SWE-MidTrain 方法
📅 发表于 2026/03/18
🔄 更新于 2026/03/18
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
🌺 论文摘要
参考链接
核心方法
Agentless 训练(3阶段) + SWE-Agent适配(SFT)。
Agentless训练:BugFixer + TestWriter
MidTrain:Diff Patch + PR Commit + 定位推理合成数据 +agent交互合成数据CoT SFT :DeepSeek-R1 蒸馏(SWE-Gym, SWE-bench-extra)CodeEdit RL:执行结果奖励 + 难度课程学习 + 正样本强化SWE-Agent适配:5.7k SWE-smith 轨迹数据 做SFT
训练数据:是不可能开源的。
模型效果(Qwen2.5-72B-Base)
Agentless 训练 SWE-verified Pass@1 48分,TTS(40) 达60分。SWE-Agent SFT适配Pass@1 48分,优于SWE-Agent-LM-32B 40.2分;Pass@10达74分,优于Agentless Pass@30 73.8分,推理次数仅1/3。重要结论
Skill Priors,更好适配SWE-AgentRL的先验最强:做SFT学的快好、做RL效果也更好。关键贡献
多阶段CodeAgent训练方法论Agentless 训练(MT+SFT+RL) + SWE-Agent适配(SFT)。❓问题背景
SWE 2条线路各有弊端
SWE-Agent/OpenHands:更灵活,端到端难训练
