线性回归和逻辑回归
📅 发表于 2017/08/21
🔄 更新于 2017/08/21
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
机器学习
#机器学习
#线性回归
#逻辑回归
#梯度下降
吴恩达线性回归、逻辑回归、梯度下降笔记
有
代价函数
目标是要找到合适的参数,去最小化代价函数
假设

假设有3个样本
那么回到最初的两个参数

基础说明
上文已经定义了代价函数梯度下降算法去最小化
当然选择不同的初始值,可能会得到不同的结果,得到局部最优解。
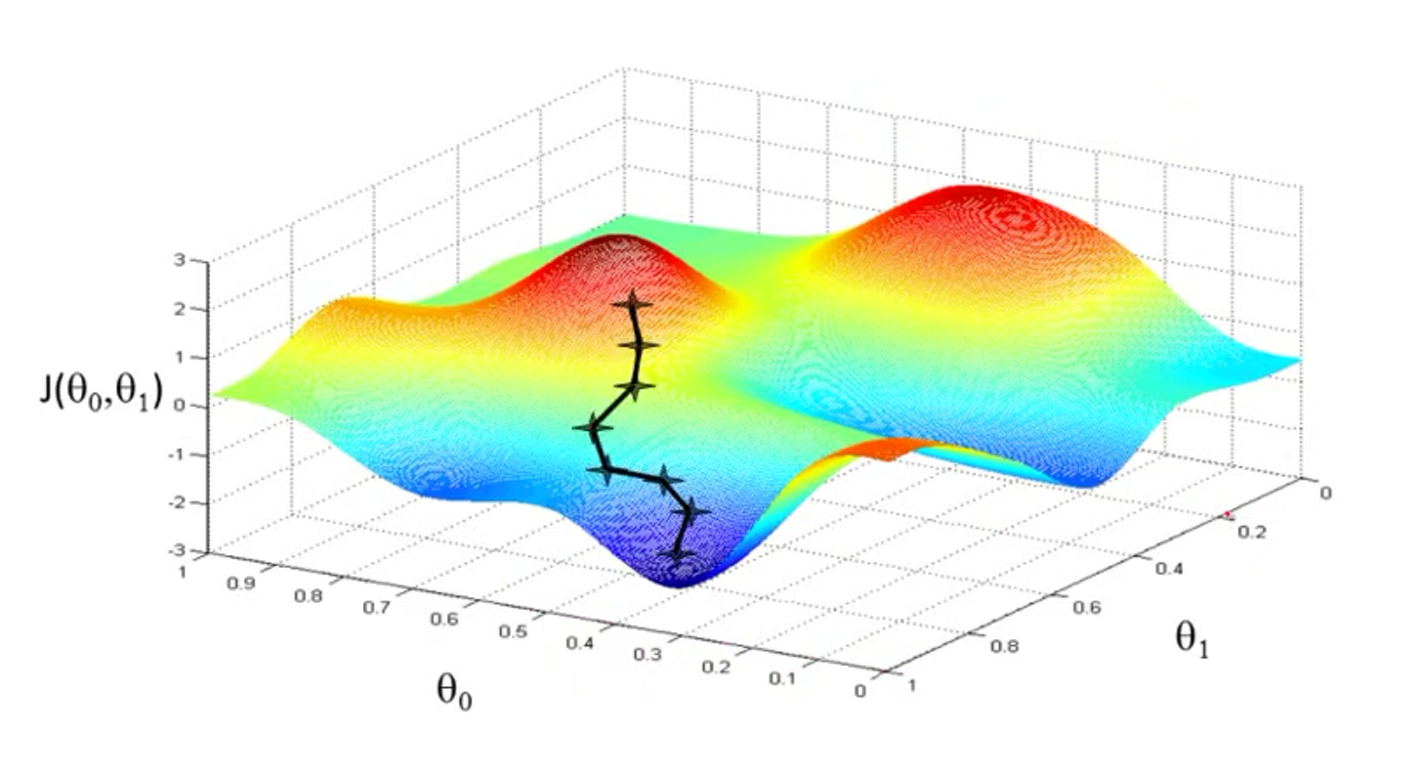
对于所有的参数
上面公式中学习率(learning rate),是指一次迈多大的步子,一次更新的幅度大小。
例如上面的两个参数,对于一次同步更新(梯度下降)
也有异步更新(一般指别的算法)
偏导和学习率
这里先看一个参数的例子,即
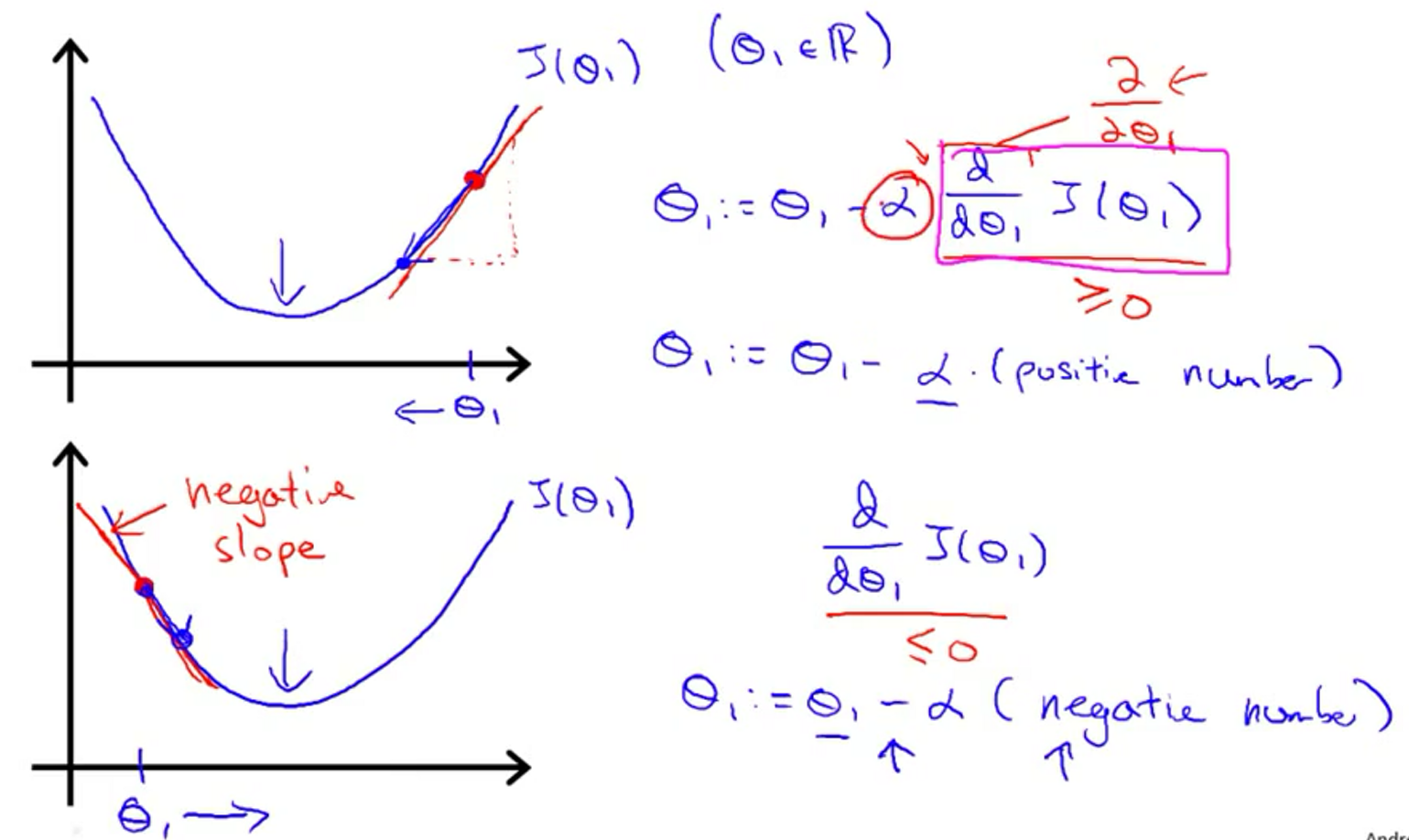
当学习率

