马尔可夫模型
📅 发表于 2017/08/04
🔄 更新于 2017/08/04
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#概率图模型
#自然语言处理
#马尔可夫链
#隐马尔科夫模型
#维特比算法
#前向算法
#后向算法,BW算法
本文包括概率图模型、马尔科夫模型和隐马尔可夫模型。重点是HMM的前后向算法、维特比算法和BW算法
判别方法 由数据直接去学习决策函数
或者 作为预测模型 ,即 判别模型
生成方法 先求出联合概率密度
,然后求出条件概率密度 。即 生成模型
| 判别式 | 生成式 | |
|---|---|---|
| 原理 | 直接求 | 先求 |
| 差别 | 只关心差别,根据差别分类 | 关心数据怎么生成的,然后进行分类 |
| 应用 | k近邻、感知机、决策树、LR、SVM | 朴素贝叶斯、隐马尔可夫模型 |
概率图模型(probabilistic graphical models) 在概率模型的基础上,使用了基于图的方法来表示概率分布。节点表示变量,边表示变量之间的概率关系
概率图模型便于理解、降低参数、简化计算,在下文的贝叶斯网络中会进行说明。
贝叶斯网络 又称为信度网络或者信念网络(belief networks),实际上就是一个有向无环图。
节点表示随机变量;边表示条件依存关系。没有边说明两个变量在某些情况下条件独立或者说是计算独立,有边说明任何条件下都不条件独立。
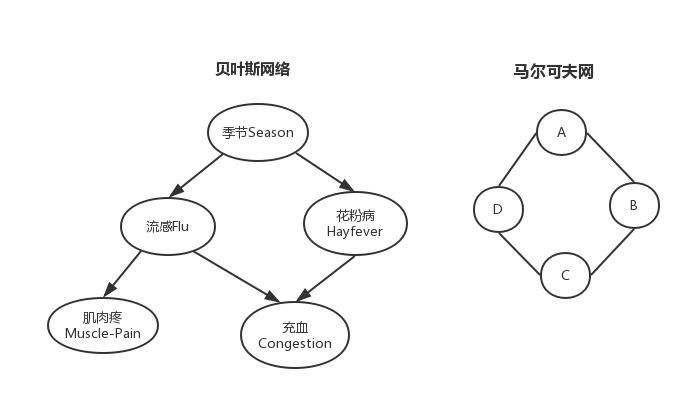
如上图所示,要表示上述情况的概率只需要求出
所以我们得到如下的计算独立假设:
又由
所以联合概率密度就转化成了上述公式中的5个乘积项,其中每一项需要的参数个数分别是2、4、4、4、3,所以一共只需要17个参数,这就大大降低了参数的个数。
马尔可夫模型(Markov Model) 描述了一类重要的随机过程,未来只依赖于现在,不依赖于过去。这样的特性的称为马尔可夫性,具有这样特性的过程称为马尔可夫过程。
时间和状态都是离散的马尔可夫过程称为马尔可夫链,简称马氏链,关键定义如下
一般地,系统在时间
在时刻转移概率,即从时刻
如果n步转移概率。 并且称此转移概率具有平稳性,且称此链是齐次的,称为齐次马氏链,我们重点研究齐次马氏链。n步转移矩阵。
特别地,一步转移概率如下
特别地,如果**离散的一阶马尔可夫链如下:
其中
显然,状态转移矩阵。
设系统在初始状态的概率向量是
那么时间序列
下图是一个例子
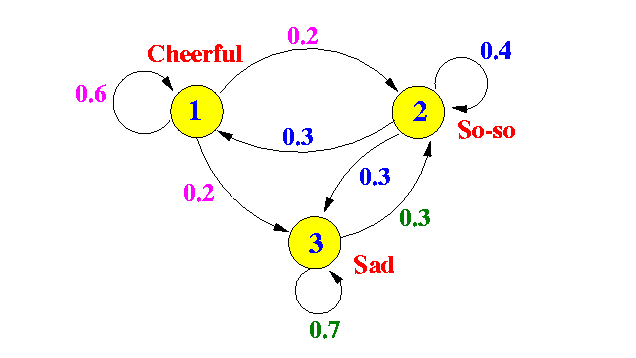
对于齐次马氏链,多步转移概率就是CK方程的矩阵形式
由此得到
对于求矩阵的幂相似对角化来进行矩阵连乘。
存在一个可逆矩阵P,使得
则有
齐次马氏链,状态遍历性。若极限分布。
遍历性的充分条件:如果存在正整数
那么它的极限分布
有很多应用,压缩算法、排队论等统计建模、语音识别、基因预测、搜索引擎鉴别网页质量-PR值。
Page Rank算法
这是Google最核心的算法,用于给每个网页价值评分,是Google“在垃圾中找黄金”的关键算法。
