机器学习知识点汇总整理
📅 发表于 2018/03/04
🔄 更新于 2018/03/04
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
机器学习
#机器学习
一些机器学习的知识点总结
1 Tensorflow的计算图
Tensorflow通过计算图的形式来表示计算。是一个有向图。节点代表一个计算,边代表计算之间的依赖关系。
session.runx_data = np.float32(np.random.rand(2,100))
y_data = np.dot([0.1 , 0.2] , x_data) + 0.3
b = tf.Variable(tf.zeros([1]))
W = tf.Variable(tf.random_uniform([1,2],-1.0,1.0))
y = tf.matmul(W,x_data) + b
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)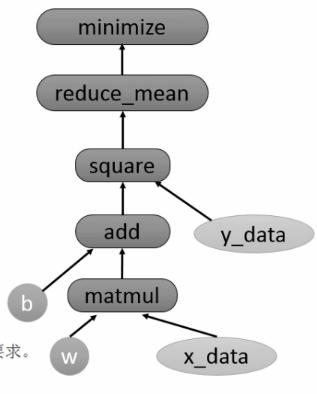
看中间的绿色属于哪一类?
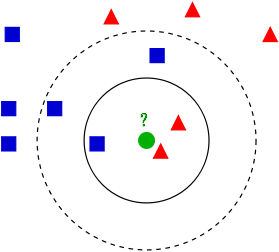
1 欧式距离和曼哈顿距离
欧式距离是两点之间的距离
曼哈顿距离也称作城市街区距离,两个十字路口的实际要走的距离
2 K值的选择
交叉验证法来选择最优的k值。 (一部分训练,一部分测试)| 问题列表 |
|---|
| 1 简介LR |
| 2 LR与SVM的区别和联系 |
| 3 LR与线性回归的区别和联系 |
1 简介LR
问一个女生喜欢你吗,SVM会告诉你喜欢或者不喜欢。很粗暴。
LR则会告诉你,有多喜欢你,多不喜欢你。就是告诉你一个可能性。多喜欢你是取决于她的看重点权值和你身上有的东西x。
使用极大似然法进行参数估计:样本恰好使联合概率密度(似然函数)取得最大值。概率密度相乘。
对数似然函数:
使损失函数 :
令导数为0,发现无法解析求解。
只能借助迭代法,如梯度下降法和拟牛顿法来进行求解。
2 LR和SVM的比较
相同点
线性分类算法,决策面都是线性的判别模型: KNN、 LR 、SVM 。 生成式模型:朴素贝叶斯、 HMM 。
不同点
损失函数不同
LR基于概率理论,用sigmoid函数表示,通过极大似然法估计出参数的值。
SVM基于间隔最大化原理,认为最大几何间隔的分类面为最优分类面。
balancing3 LR与线性回归的联系
联系
LR本质上是一个线性核回归模型
区别
[0,1] ,sigmoid的非线性形式。轻松处理0/1分类问题