Agentless:流程模块化更好,更易RLVR训练。但探索空间灵活性有限。
Trade-off
SWE-agent,先通过Agentless训练诱导出技能先验。Agentless打基础,再训SWE-agentBugFixer
生成patch,解决bugTestWriter
生成单元测试,复现bug成功标准
Patch(BugFixer) 通过 测试用例(TestWriter)。修复前:fail;修复后:成功。依赖2个技能
问题定位:修Bug找源文件;写测试找测试文件。代码编辑:修Bug改源文件;写测试插入新测试函数。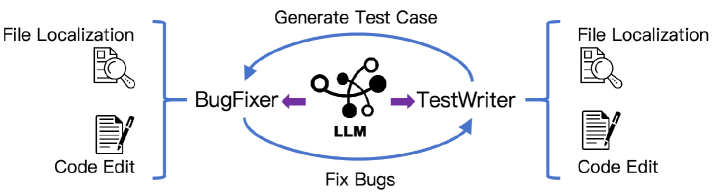
基础配置
Qwen2.5-72B-BaseNext Token PredictionMidTrain 数据
150B 高质量、真实数据。百万级的Github Issue + PR commit数据。 Diff Patch数据:50B,类似AgentlessPR commit 数据:20B,类似SWE-Agent推理交互 合成数据:20B,上采样4倍 即80B,包括思考推理、agent交互数据。超参
32k仓库过滤:低于5star、SWE-bench已包含的仓库。
PR 收集:GithubAPI 查询已合并的PR
废弃、未审核、被替代的PR。代码变更2种格式
Natural Diff Patch + PR Commit PackDiff Patch
Search-Replace 格式,模型最终输出,和Agentless一致。Issue 描述
关联的Issue内容 或 PR 标题。PR 过滤规则