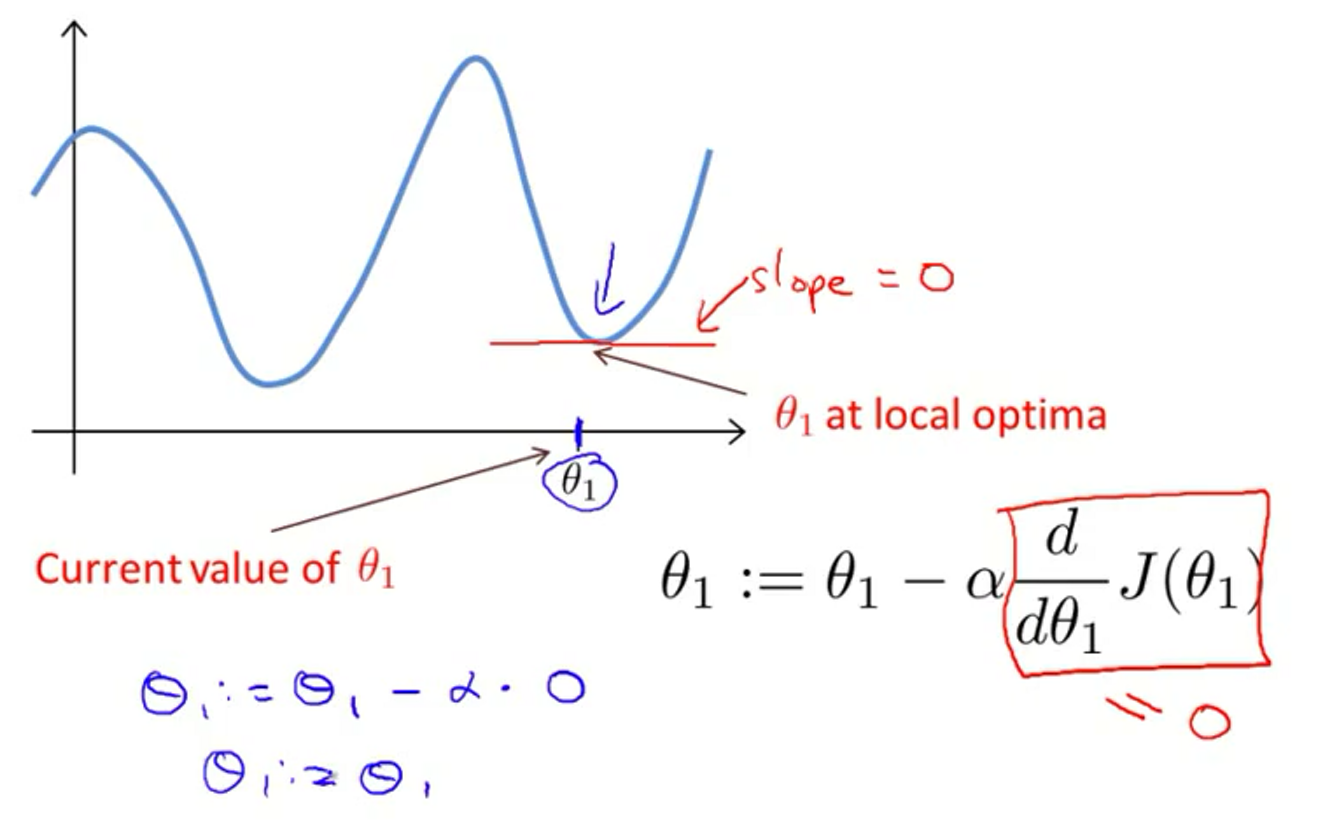
当已经处于局部最优的时候,导数为0,并不会改变参数的值,如下图
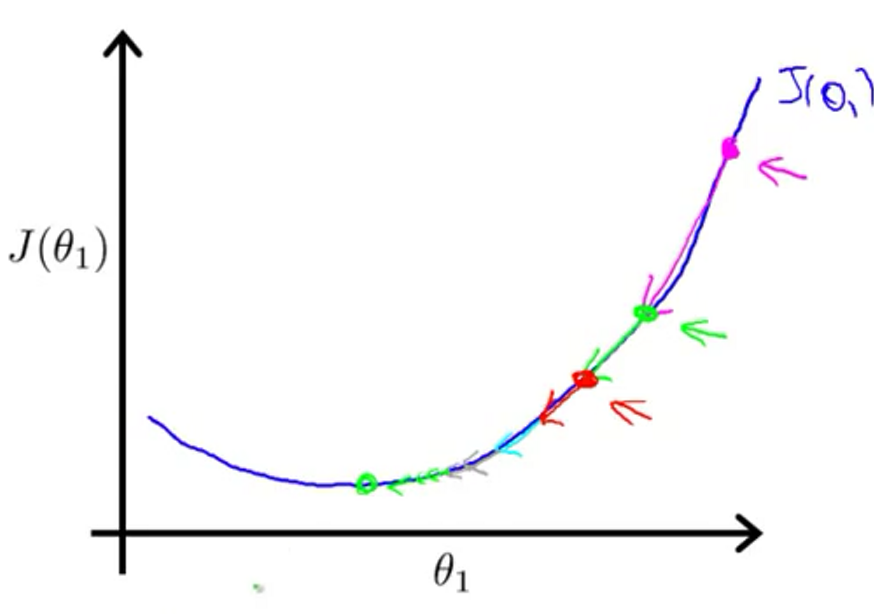
当逐渐靠近局部最优的时候,梯度下降会自动采取小步子到达局部最优点。是因为越接近,导数会越来越小。
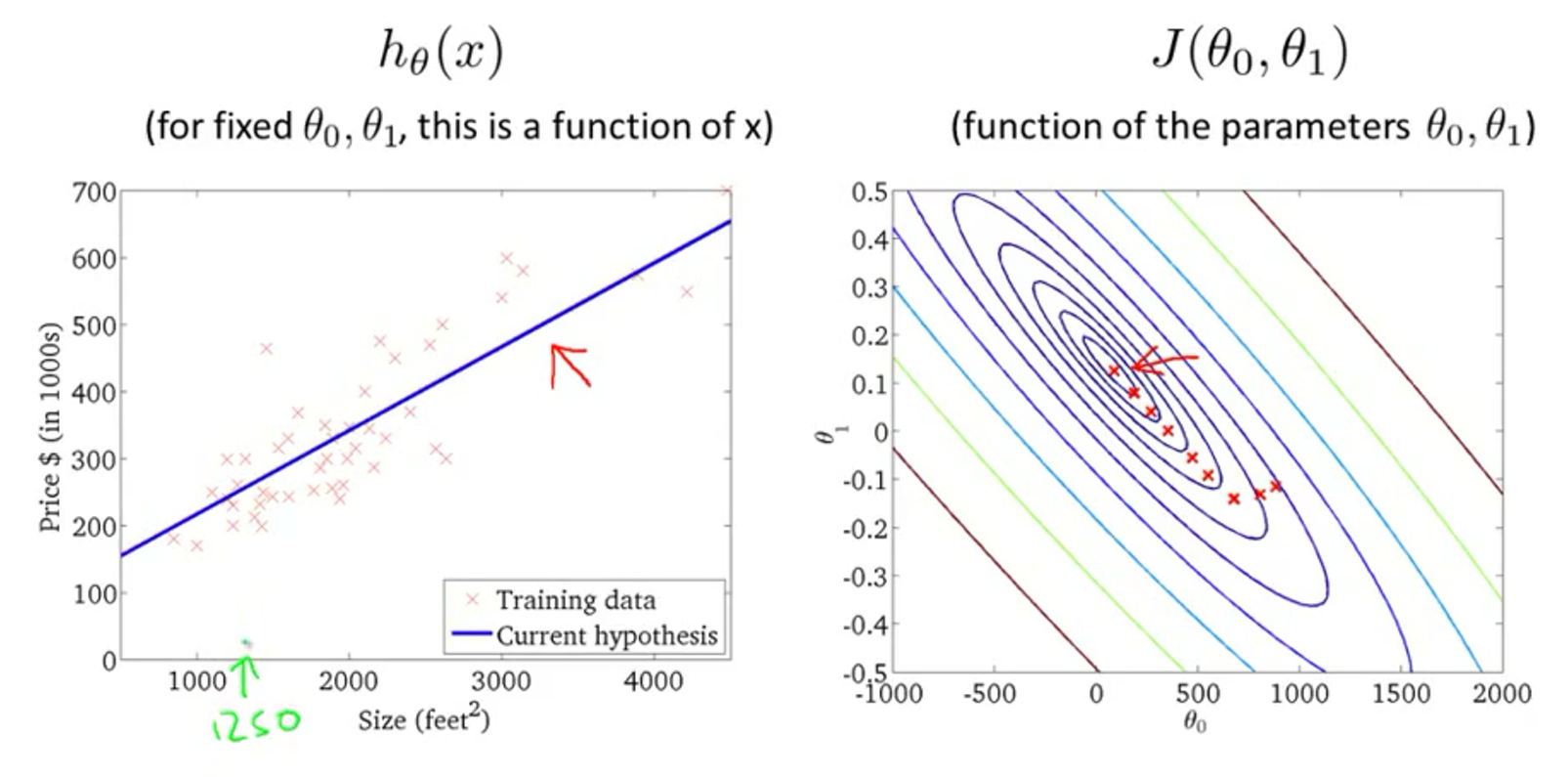
在线性回归上使用梯度下降
代价函数
分别对
那么使用梯度下降对
当前代价函数实际上是一个凸函数,如下图所示。它只有全局最优,没有局部最优。
