SVM笔记
📅 发表于 2018/03/02
🔄 更新于 2018/03/02
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
机器学习
#SVM
#机器学习
#拉格朗日对偶性
#对偶问题
#支持向量
#核函数
#感知机
#损失函数
Support Vector Machine简单笔记。 特征空间上的间隔最大的线性分类器。学习策略是间隔最大化,转化为一个凸二次规划问题的求解。
逻辑回归的图像和公式如下,预测的分类为1的概率。
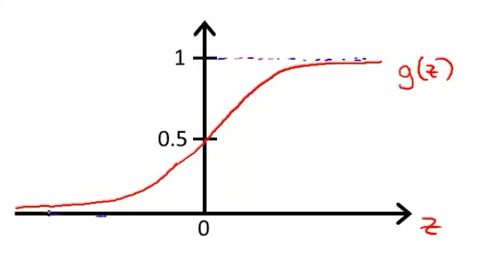 $$ h_\theta(x) = g(\theta^Tx), \quad g(z) = \frac{1}{1+e^{-z}}, \quad g(z) = \begin{cases} 1, & z\ge 0 \\ -1, & z < 0 \\ \end{cases} $$
$$ h_\theta(x) = g(\theta^Tx), \quad g(z) = \frac{1}{1+e^{-z}}, \quad g(z) = \begin{cases} 1, & z\ge 0 \\ -1, & z < 0 \\ \end{cases} $$ 其中超平面。 用分类函数表示
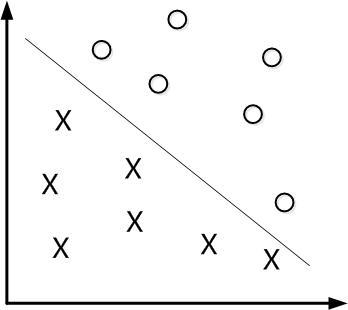
即对于任意一个x,有如下预测类别:
函数间隔
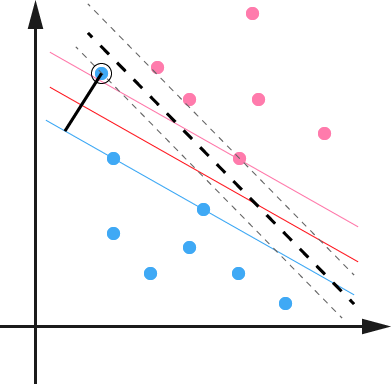
超平面距离,表示分类可靠性。距离越远,分类越可信。符号的一致性表示分类的正确性。
超平面
超平面关于所有样本点的函数间隔
函数间隔的问题:w和b成比例改变,超平面未变,但函数间隔已变。
几何间隔
对函数间隔除以法向量的二范数,则得到超平面与点
超平面关于所有样本点的几何间隔:
几何间隔才是直观上点到超平面的距离。
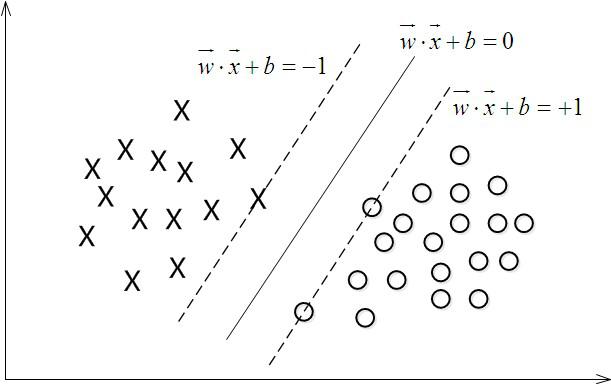
