目前最强NLP模型,横扫NLP11项任务。利用Transformer去预训练双向语言模型和NSP任务,再finetune达到了各种任务的最优效果。
背景
简介
在NLP中,利用语言模型去做预训练,能显著提升许多任务的效果。
句子级别任务:自然语言推理等。学习多个句子之间的关系词级别任务 :NER、QA、SQuAD等
两种迁移方式
- 基于特征:ELMo
- 基于finetune:OpenAI GPT
存在的问题
单向语言模型和两个方向语言模型简单拼接,这两个方法的能力都小于双向语言模型。
单向语言模型对于:
sentence-level任务:次优方案。token-level任务:效果很差。比如SQuAD,非常需要融合两个方向的信息
相关研究
1. 基于特征的方法
- 词向量
sentence、paragraph向量- 从语言模型中获得具有上下文语义的向量--ELMo
2. 基于Finetune的方法
预训练一个语言模型,在下游任务只需要简单finetune,只需要从新训练很少的参数。
3. 基于监督数据的迁移学习
从一些大规模是数据集中进行迁移学习。比如
- 从自然语言推理中迁移
- 从机器翻译中迁移学习词向量:Learned in Translation: Contextualized Word Vectors
BERT模型
模型架构
1. 总体架构
利用Transformer的Encoder去训练双向语言模型BERT,再在BERT后面接上特定任务的分类器。
![]()
使用方法示例:
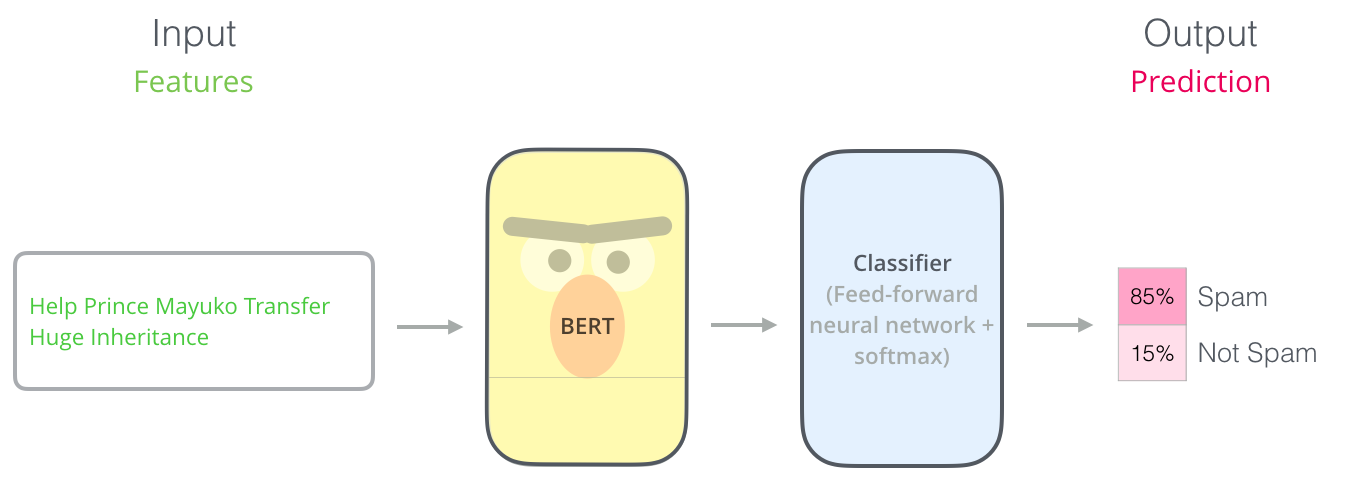
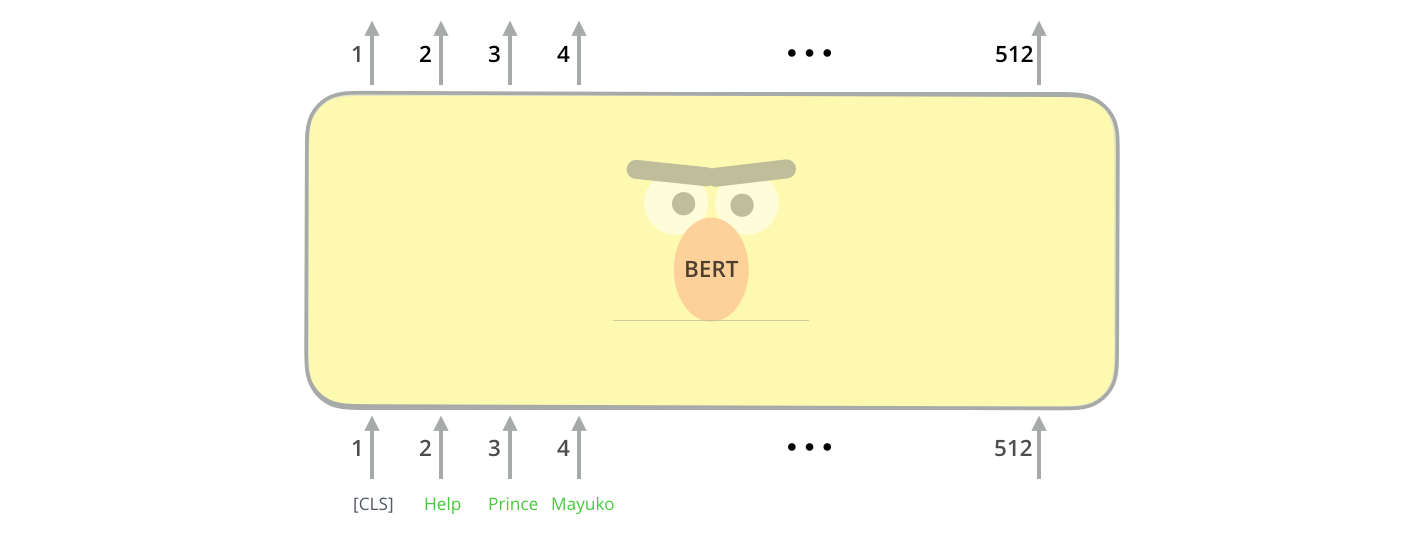
2. 输入与输出
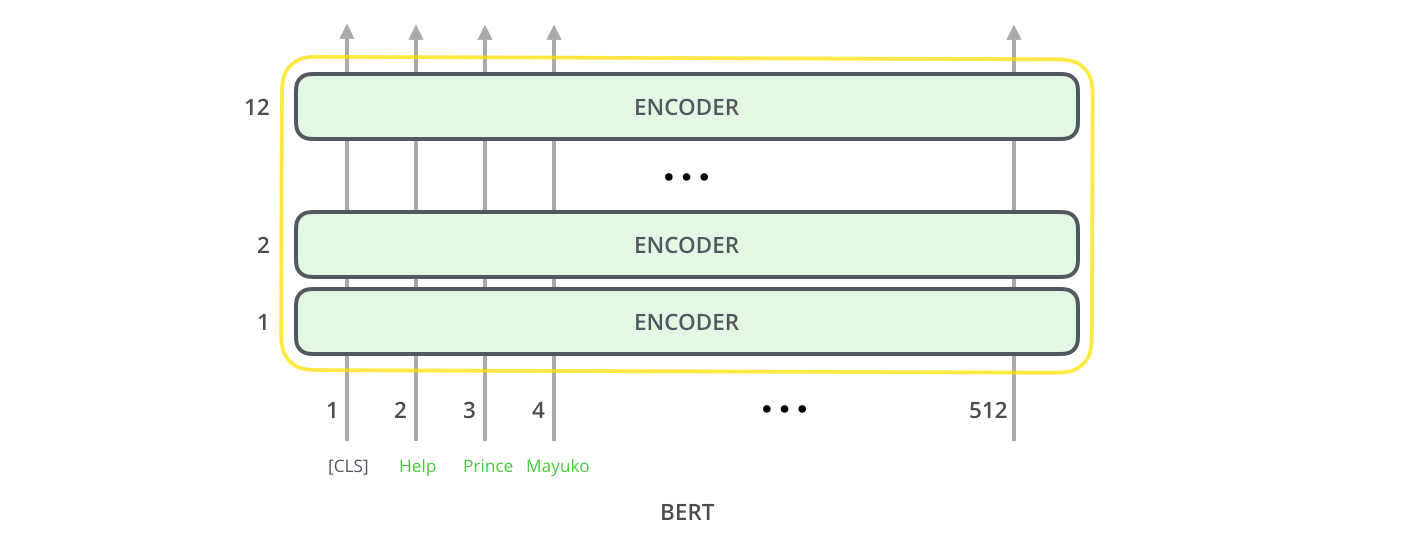
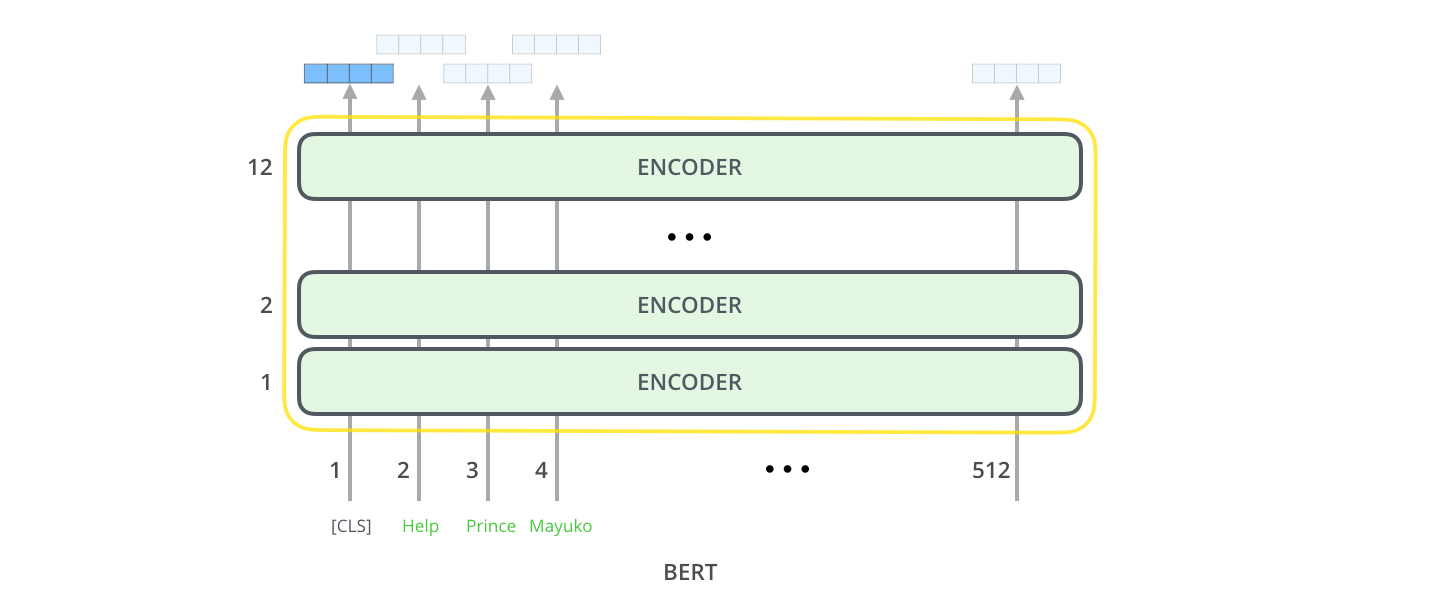
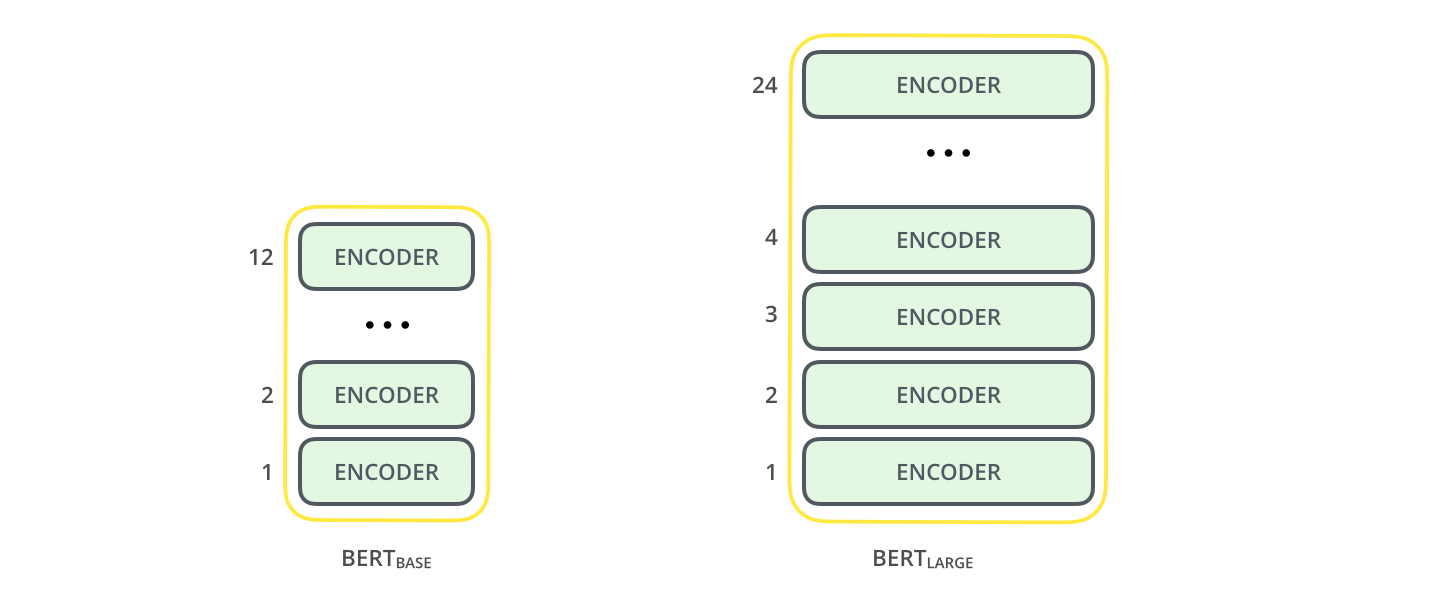
3. 两种规模
- \(\rm{BERT}_{BASE}\) :\(\rm{L=12, H=768, A=12}\)。总参数为110M。和GPT一样
- \(\rm{BERT}_{LARGE}\) :\(\rm{L=24, H=1024, A=16}\)。总参数为340M。最优模型