py, md, rst文件修改的PRpython的diff,重写为search-replace块文件新增和删除的PR。修改的文件 不超过3个。search-replace 不超过5个。4 类Prompt 模板 (Agentless)
BugFixer 定位和修复,TestWriter 定位和修复。最终数据规模
50B DiffPatch 数据Commit Pack 说明
提交序列,每一步包含commit + 代码变更SWE-Agent相似处理逻辑
py, md, rst文件修改的PR。修改5个python文件最终数据规模
20B Commit Pack 数据。背景
有代码diff数据,但无思考过程,为什么修改这个文件?方法
使用LLM去预测修改文件,保留正确预测修改文件的数据。
LLM:Qwen2.5-72B-Instruct
SFT微调提升推理质量DeepSeekR1蒸馏的2k数据。数据:海量Github题目。
筛选:仅保留推理正确的数据。
最终数据规模
10B 推理合成数据背景
加强agent能力。自定义工具,模拟agent-环境交互,不执行,模仿文件系统操作,降低成本。文件定位 (Agentless Stage1)
自定义模拟工具: 文件查看和关键词搜索,禁止shell,无需实际执行。工具集放在SystemPrompt里。仅对SystemPrompt做Loss Mask,轨迹的action和observation都做学习训练。环境返回是需要mask的。但这里保留,是为了学习理解环境返回结果。代码编辑 (Agentless Stage2)
定位结果来自stage1,现在进入stage2做代码编辑。负样本训练定位错误文件,手动注入Pattern:我意识到,不需要修改这个文件。增强模型反思能力。PR Commit Pack 转换成轨迹形式Commit:推理步骤。Code Update:动作,str_replace、insert工具格式。最终数据规模