分类时,超平面离数据点的间隔越大,分类的确信度也越大。 所以要最大化这个几何间隔,目标函数如下:
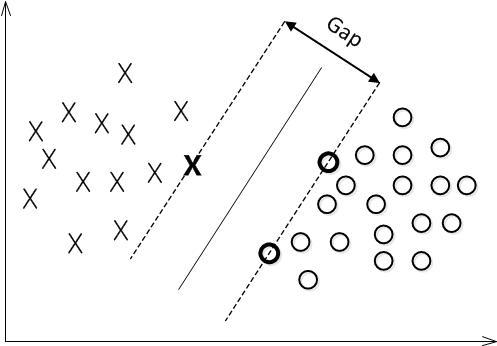
用函数间隔
函数间隔
目标函数
取函数间隔为1,
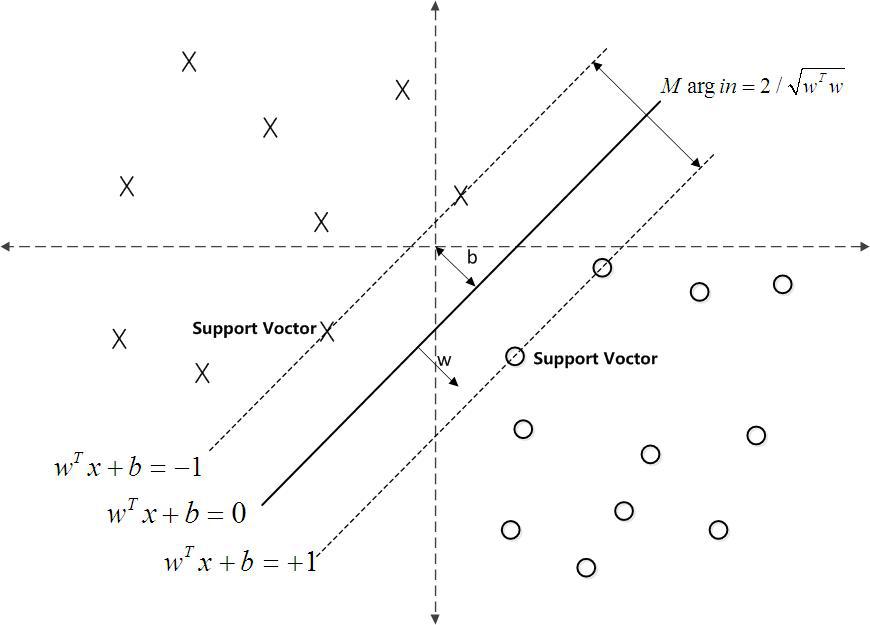
支持向量是虚线边界上的点,则有:
分类
1 原始问题
最优化:
有很多个约束条件(不等式约束和等式约束):
求解原始问题
将约束问题无约束化。
引入拉格朗日函数,其中
定义关于
原始问题: 先固定x,优化出参数
所以原始最优化问题 变为 拉格朗日函数的极小极大问题。
定义原始问题的最优解
2 对偶问题
定义关于
对偶问题:先固定参数
原始问题: 先固定x,优化出参数
定义对偶问题的最优值:
3 原始问题与对偶问题的关系
因为:
定理1:如果原始问题与对偶问题均有最优值,则有:
推论1:如果
通过对偶问题,来解决原始问题。
4 KKT条件
满足什么条件,才能使
首先满足下面的大条件:
假设
和 都是凸函数, 是仿射函数;假设不等式约束 是严格可行的。
定理2:则存在解,
KKT条件:则充分必要条件是**
由KKT对偶互补条件可知,若
若
先前的目标函数:
最大变为最小,则有原始问题如下。目标函数是二次的,约束条件是线性的。所以是个凸二次规划问题。
构造拉格朗日函数 :
原始问题
对偶问题
我们知道
拉格朗日函数:
化简后:
目标函数:
主要是三个步骤:
**1 极小求出w和b
对w和b求偏导,使其等于0。
特别地范式求导:
把上面两个结论,带入原式进行化简,得到:
得到只用
2 求出对
对偶问题 如下:
目标函数:
约束条件:
利用SMO算法求出拉格朗日乘子
3 求出w和b,得到分离超平面和决策函数
根据前面的公式得到**
选一个**
得到**
通过公式可以看出,决定w和b的是支持向量, 其它点对超平面是没有影响的。
分离超平面
分类决策函数
目标函数
拉格朗日函数
转化为对偶问题求解, 需要会求解过程、会推导公式。
主要是下面4个求解步骤:十分重要!!!