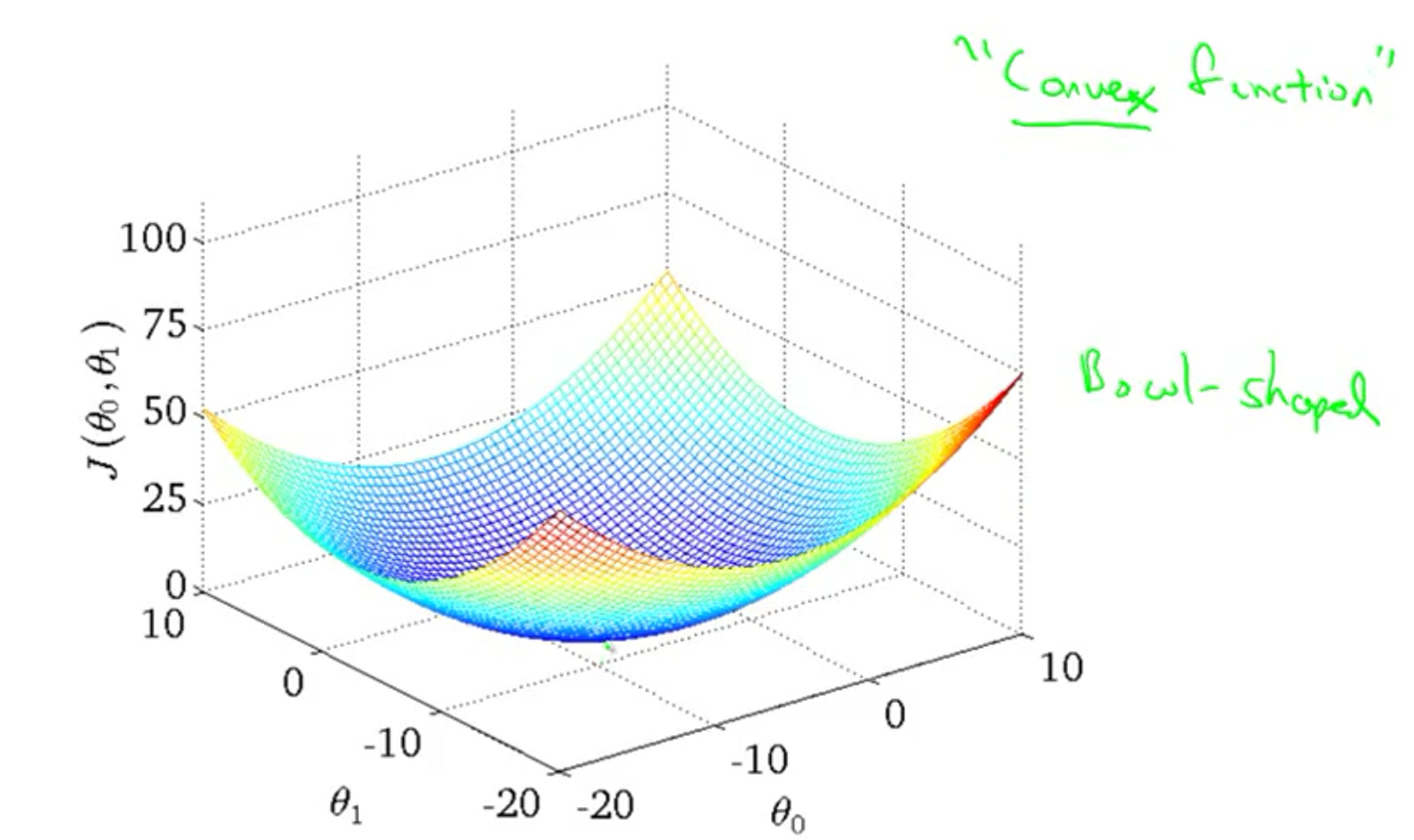
通过不断地改变参数减小代价函数
特征缩放
不同的特征的单位的数值变化范围不一样,比如
所以特征缩放是把所有的特征缩放到相同的规模上。得到的
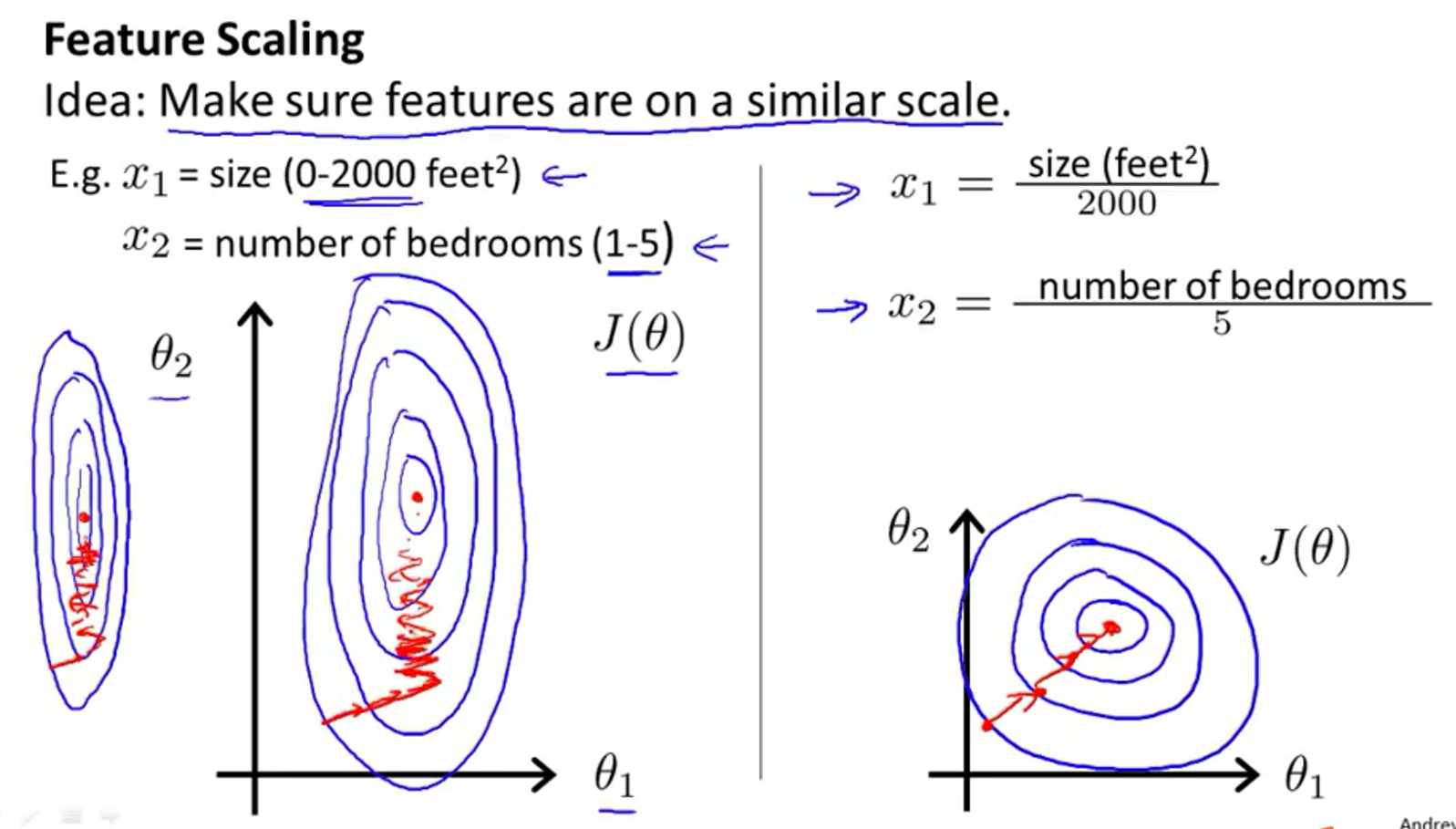
特征缩放的数据规模不能太小或者太大,如下面可以的规模是
有一些常见的缩放方法
学习率的选择
当梯度下降正确运行的时候,每一次迭代
