🧱 基础建设
🔄 强化学习
🌟 行业方向
🏹 领域任务
🤖 Agent
📦 其他
🧩 刷题
⚙️ 配置
🧘 心得
🗣️ NLP
🧬 基础理论
🧮 算法专栏
☕ 其他
Appearance
❓问题背景
📕核心方法
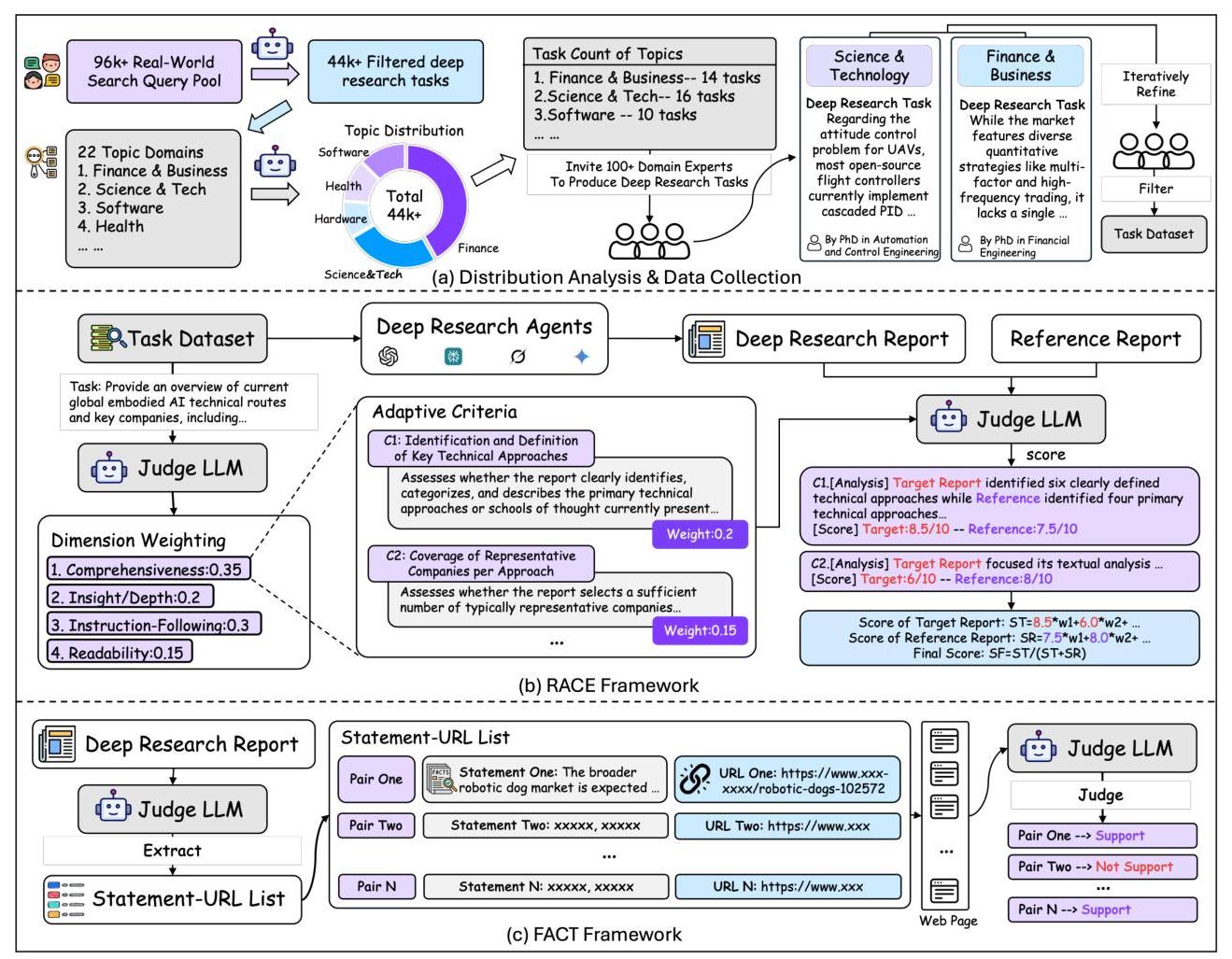