SMO求出求导后消去w和b,得到L
利用SMO求得
实际上最重要是向量内积来进行决策
目标函数
两种数据点
问题
大部分数据不是线性可分的,前面的超平面根本不存在。可以用一个超曲面进行分离,这就是非线性可分问题。
SVM可以通过核函数把输入映射到高维特征空间,最终在高维特征空间中构造最优分离超平面。
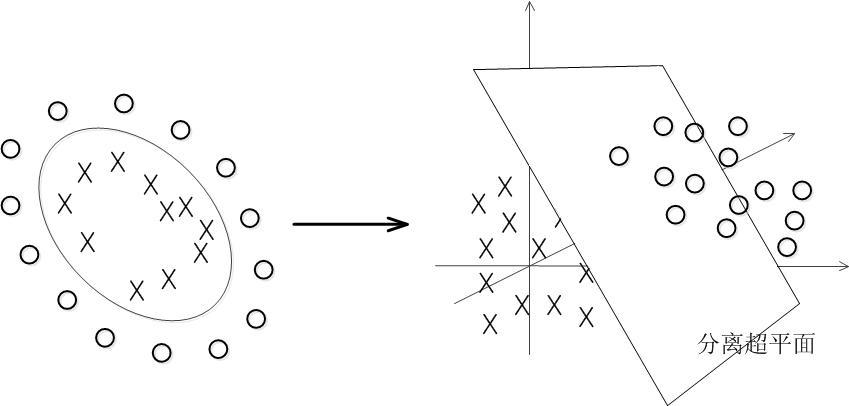
需要映射和学习线性SVM:
映射到特征空间F线性学习器分类核函数的功能
核函数在特征空间中直接计算内积,就像在原始输入点的函数中一样,两个步骤合二为一:
分类函数:
对偶问题:
简单例子

上面的数据线性不可分,两个维度(a, b)。 应该用二次曲线(特殊圆)来区分:
看做映射到了五维空间:
如下图:(实际映射到了三维空间的图),可以使用一个平面来分开:
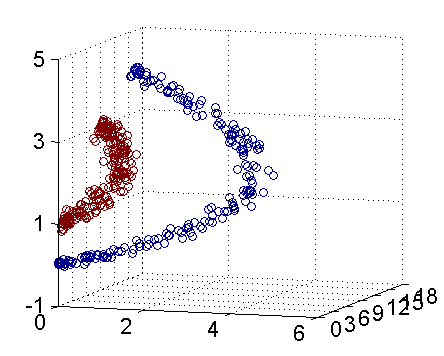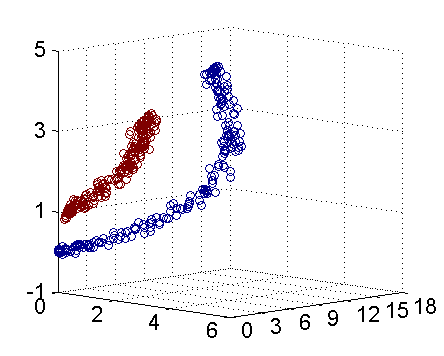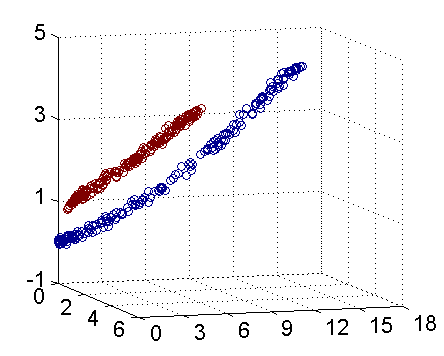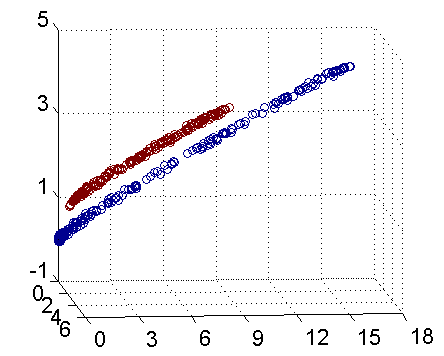
问题
五维是由1维和2维进行组合,就可以解决问题。所以对输入数据无脑组合映射到高维可以吗?当然是不可以的。维数太高,根本没法计算,不能无脑组合映射。
核函数的功能
看核函数:
核函数和上面映射空间的结果是一样的!区别:
核函数:直接在原来的低维空间中计算,而不需显示写出映射后的结果。避开了在高维空间中的计算!1 线性核
目的:映射前和映射后,形式上统一了起来。写个通用模板,再带入不同的核就可以了。
2 高斯核
高斯核函数,非常灵活,应用很广泛。可以映射到无穷维。
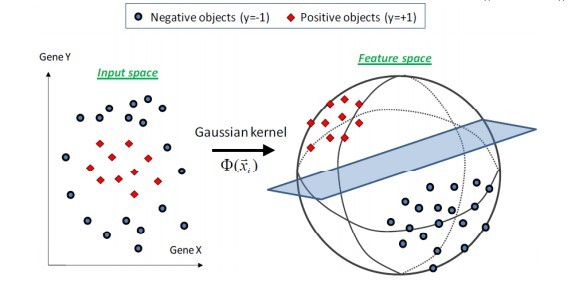