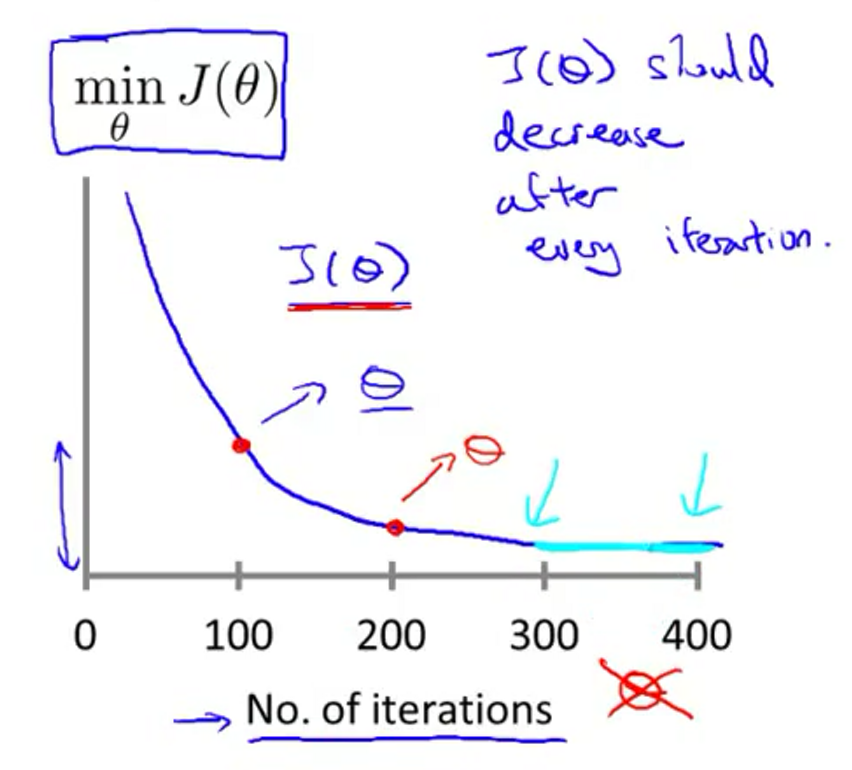
当图像呈现如下的形状,就需要使用更小的学习率。理论上讲,只要使用足够小的学习率,
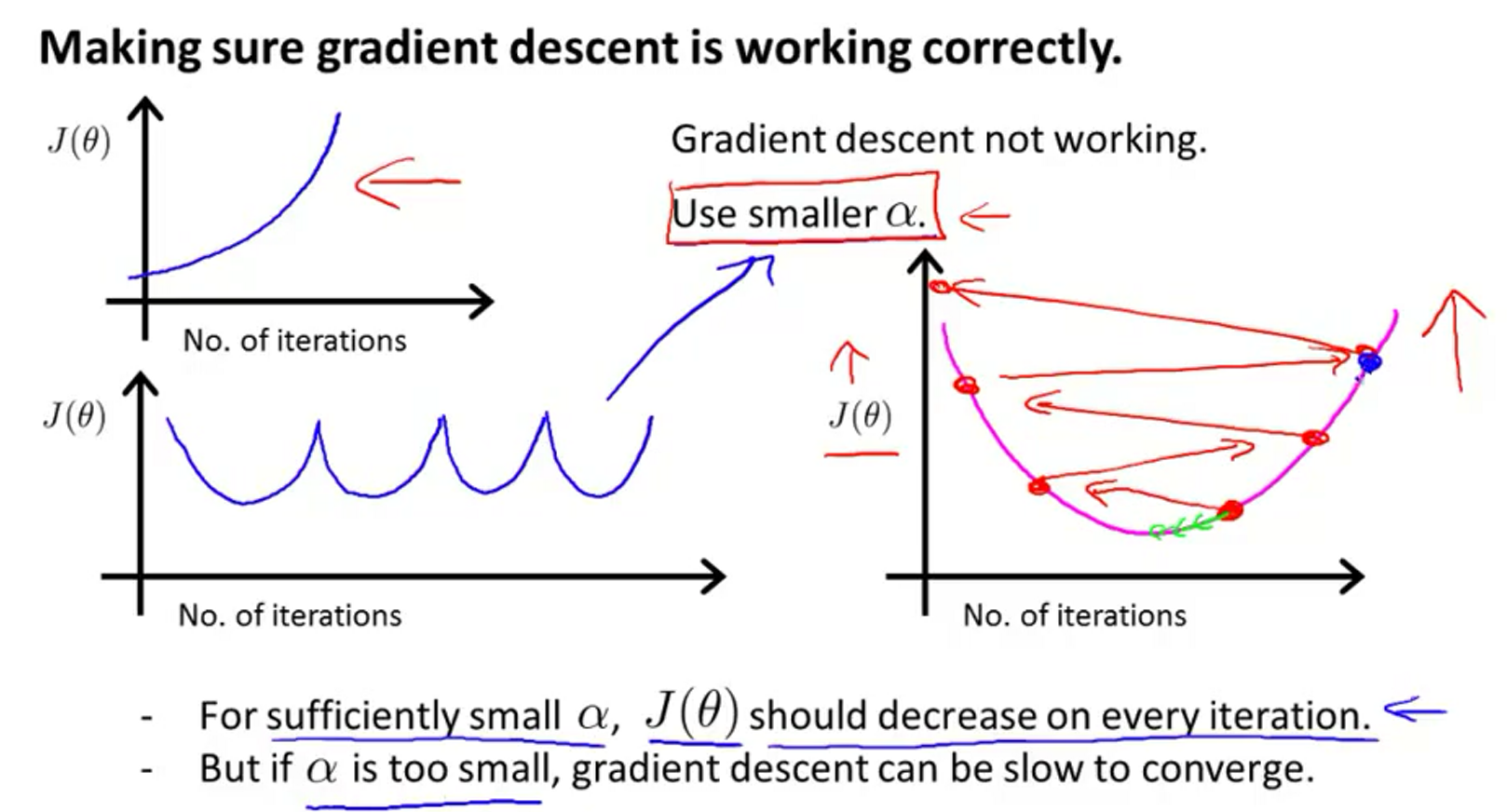
学习率总结
数据有
代价函数
梯度下降,更新每个参数
有时候,线性回归并不能很好地拟合数据,所以我们需要曲线来适应我们的数据。比如一个二次方模型
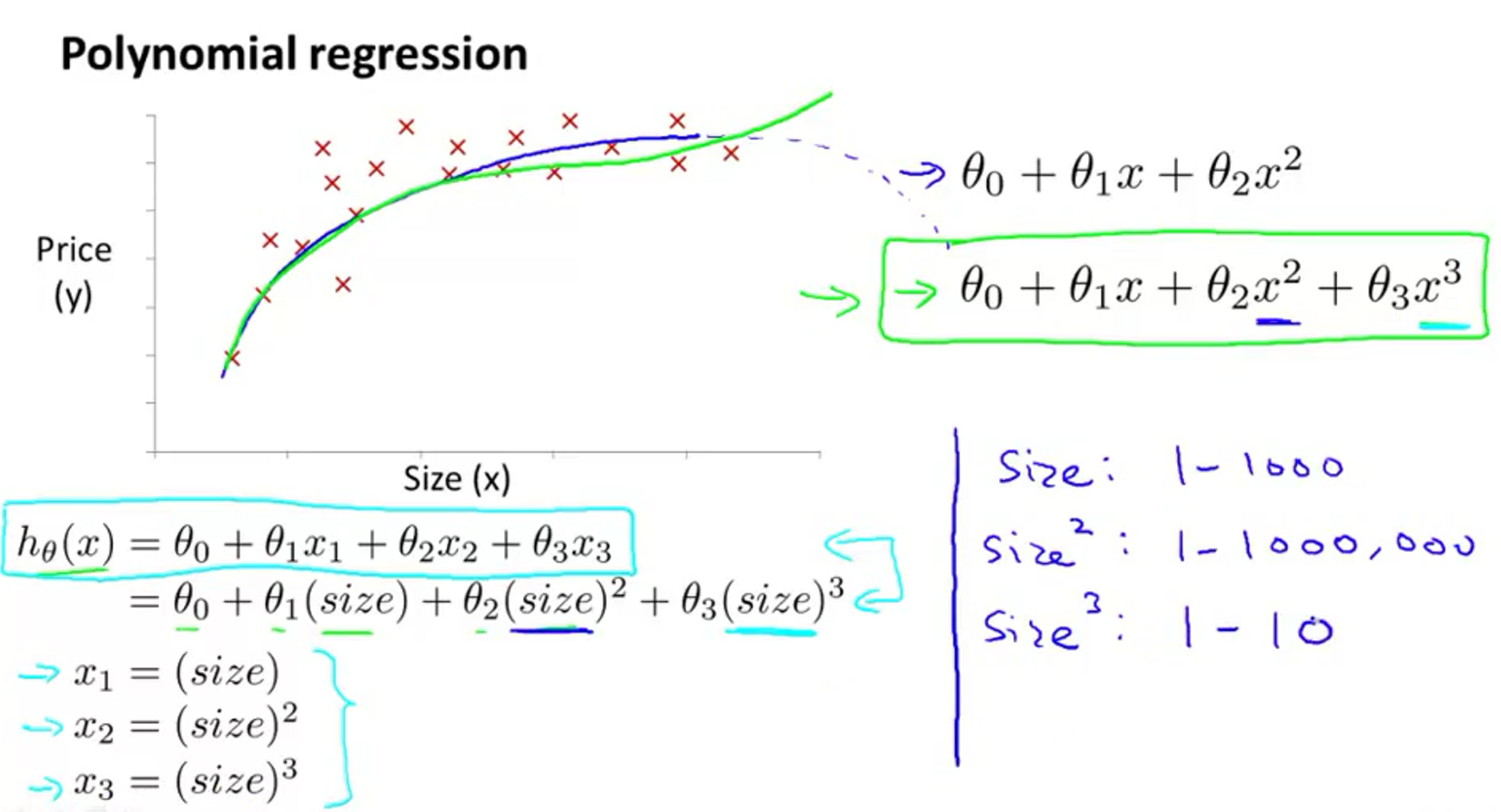
当然可以用
