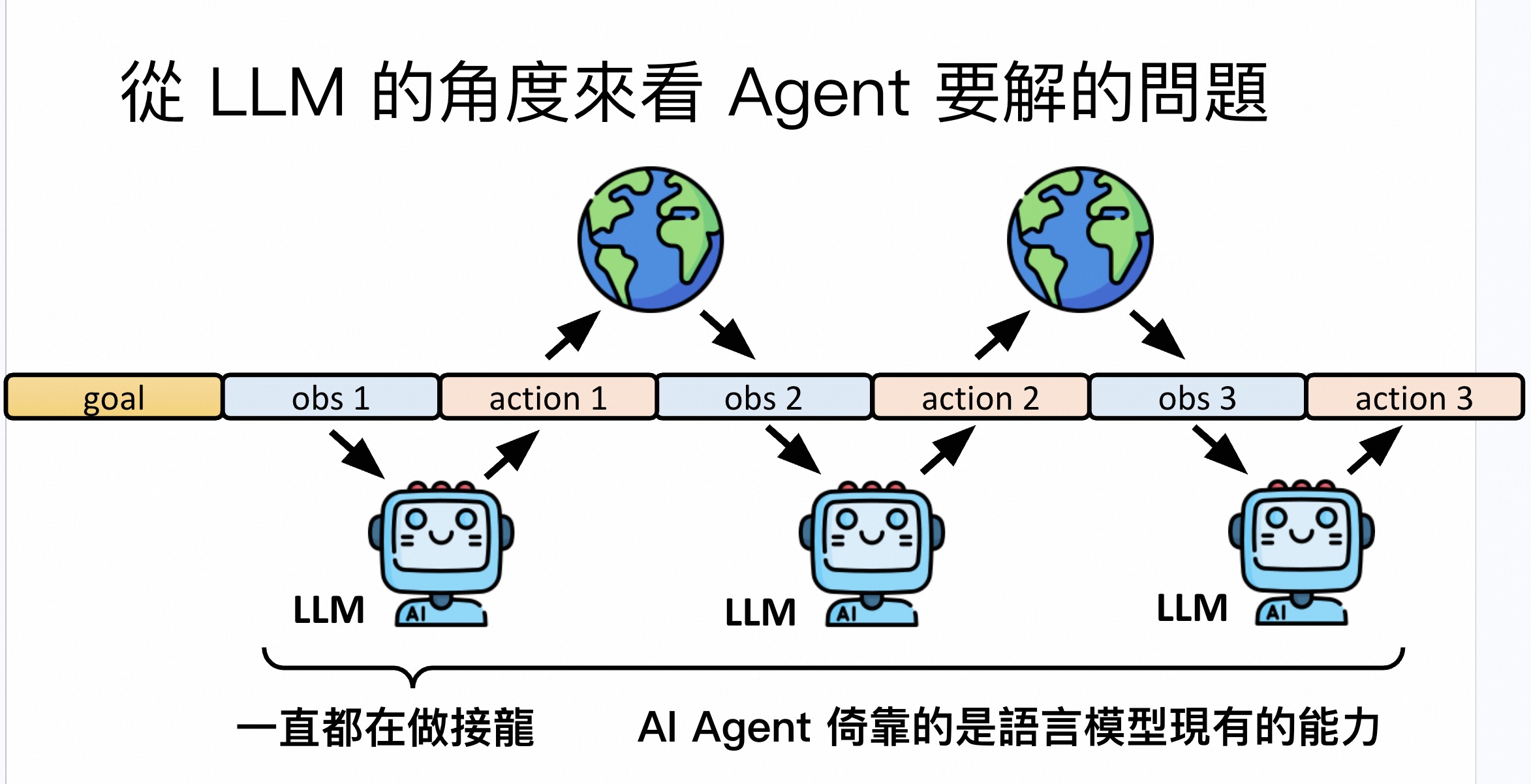
需要解决的问题
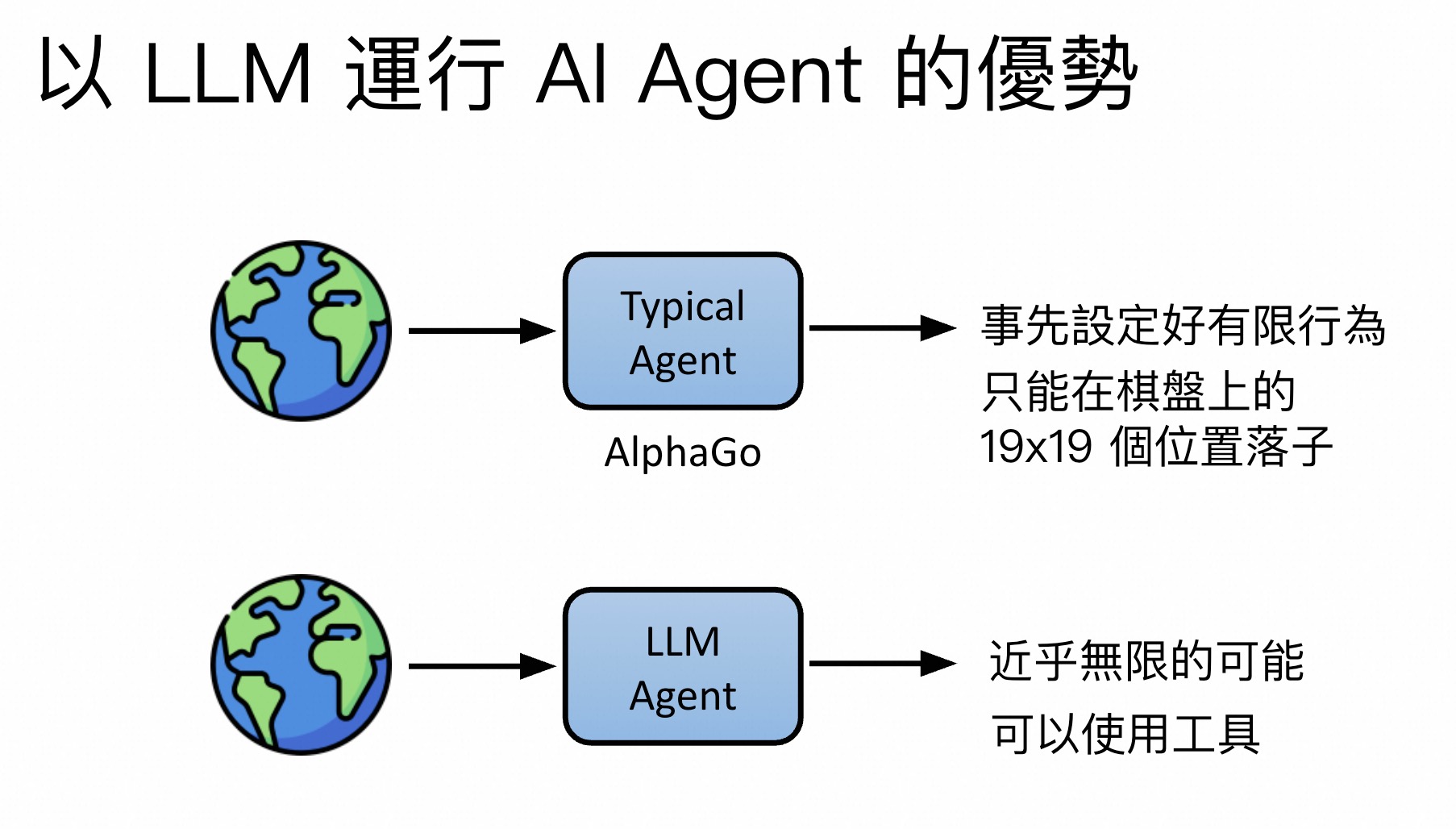
优势:无限可能
包括NPC、购物、训模型、做报告、上网操作电脑等等。
NPC
操作电脑
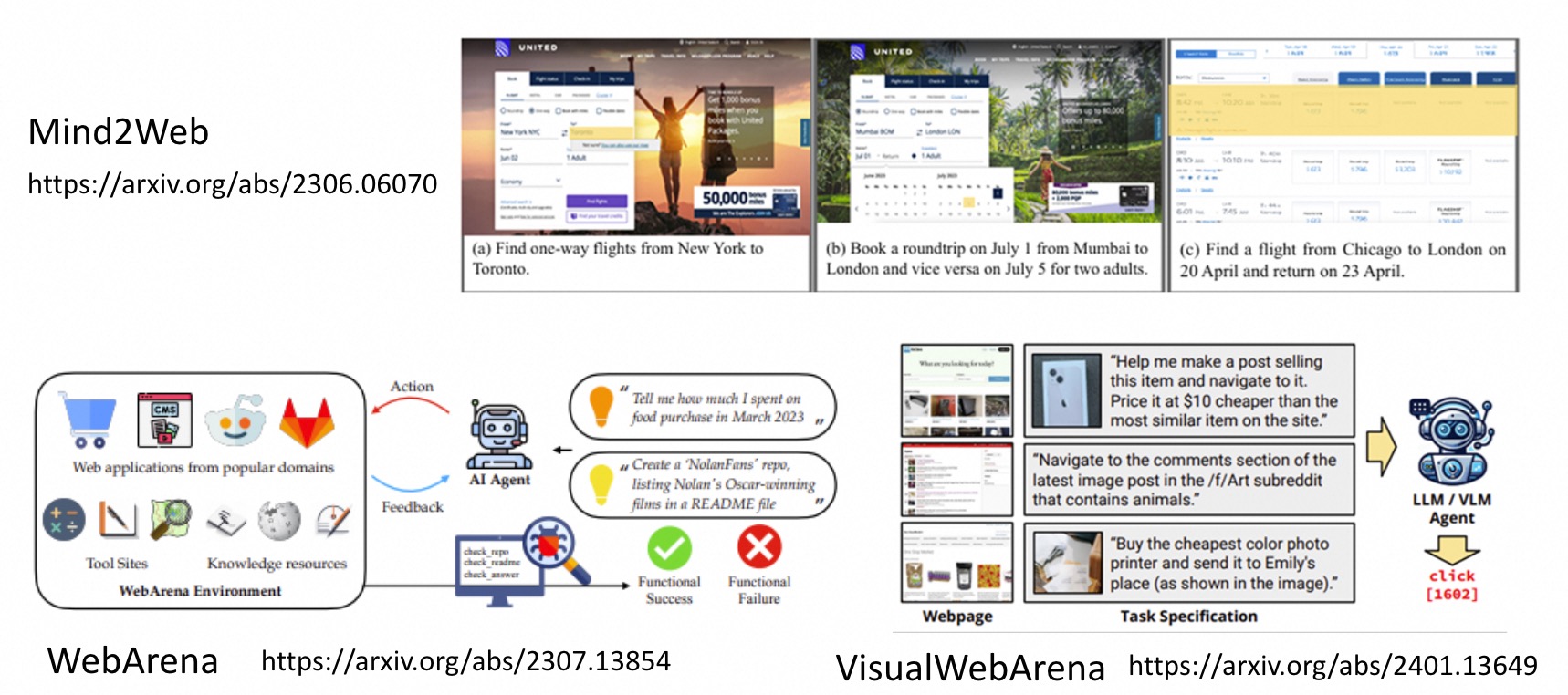
训练模型