10B Agent交互数据。冷启动数据蒸馏
SWE-bench-extraBugfixer, TestWriterDeepSeek-R1-250120SFT 效果
推理技能:问题分析、方法规划、自我完善、探索替代方案等。背景
MidTrain+LongCoT SFT,模型已具有较强定位能力。代码编辑。数据集
1个Prompt均有1个环境。多种 Bug定位结果,作为LLM输入。课程学习) 难题标准:pass@16=0简单数据集:1.2k,难数据:除开简单的RL策略(GRPO)
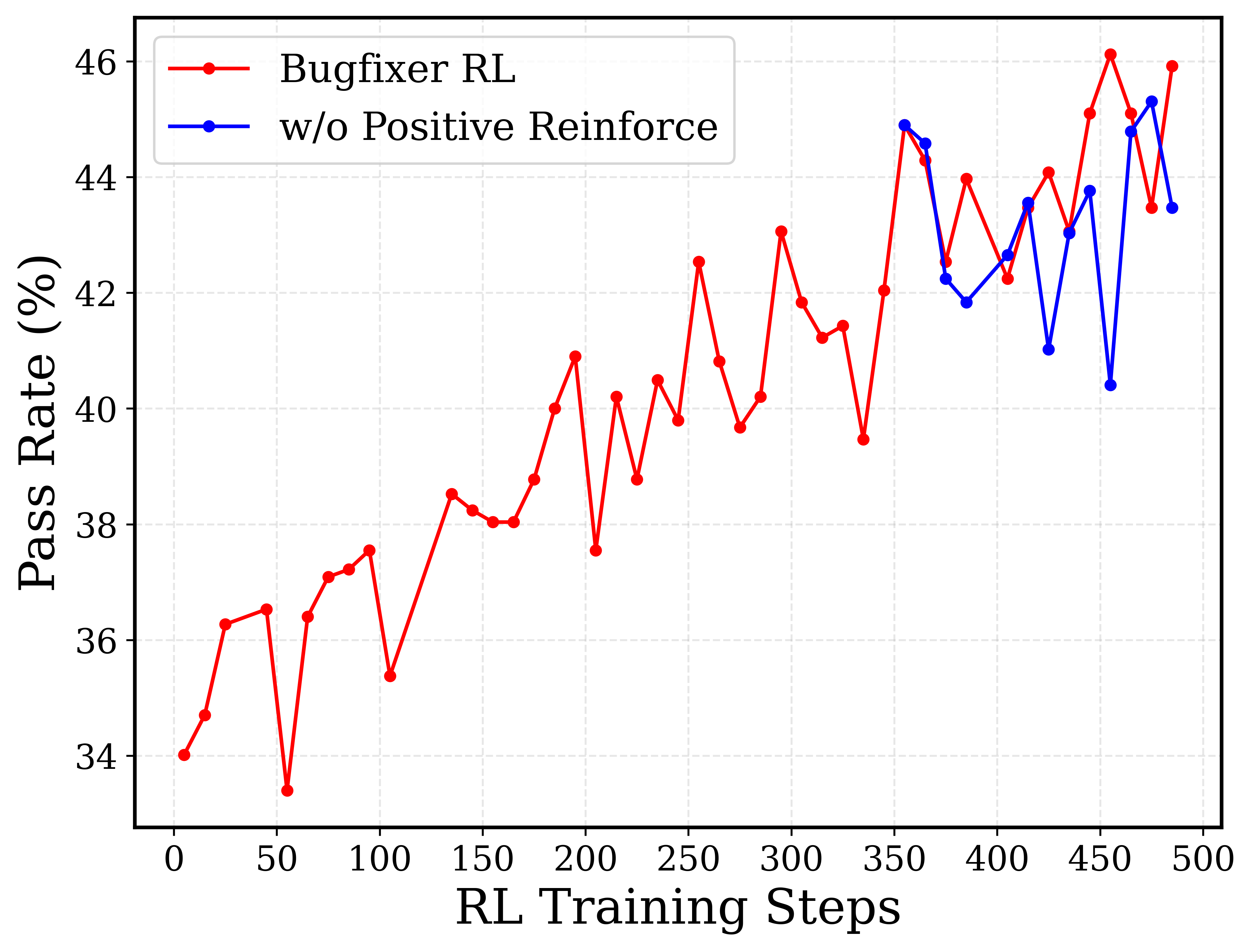
执行结果,0、1,不看格式注释等内容。 BugFixer:通过所有测试得1TestWriter:Fail2Pass。修复前: 有Bug;修复后:无Bug。先只学简单,待分数超过阈值,再逐渐加入难样本。每100step 加入500难样本。平台期,很难探索新解法。之前的正样本,加入迭代,做强化巩固记忆,冲刺效果。正样本强化 后期训练要稳定一些。
并发度
1w 并发,2.5w docker镜像(来自各种数据集)特点
Use-and-Destroy:沙盒只为1次执行,任务跑完后,立即摧毁。自动构建镜像的流水线。技术栈 (K8s + Sdecar)
Kubernetes(K8s):行业标准,容器编排,管理2.5w dockerSidecar Pattern:边车模式 背景
Kimi-Dev 基于Agentless训练,已有Skill PriorsSWE-Agent自由性更高,希望适配SWE-Agent方法
