Computer-Agent
📅 发表于 2025/06/05
🔄 更新于 2025/06/05
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
computer-agent
#GUI
#CUA
❓问题背景
如预测红色圈圈⭕️位置:

SFT 🆚 GRPO 方法

📕核心方法
GRPO训练 🏃
<think></think>\n<answer></anser>GUI 数据集 📚
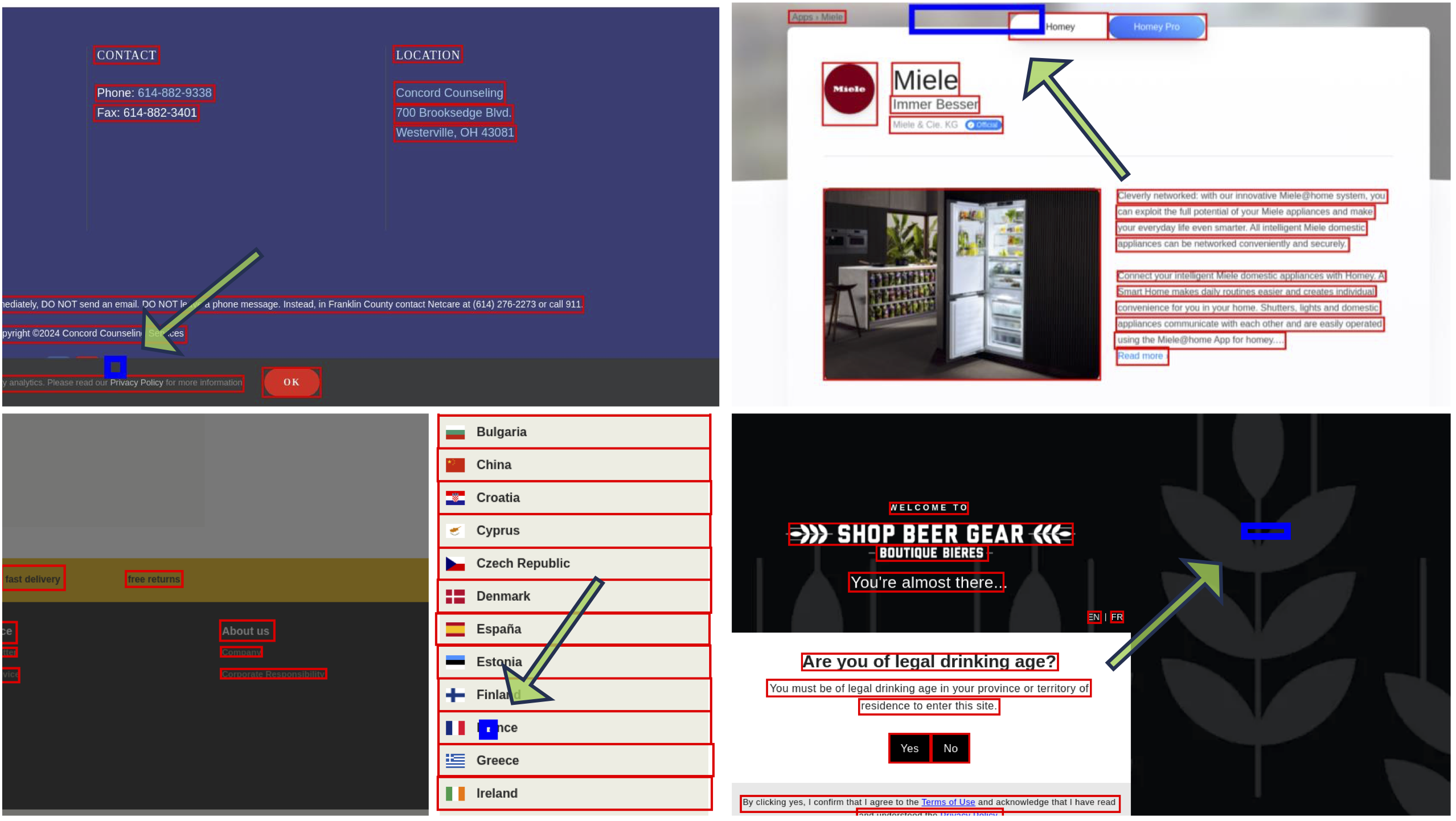
Mobile、Desktop(win桌面)、Web(浏览器界面)。数据清洗示例
✍️实验设置