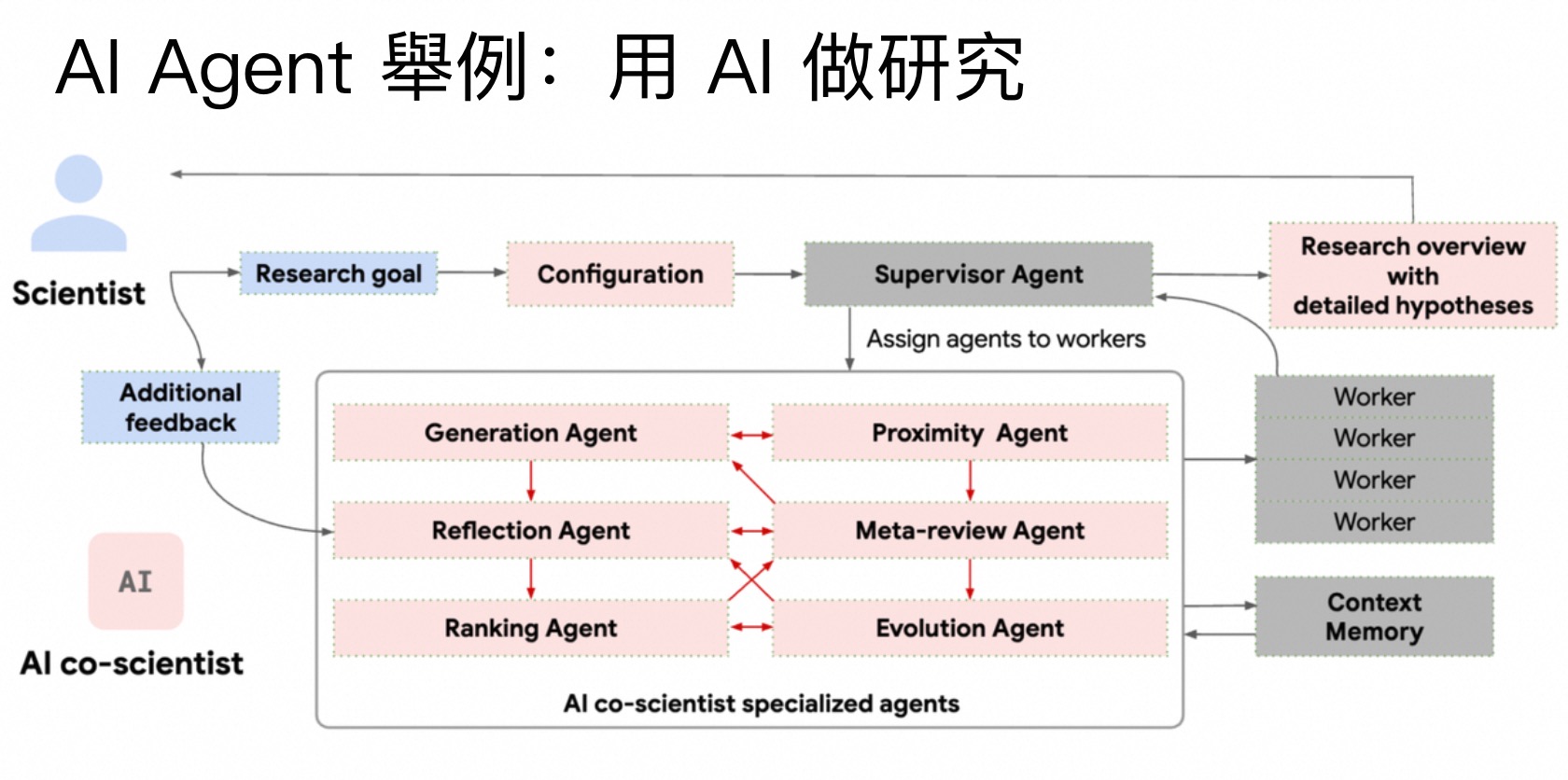
做研究
迈向更加实时交互的应用
及时互动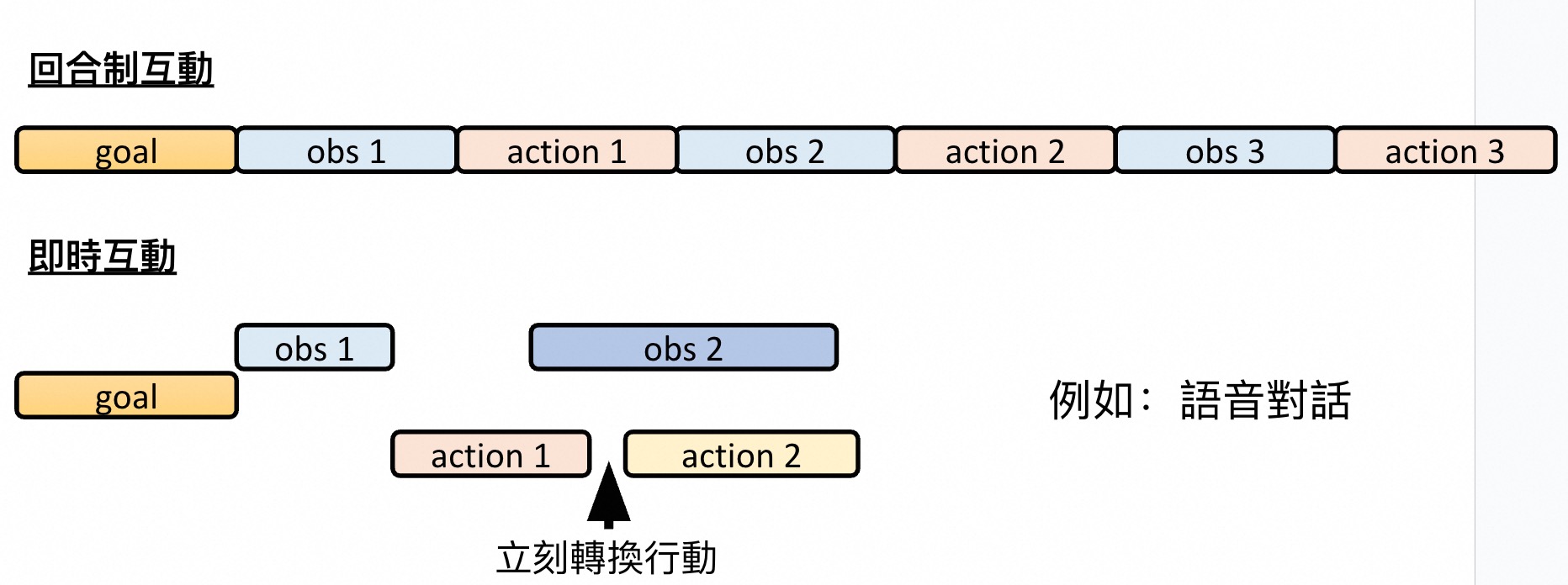
按照是否微调模型,可以分为 微调模型(如RL/SFT)和 不微调模型两种,本节聚焦在后者。
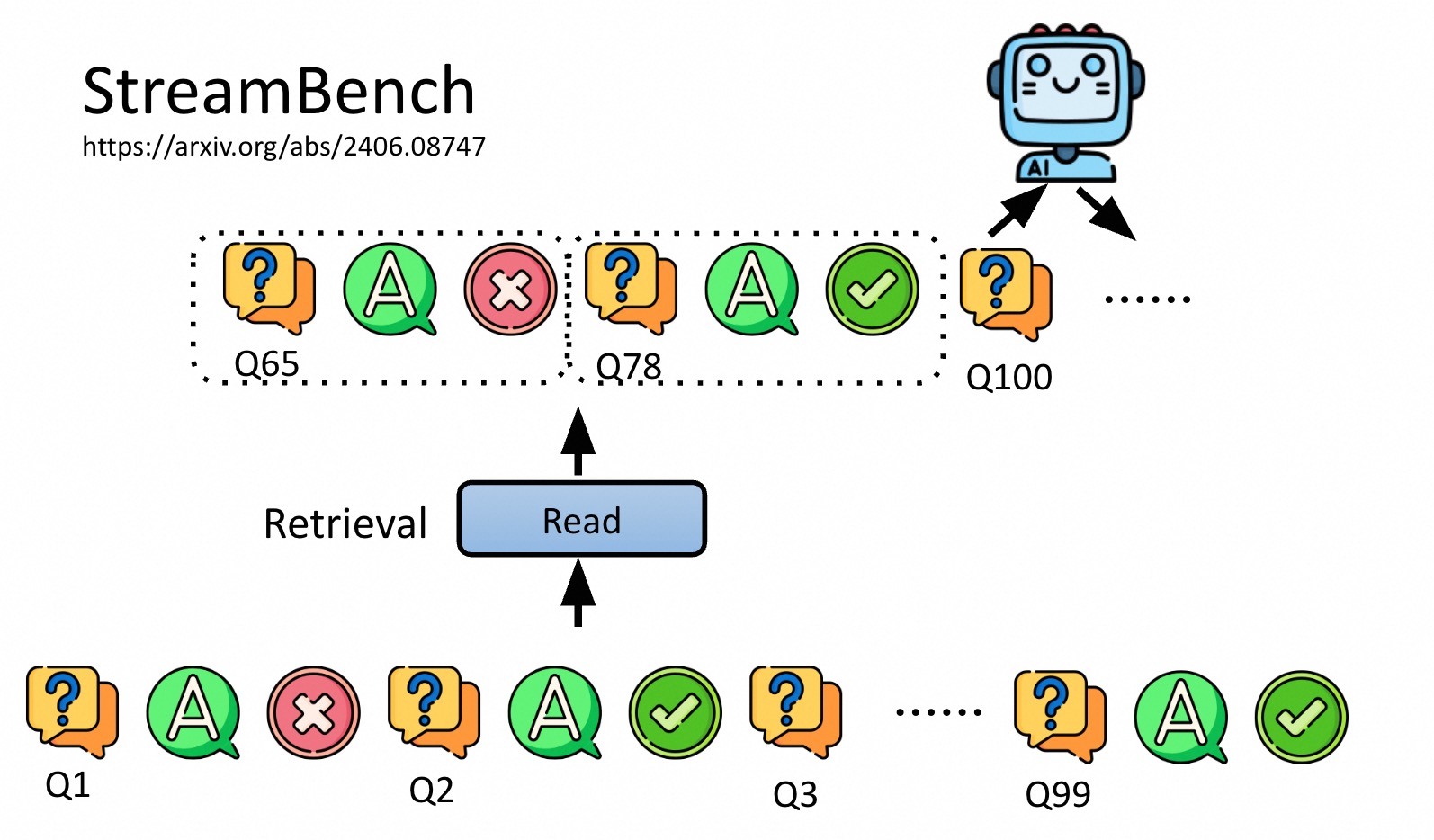
Agent检索历史Memory来调整当前的行为。