SWE-smith 轨迹数据,5.7k (Claude蒸馏)64k128k + 100轮交互。背景
SWE-AgentSFT实验:给不同数量数据做SFT。RL实验:做1步SFT,然后做RL。Base、MidTrain模型(MT先验)、SFT模型(SFT先验)、RL模型(先验)。RL 模型 (RL先验)
RL先验最好,SFT训练 学的最快、效果最好。更擅长做长线任务:LongCot转化为Agent长交互能力。 RL实验上,RL先验也比SFT先验 好。RL自行悟出解题模式 ,不同于Claude。Mid-Train 模型 (MT先验)
冷启动+RL是必要的。SFT 模型 (SFT 先验)

背景
BugFixer和TestWriter能力。生成阶段
40个patch和40个测试。贪婪解码;剩余39个:温度=1 采样,保证多样性。40个测试。仅保留代码没修复时能报错的单元测试。 验证阶段
解法Patch集合:测试集合:
每个Patch 验证每1个单元测试 有无补丁2种情况
分别记录下报错数通过数
并计算Fail2Pass, Pass2Pass数量。
最终Patch 高FP率 + 高PP率,能修bug + 不会破坏原有功能。
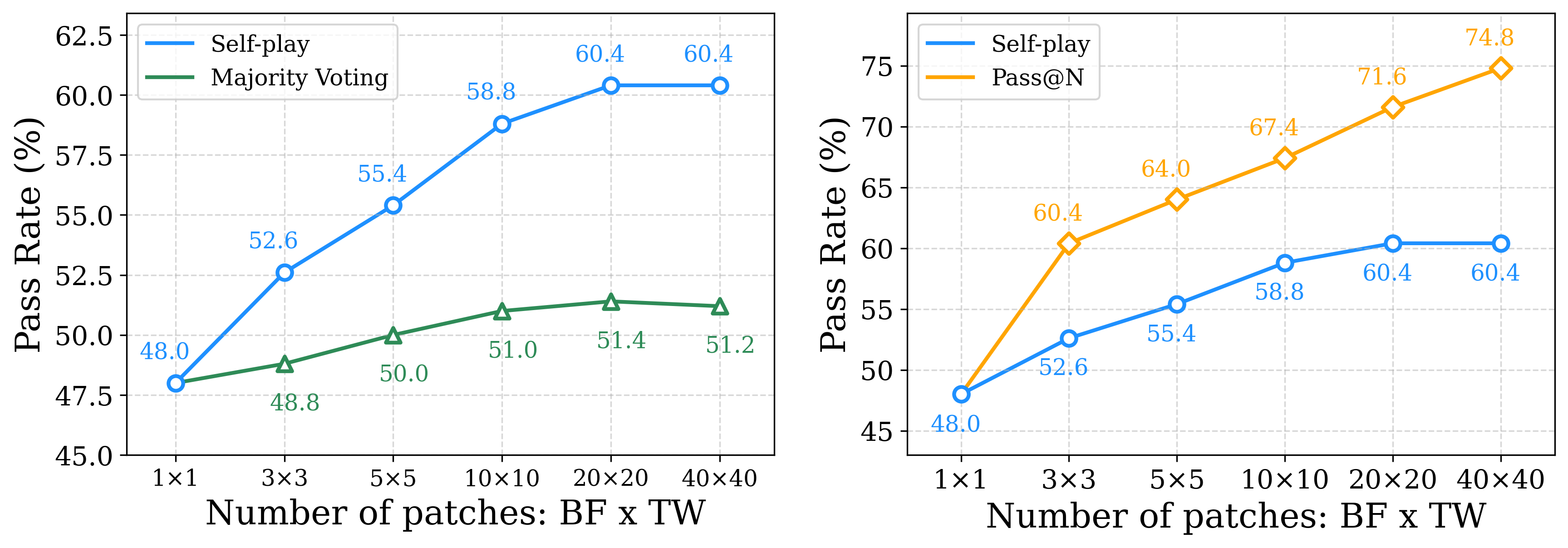
Self-play 效果不如 Pass@N,优于投票。
✍️实验设置
基础模型
训练任务/数据
MidTrain:150B token,DiffPatch + PR Commit + 推理数据 + 交互数据LongCoT SFT:2k+数据,SWE-Gym + SWE-Bench-extraCode-Edit RL:1k数据,SWE-Gym + SWE-Bench-extra评测任务/数据