大致思想是要为搜索引擎返回最相关的页面。页面相关度是由和当前网页相关的一些页面决定的。
当前页面会把自己的importance平均传递给它所指向的页面,若有
如果有很多页面都指向当前页面,则当前页面很重要,相关度高
当前页面有一些来自官方页面的backlink,当前页面很重要
例如有4个页面,分别如下
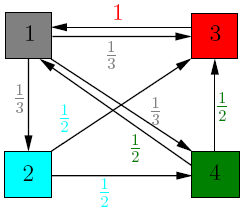
矩阵PageRank vector。
定义矩阵
使用
那么通过迭代就可以求出PR向量
迭代具体计算如下图(下图没有使用G,是使用A去算的,这是网上找的图[捂脸])
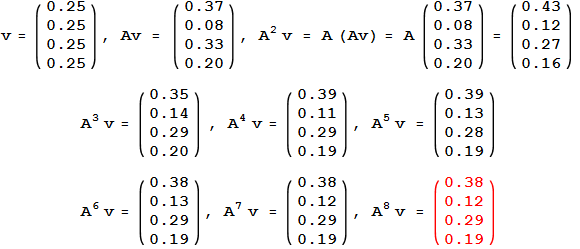
随着迭代,PageRank vector。
我们知道节点1有2个backlink,3有3个backlink。但是节点1却比3更加相关,这是为什么呢?因为节点3虽然有3个backlink,但是却只有1个outgoing,只指向了页面1。这样的话它就把它所有的importance都传递给了1,所以页面1也就比页面3的相关度高。
隐马尔可夫模型(Hidden Markov Model, HMM)是统计模型,它用来描述含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来做进一步的分析。大概形状如下
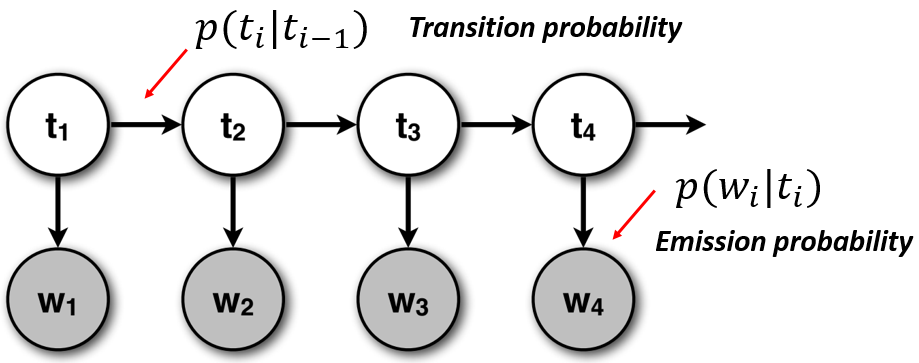
一个HMM由以下5个部分构成。
隐藏状态
模型的状态,隐蔽不可观察隐状态时间序列 观察状态
显状态时间序列 状态转移矩阵A (隐--隐)
发射概率矩阵B (隐--显)
初始状态概率分布
一般地,一个HMM记作一个五元组
HMM中的三个问题
观察序列概率 给定观察序列状态序列概率 给定观察序列训练问题或参数估计问题 给定观察序列给定观察序列解码问题。如果直接去求,计算量会出现指数爆炸,那么会很不好求。我们这里使用前向算法和后向算法进行求解。
前向算法
前向变量
接下来就是计算
上述计算,其实是分为了下面3步
算法的步骤如下
在每个时刻
后向算法
后向变量
递推
上面的公式个人的思路解释如下(不明白公式再看)
上式是把所有从
前后向算法结合
模型
推导过程如下
所以,把
维特比(Viterbi)算法用于求解HMM的第二个问题状态序列问题。即给定观察序列
有两种理解最优的思路。
维特比变量
递推关系
路径记忆变量
维特比算法步骤
初始化
归纳计算
维特比变量
记忆路径(记住参数
终结
路径(状态序列)回溯
Baum-Welch算法用于解决HMM的第3个问题,参数估计问题,给定一个观察序列
有完整语料库
如果我们知道观察序列最大似然估计去计算HMM的参数。
设
但是一般情况下是不知道隐藏状态序列
我们可以给定初始值模型
这种迭代爬山算法可以局部地使
Baum-Welch算法
给定HMM的参数
定义t时刻状态为
定义**
那么有算法步骤如下(也称作前向后向算法)
1初始化
随机地给参数
2EM步骤
2.1E步骤 使用模型
2.2M步骤 用上面算得的期望去估计参数
3循环计算 令