经验(memory)主要来自自身,外部也可以(RAG)。write模块,来决定当前经验是否存下来。read模块,检索经验来做指导。检索就是一个 RAG。reflection模块,对检索来的经验做 总结汇总,得到更好的经验和想法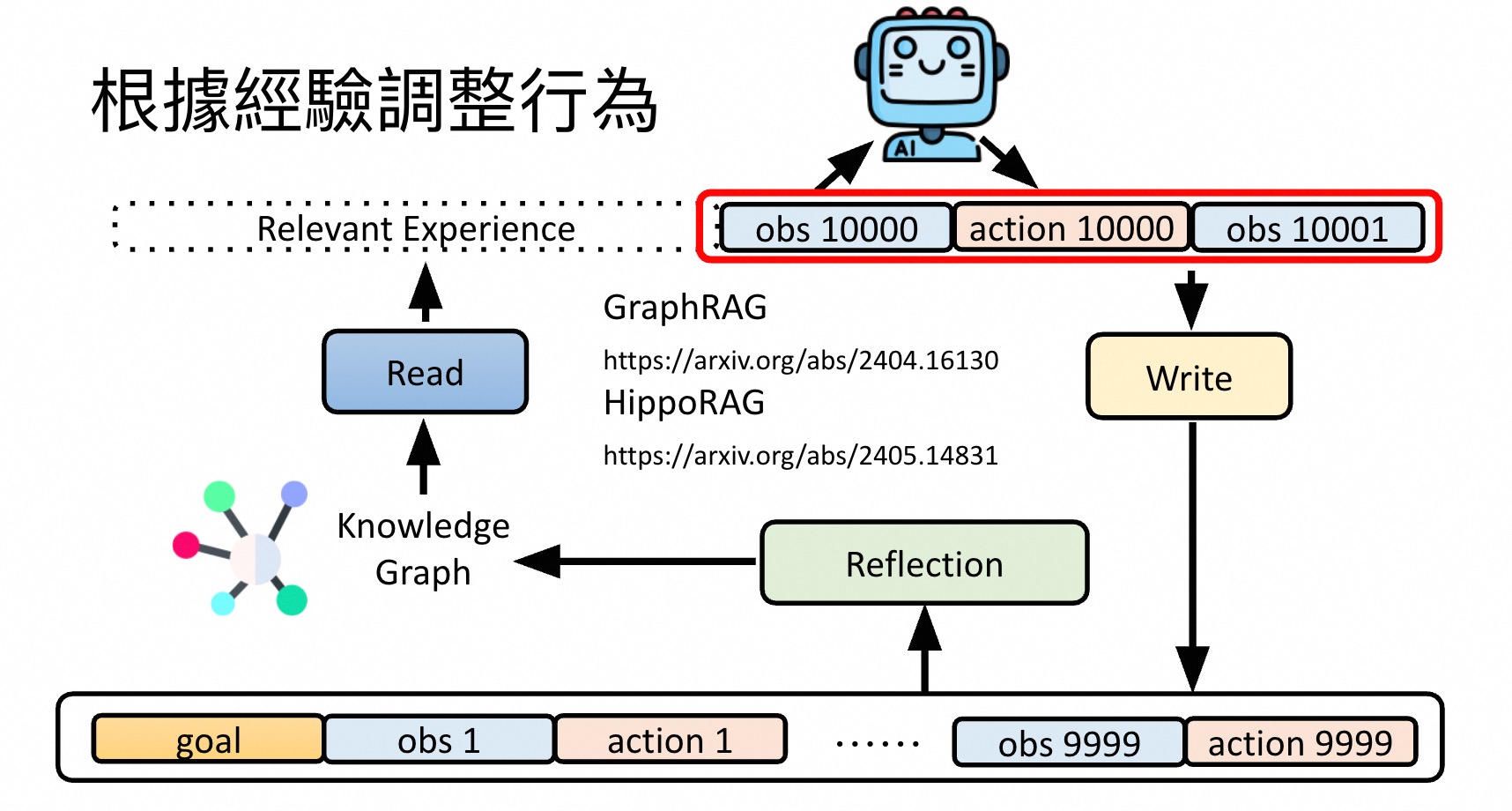
工具可以看作是Function,使用工具就是调用Function,又叫做 Function Call。常用工具包括:
以下是一个通用的调用方法,不是唯一的。
Prompt配置
模型根据User Prompt来决定是否调用工具。如果需要调用,则输出工具调用指令
<tool>Temperature('高雄', '2025.03.10 14:00')</tool><output>32度</output>,再次调用模型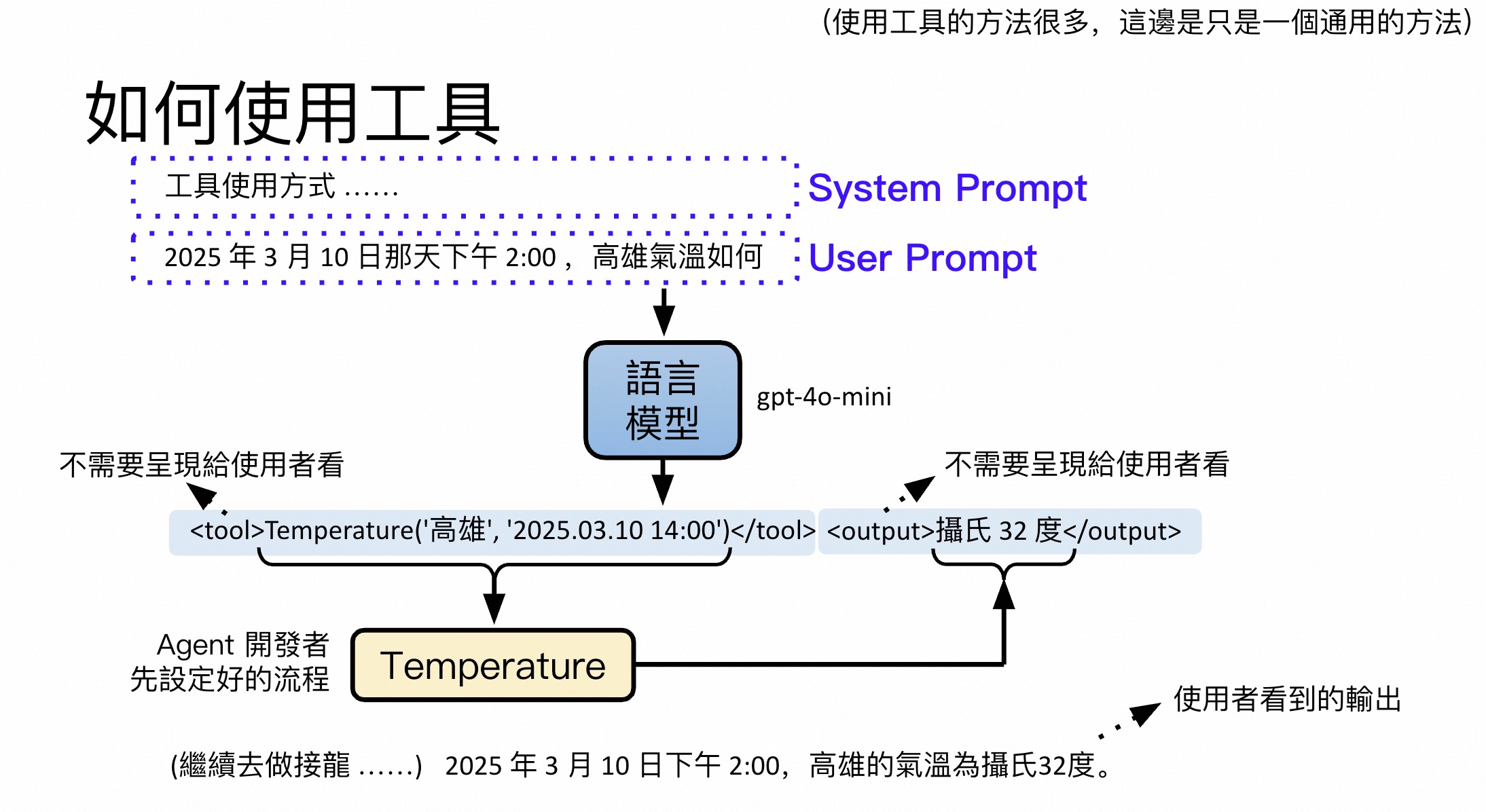