算法/策略
Agentless 框架 :BugFixer + TestWriter,都依赖定位和编辑能力。Mid-Train:NTP任务,Diff+PR+推理+交互模拟(文件定位和代码编辑)。SFT:DeepSeekR1 + 2角色蒸馏,提升推理技能。RL (GRPO):结果奖励 + 难度课程学习 + 后期正样本强化超参
rollout=10,64k🍑关键结果
模型效果(Qwen2.5-72B-Base)
Agentless 训练:SWE-verified pass@1 48分,使用TTS(40)后,达60.4分。pass@1 48分,优于SWE-Agent-LM-32B 40.2分。Pass@10 74分,优于Agentless Pass@30 73.8分,推理次数仅1/3。重要结论
Skill Priors,更好适配SWE-AgentRL的先验最强:做SFT学的快好、做RL效果也更好。关键贡献
多阶段CodeAgent训练方法论。Agentless 训练(MT+SFT+RL) + SWE-Agent适配(SFT)。 MidTrain各阶段,使用2k 冷启动数据后,评测SWE
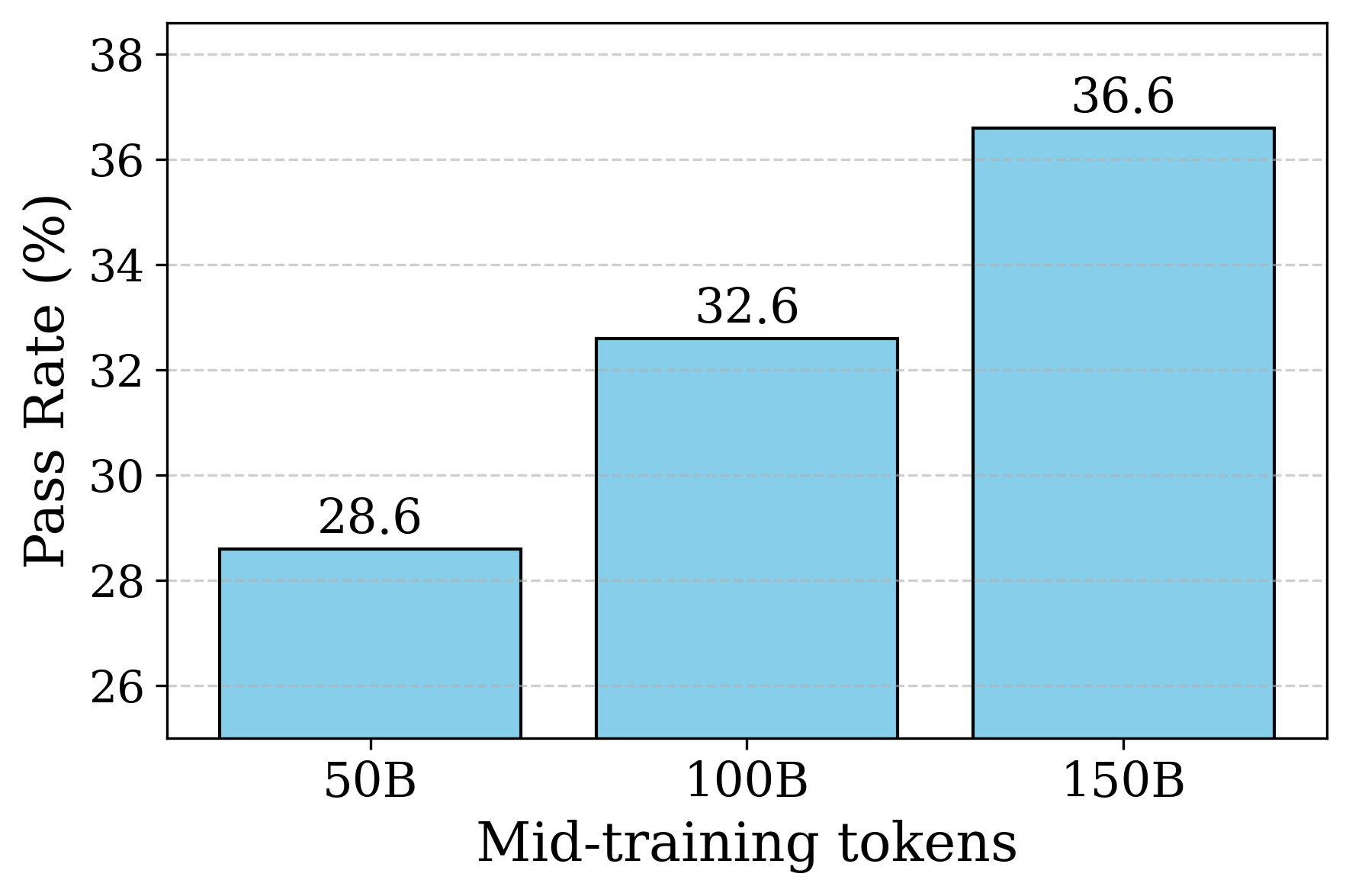
RL 效果和训练长度有关。
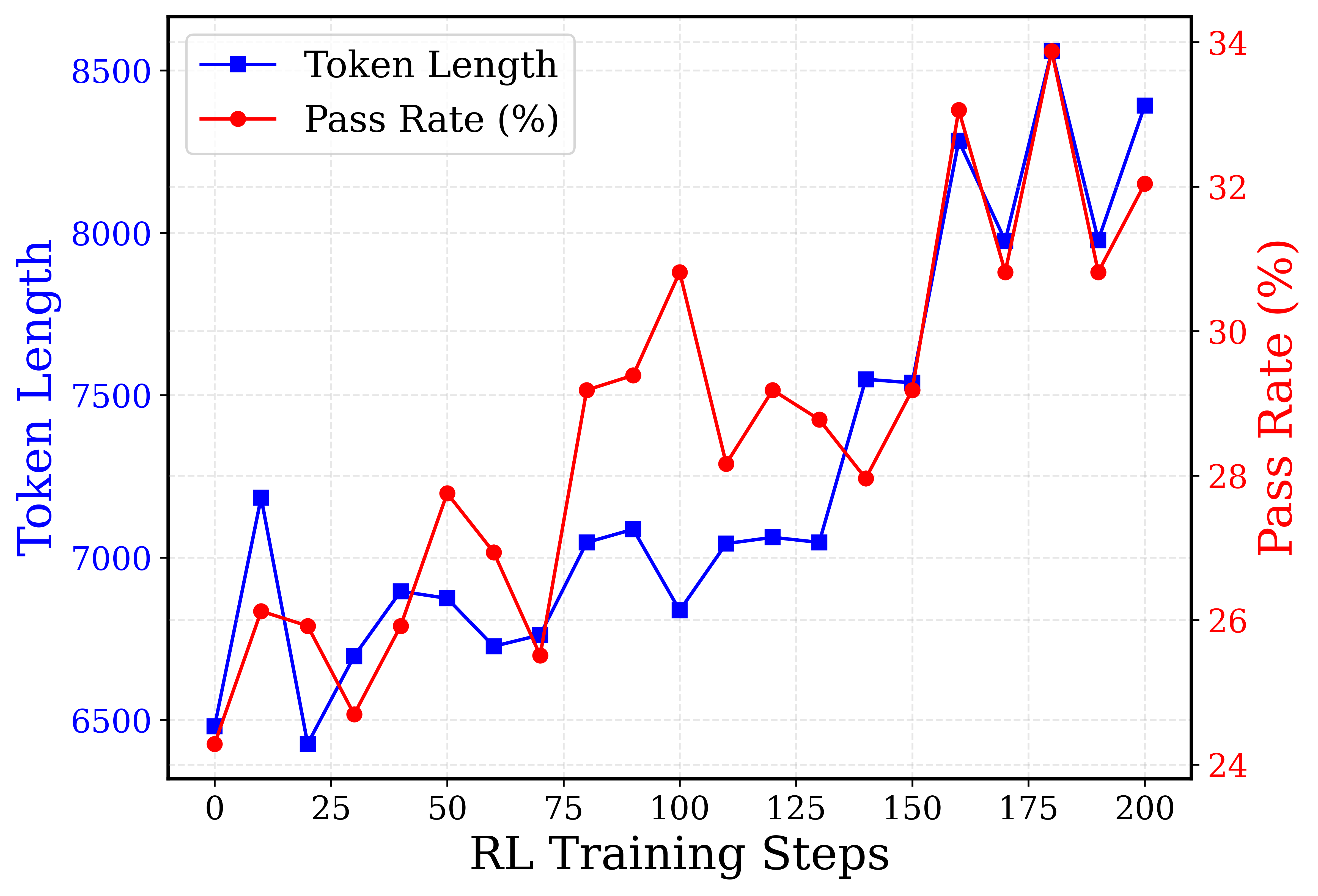
⛳ 未来方向
TestWriter 改进:目前生成测试不够全面,需提升质量。端到端SWE-Agent RL:目前Agent仅做了SFT,未来可做RL。环境扩展:利用合成环境进一步扩大训练数据规模。