3 多项式核
问题的出现
核函数的功能
SVM曲线,逻辑回归和决策树是直线。SVM的效果好。
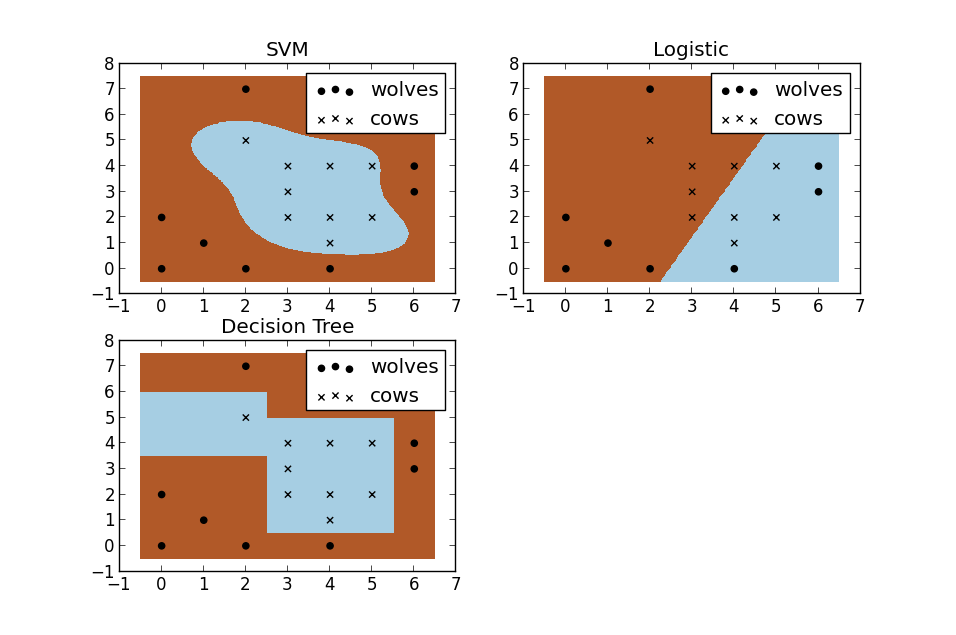
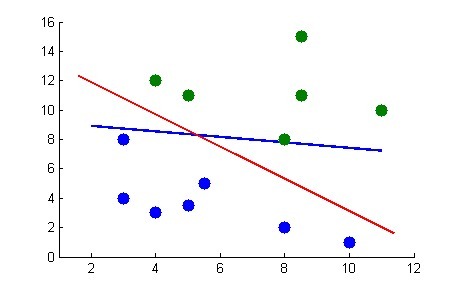
数据可能有一些噪声特异点outlier导致不是线性可分或者效果不好。 如果不处理outlier,则会非常影响SVM。因为本身支持向量就只有几个。
给每个数据点加上松弛变量
为每个松弛变量
惩罚系数C是一个常数
定义新的拉格朗日函数:
和前面对偶问题求解一样,求导求解:
带入,得到新的L
约束条件:
感知机算法是一个二类分类的线性模型,也是找一个超平面进行划分数据:
损失函数是所有误分类点到超平面的总距离:
可以使用SGD对损失函数进行优化。
当训练数据集线性可分时,感知机算法是收敛的。可以在一定迭代次数上,找到一个超平面,有很多个解。
感知机的超平面不是最优效果,最优是SVM。
数据
常见损失
平方损失
绝对损失
对数损失
期望损失
期望损失也称为风险函数,需要知道联合概率分布
经验损失
经验损失也成为经验风险 ,所以监督学习就是要经验风险最小化。
结构风险最小化
样本数量太小时,容易过拟合。需要加上正则化项,也称为惩罚项。 模型越复杂,越大。
权衡经验风险和模型复杂度。 监督学习,就是要使结构风险最小化。
SVM也是最优化+损失最小。 可以从损失函数和优化算法角度去看SVM、boosting、LR,可能会有不同的收获。
从最优化+损失最小的角度去理解SVM。
最小二乘法,就是通过最小化误差的平方来进行数学优化。对参数进行求偏导,进行求解。
模型
序列最小最优化SMO (Sequential minimal optimization),解决求解
如果所有变量的解都满足KKT条件,则最优化问题的解已经得到。
思想
每次抽取两个乘子
选择乘子