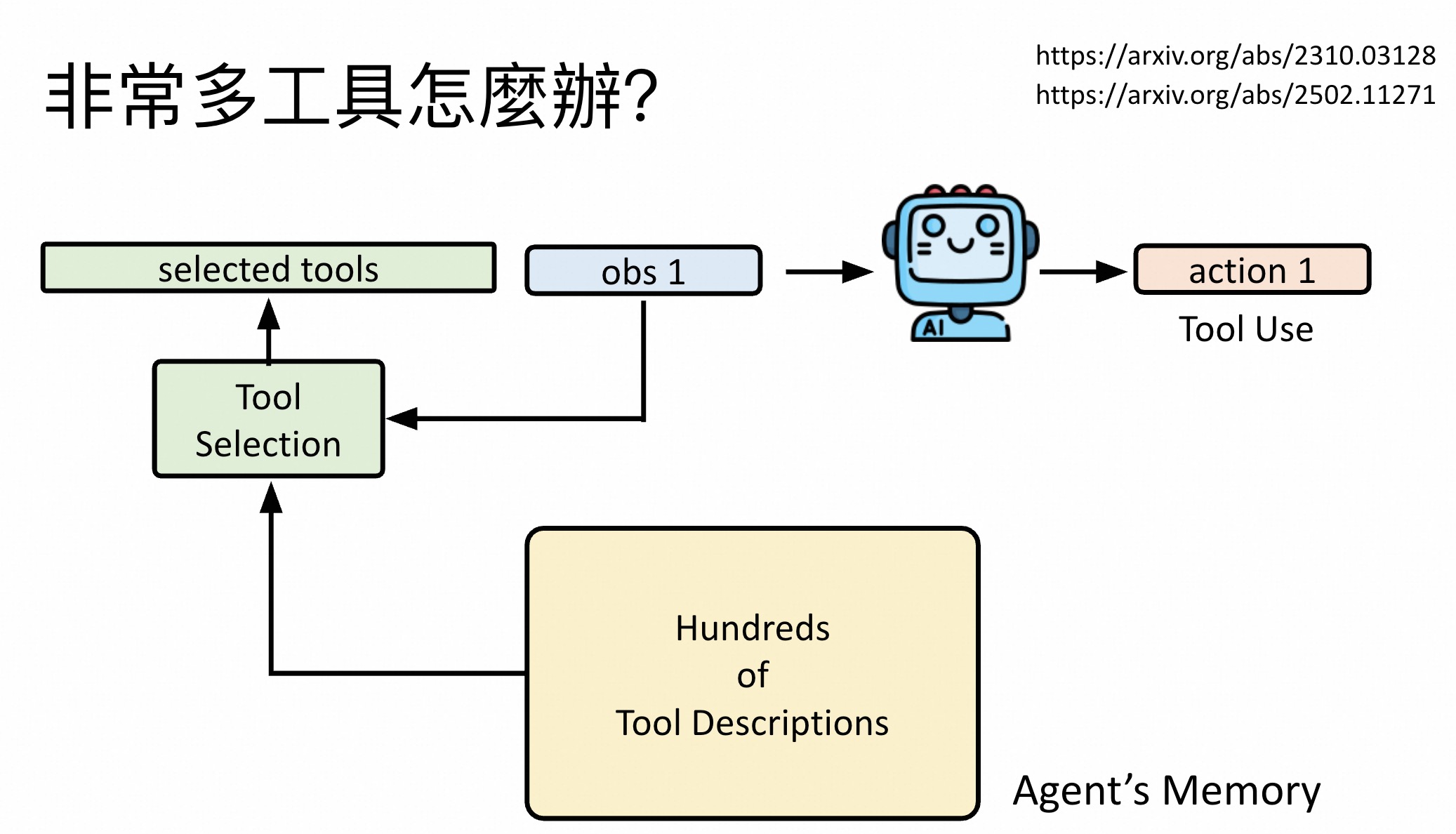
由于冗长问题,并不能把所有工具说明都放到System Prompt里。工具集合说明放到Agent Memory里,再接一个RAG,仅选择所需要的工具即可。
模型会因为过度相信工具而犯错。比如:
比如
如果工具结果出现明显错误,模型会认为其错误。 比如
LLM有一定自己判断力,取决于模型自身能力和知识。
