最大期望算法
📅 发表于 2017/08/14
🔄 更新于 2017/08/14
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
机器学习
#机器学习
#最大期望算法
#Jensen不等式
本文简单记录了EM算法的思想和Jensen不等式
如果概率模型的变量都是观测变量,那么可以直接使用极大似然估计法或贝叶斯估计法去估计模型参数。
如果模型既有观测变量又有隐变量,就不能简单使用上述方法。
EM算法,期望极大算法,就是含有隐变量的概率模型参数的极大似然估计法或极大后验概率估计法,是一种迭代算法。每次迭代分为如下两步
有3枚硬币,记做ABC,每次出现正面的概率分别是
对于一次实验,求出
设观察序列
求模型参数
这个问题不能直接求解,只有通过迭代的方法求解。EM算法就是解决这种问题的一种迭代算法。先给
基本概念
一些概念如下
EM算法通过迭代求
概率论函数的期望
设
Q函数
下面是我具体的理解
求对数似然函数
把目标函数映射到
EM算法步骤
输入:
输出:模型参数
步骤
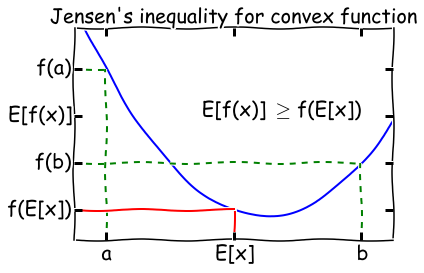
凸函数与凹函数
从图像上讲,在函数上两点连接一条直线。直线完全在图像上面,就是凸函数 convex;完全在下面,就是凹函数 concave。
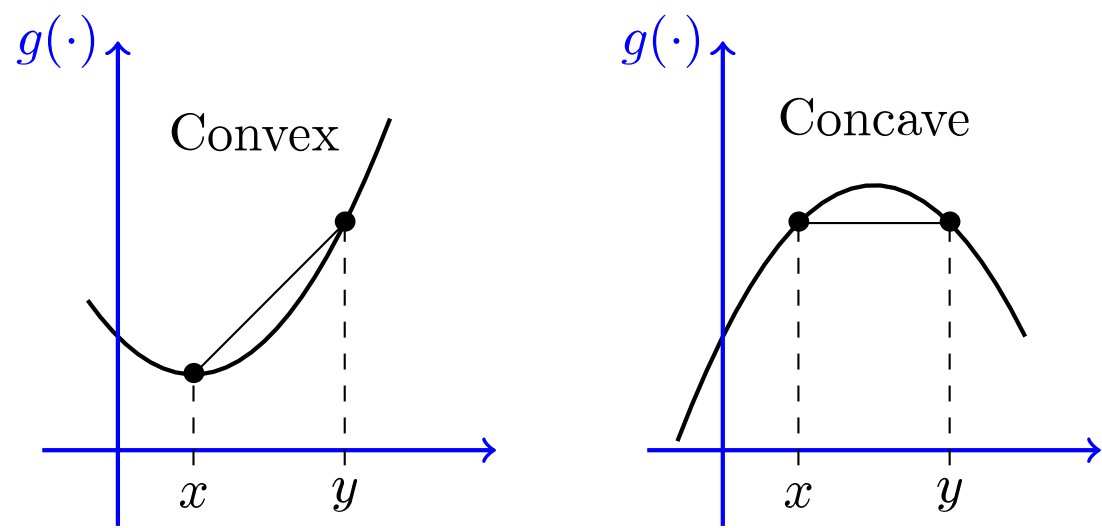
Jensen不等式
函数
一般地,
琴声不等式