对于一些线性回归问题,使用正规方程方法求解参数
正规方程的思想是函数
那么设
正规方程和梯度下降的比较
| 梯度下降 | 正规方程 |
|---|---|
| 需要特征缩放 | 不需要特征缩放 |
| 需要选择学习率 | 不虚选择学习率 |
| 需要多次迭代计算 | 一次运算出结果 |
| 特征数量 | |
| 适用于各种模型 | 只适用于线性模型,不适合逻辑回归和其他模型 |
线性回归有2个不好的问题:直线难以拟合很多数据;数据标签一般是
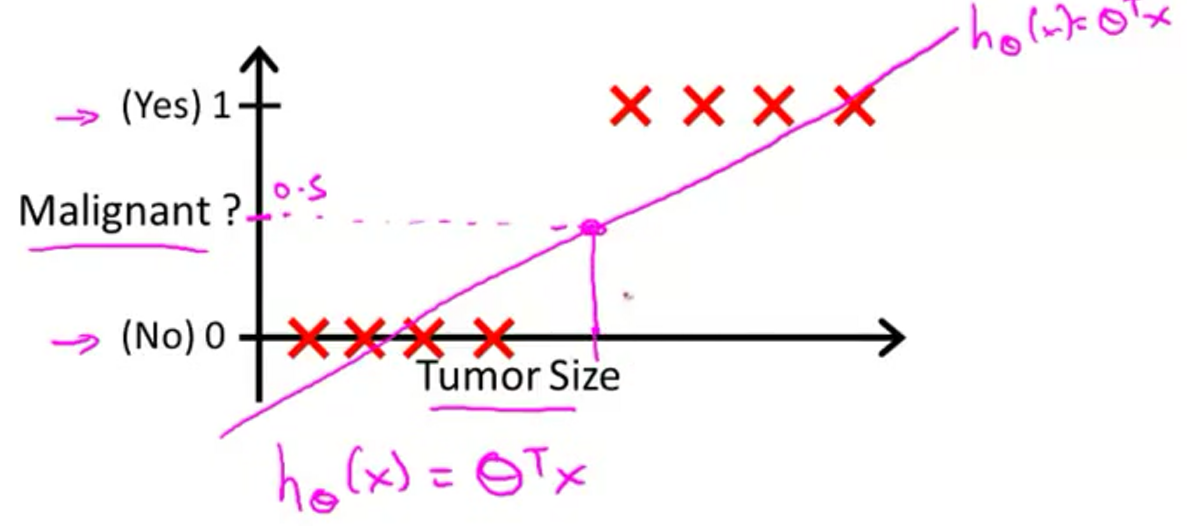