那么什么样的外部知识信息,模型会比较容易相信呢?

比较相近的外部知识。(可以计算模型自身知识的置信度)其他AI说的话。不相信人类的话新的文章。比如3*4,一下能计算出12,但通过工具,可能会更慢。
使用工具不一定总是有效率
让模型做执行前,先做计划,列举一系列的action,再根据action来执行。
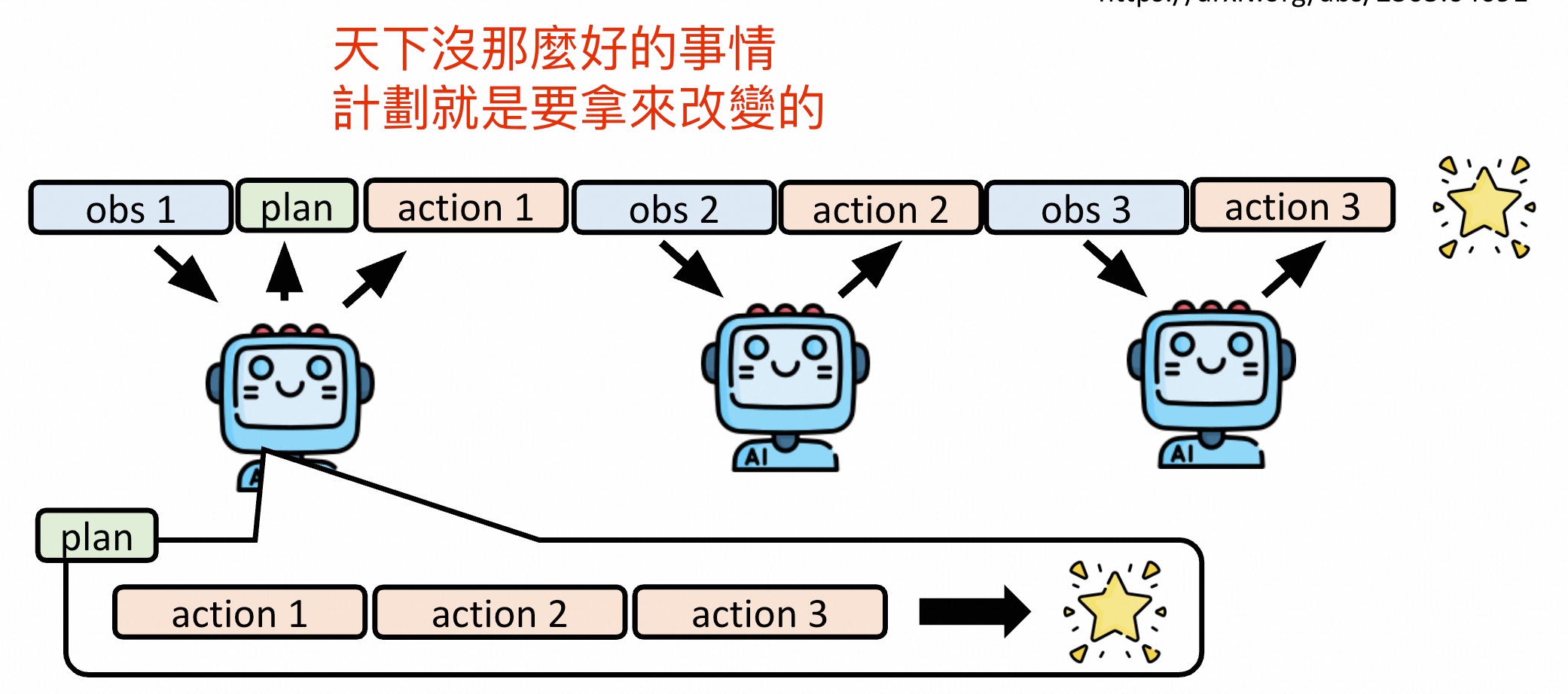