1e-6通常都不错。🍑关键结果
⛳未来方向
❓问题背景
📕核心方法
Holo1,采用纯视觉方案-网页截图,模仿人类感知交互,具有更好鲁棒性和通用性。
3️⃣个训练模块 💡
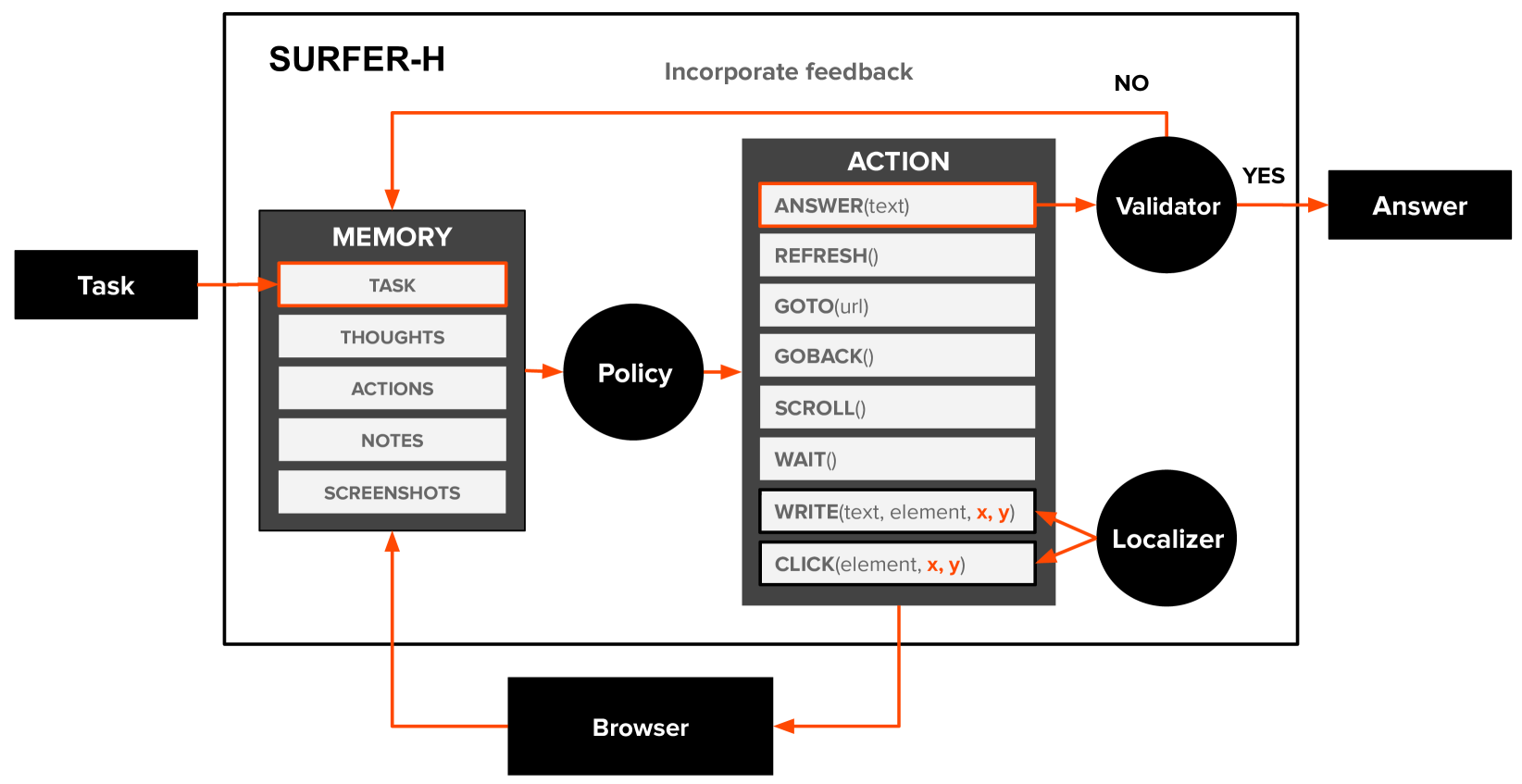
Holo1架构如下:
三大训练数据📚 ,总计31.46B tokens,有深度有广度)
1、GUI Grounding (51%):认识世界、打造AI鼠标
2、Complex Visual Understanding (32%):复杂视觉理解场景
3、Behavior Learning (17%):模仿成功经验来行动和判断
✍️实验设置
🍑关键结果
⛳未来方向