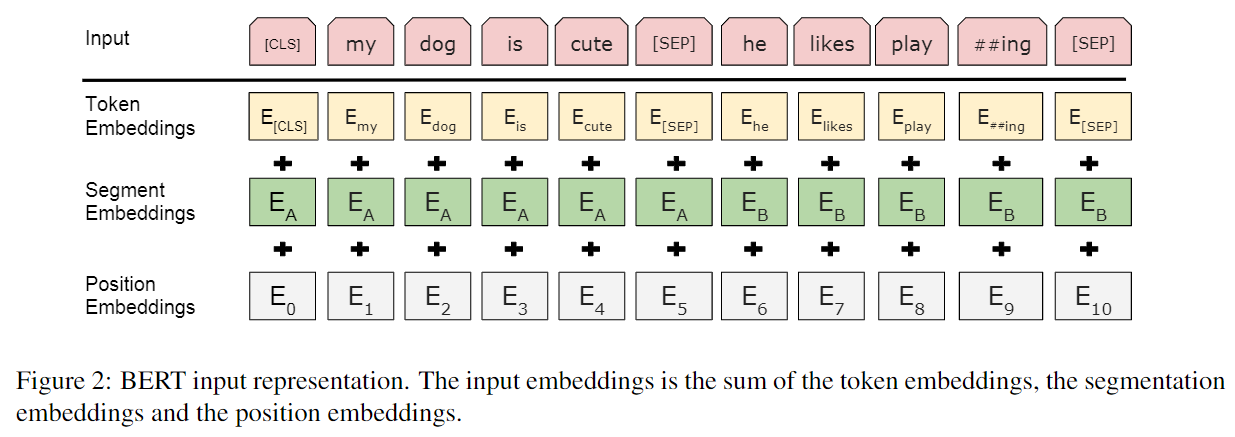
单个位置的输入
每个位置输入三个部分相加而成:
wordpiece-token向量位置向量:512个。训练段向量:sentence A B两个向量。训练
一些符号:
CLS:special classification embedding,用于分类的向量,会聚集所有的分类信息SEP:输入是QA或2个句子时,需添加SEP标记以示区别- \(E_A\)和\(E_B\):输入是QA或2个句子时,标记的sentence向量。如只有一个句子,则是sentence A向量
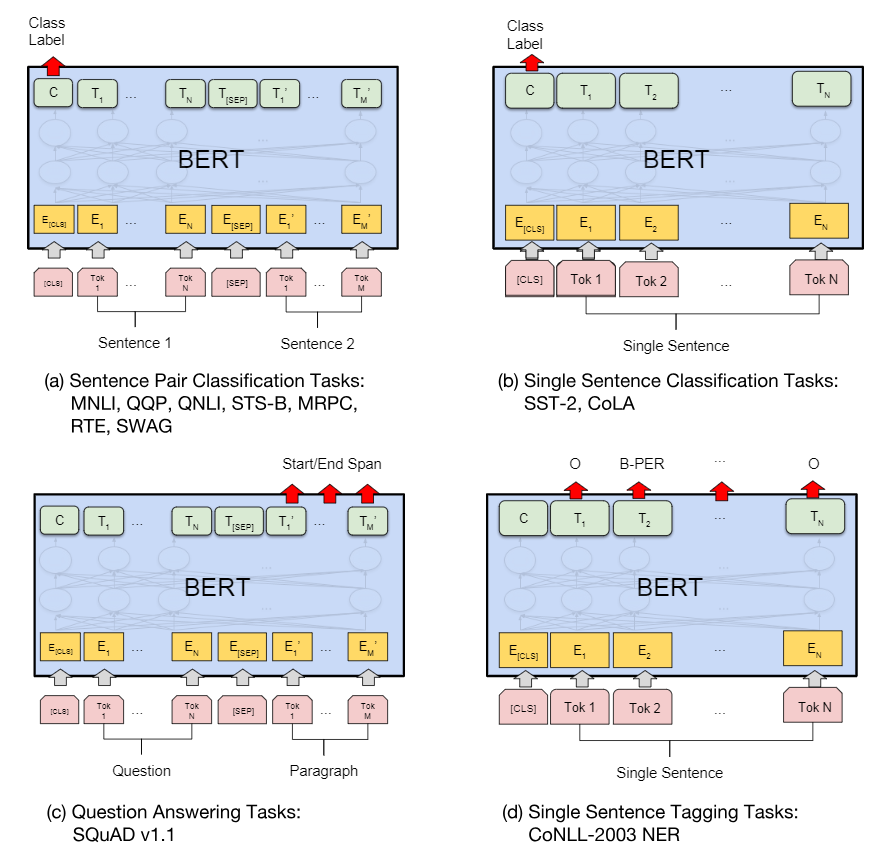
特定任务的BERT
- 单句子分类:CLS+句子。利用CLS进行分类