但原有的计划不一定适用,会发生改变。
比如,每次action时让模型重新review plan。
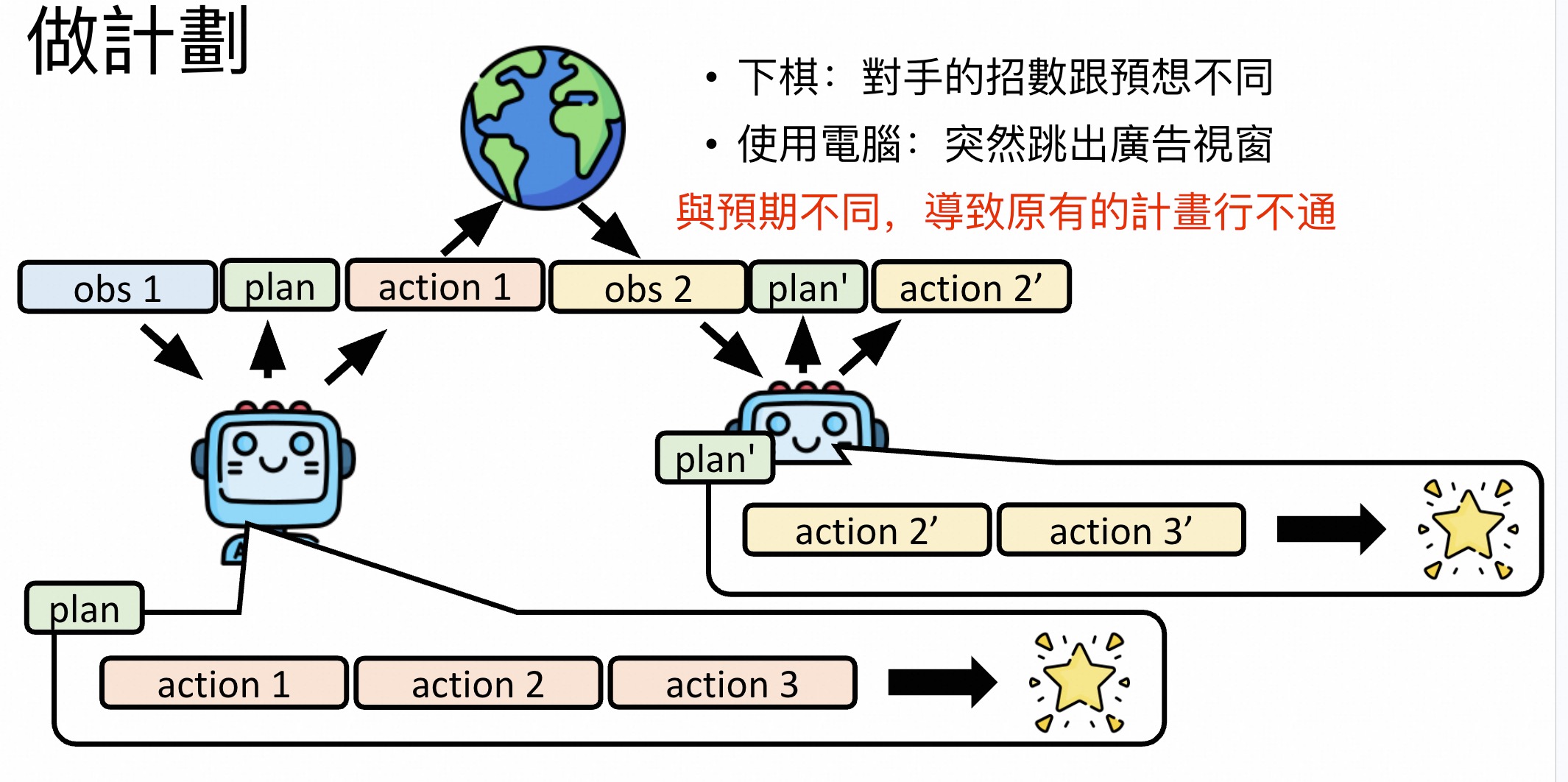
AI可能见过相关内容)、神秘方块(复杂规则,推理)引入限制工具辅助,模型做出好效果(90分)。https://arxiv.org/abs/2404.11891模型有一定Plan能力,但效果一般,需考虑强化。
1、暴力搜索可行吗?