逻辑回归是一种分类算法,使得输出预测值永远在0和1之间,是使用最广泛的分类算法。模型如下
Sigmoid函数或者Logistic函数,是S形函数。
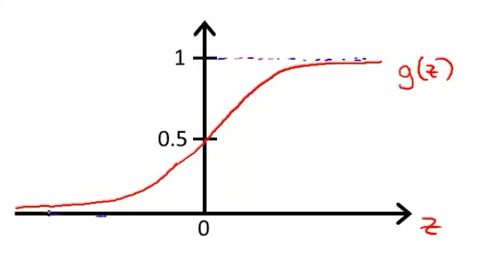
将上面的公式整理后得到逻辑回归的模型
模型的意义是给出分类为1的概率,即
逻辑回归就是要学到合适的
线性边界
假设我们有一个模型

由上可知,分类结果如下
那么直线决策边界,将预测为1的区域和预测为0的区域分隔开来。gg
非线性边界
先看下面的数据

使用这样的模型去拟合数据
对于更复杂的情况,可以用更复杂的模型去拟合,如
我们知道线性回归中的代价函数是非凸函数,容易达到局部收敛,如下图左边所示。而右边,则是一个凸函数,有全局最小值。

代价函数
逻辑回归的代价函数
当实际上
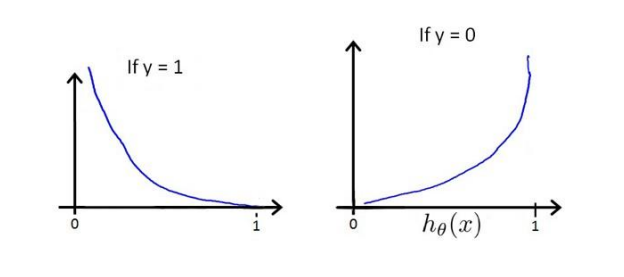
整理代价函数如下
得到所有的
梯度下降
逻辑回归的假设函数估计
代价函数
对每个参数
逻辑回归虽然梯度下降的式子和线性回归看起来一样,但是实际上