整体上:提出核心评估框架,包括22个领域、100+博士级研究任务,以及2种和人类高度一致的评估方法。
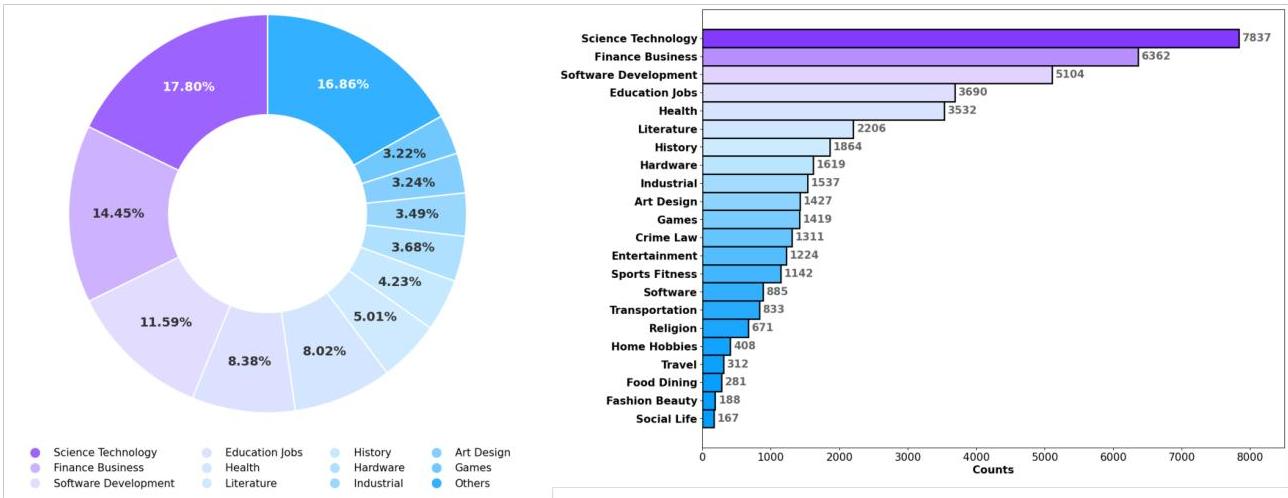
数据集:
✍️实验设置
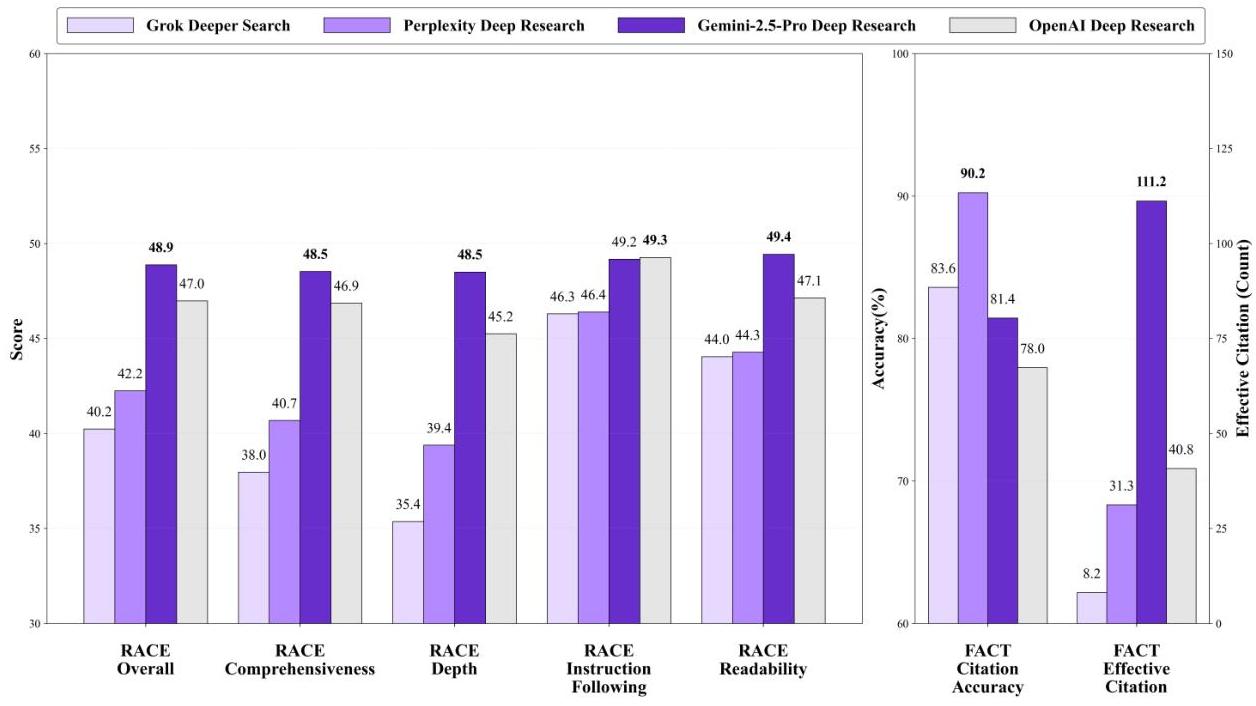
🍑关键结果
⛳未来方向