2、优化暴力搜索
覆水难收。提前想象脑内小剧场由环境来决定行为的。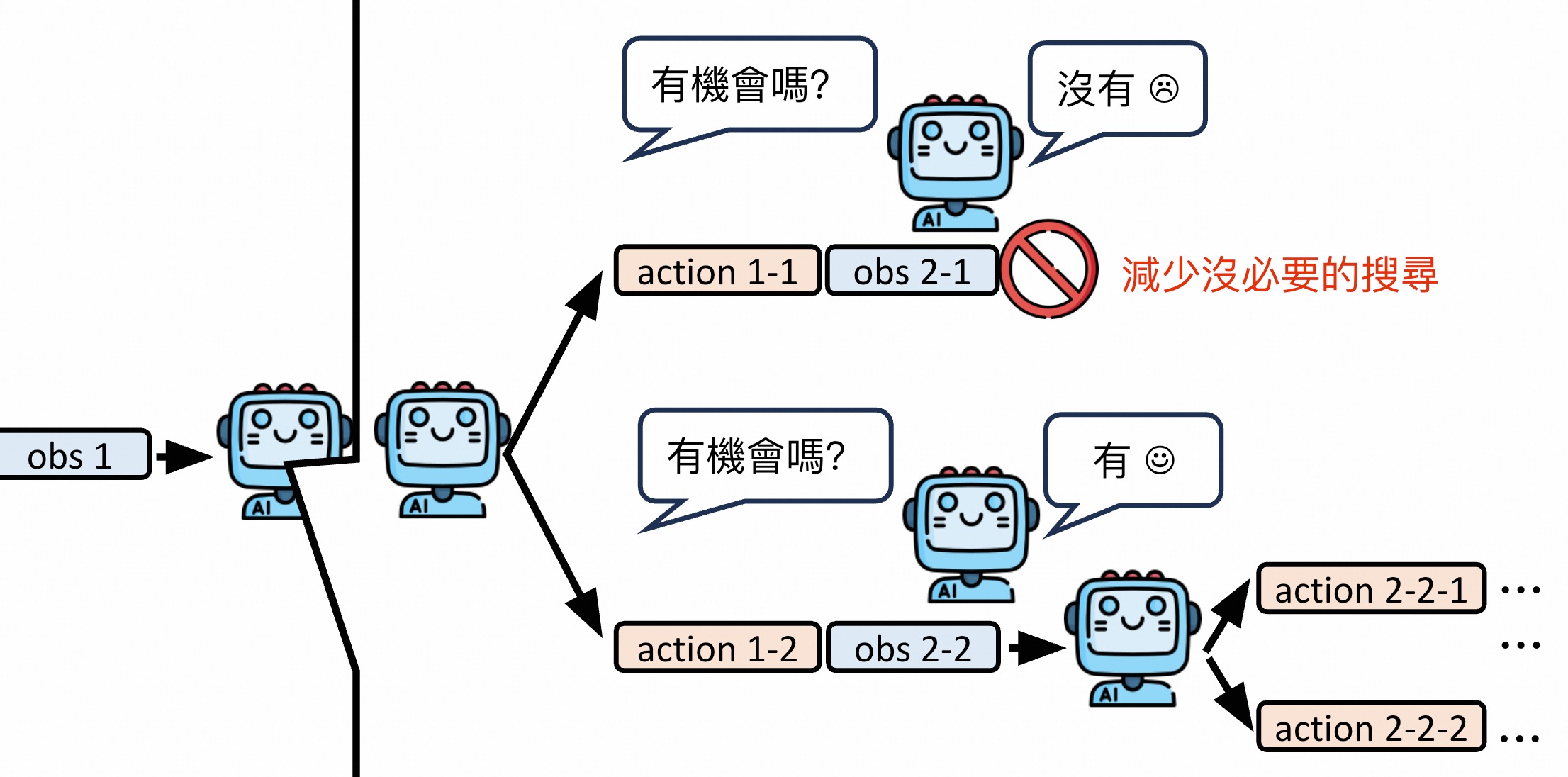
3、提前脑补,模拟环境交互
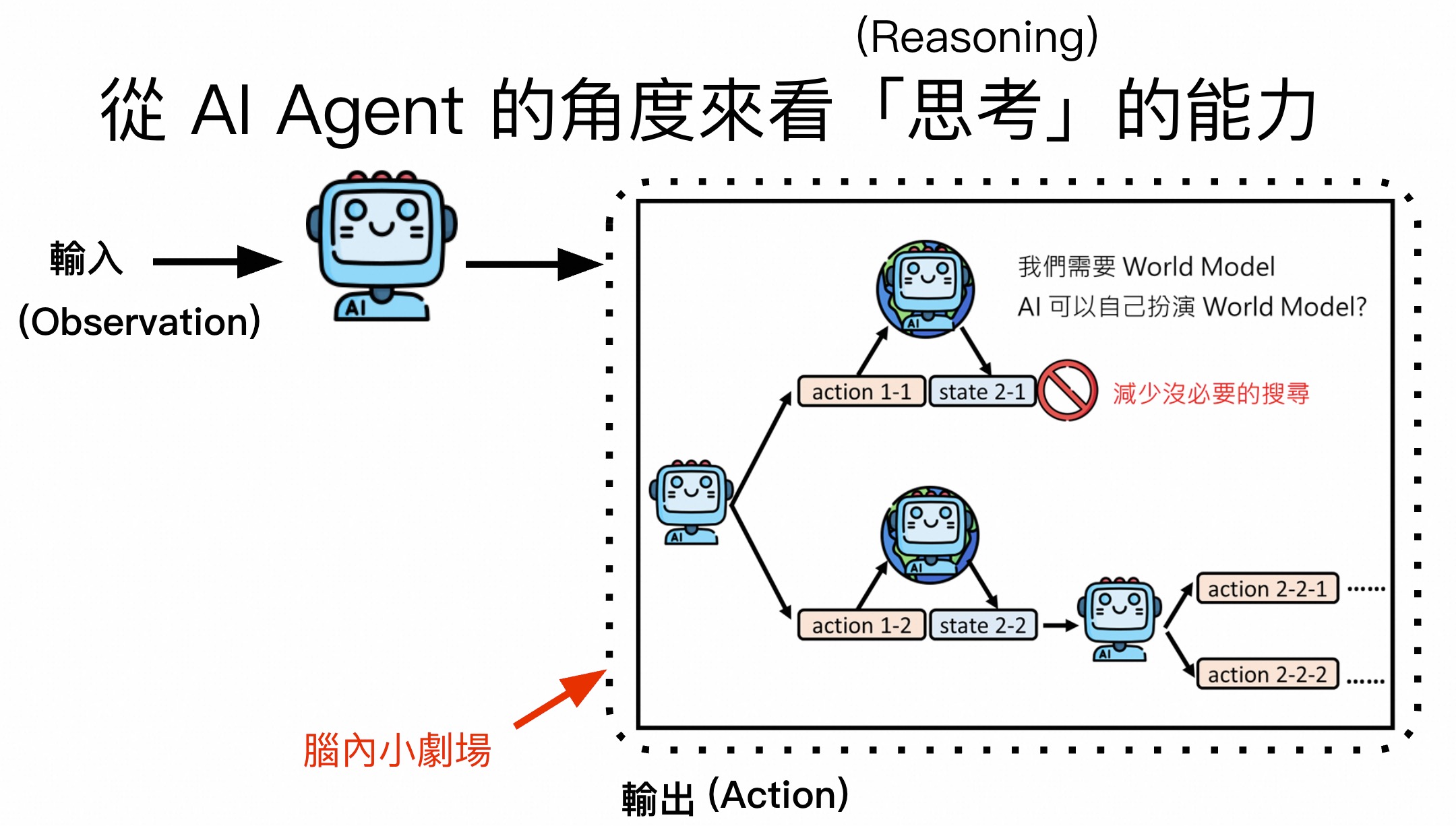
4、推理模型
但存在overthinking的问题,想太多
5、优化Overthiking