- 多句子分类:CLS+句子A+SEP+句子B。利用CLS分类
- SQuAD:CLS+问题+SEP+文章。利用所有文章单词的输出做计算start和end
- NER:CLS+句子。利用句子单词做标记
预训练语言模型
我们都知道单向语言模型的能力很差,单独训练两个方向的语言模型再把结果拼接起来也不好。那么怎么才能训练一个真正的双向语言模型呢?如何让一个单词is conditioned on both left and right context呢?答案就是Masked Language Model
Masked LM
在进行WordPiece之后,随机掩盖一些(15%)词汇,再去预测这些词汇。
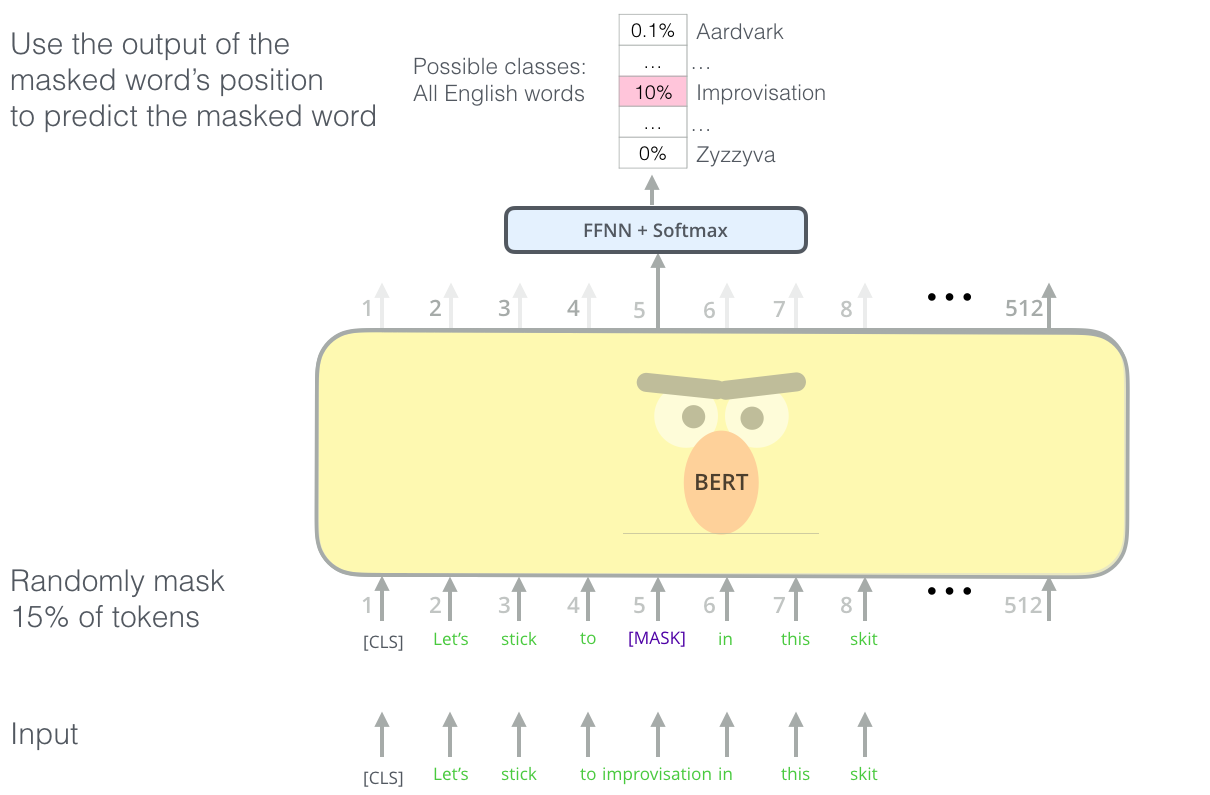
但是有2个缺点
缺点1 大量mask标记,造成预训练和finetune时候的差距,因为finetune没有mask
- 80%:替换为mask
- 10%:随机替换为其它词汇
- 10%:保留原来的词汇。这部分正确的保留,保证了语言能力。
由于Transformer不知道要预测哪个词语,所以它会强制学习到所有单词的上下文表达。
缺点2 收敛很慢,但是效果好
比单向语言模型收敛较慢。
预训练NSP任务
对于像QA、NLI等需要理解多个句子之间关系的下游任务,只靠语言模型是不够的。还需要提前学习到句子之间的关系。
Next Sentence Prediction
NSP-Next Sentence Prediction,是一个二分类任务。输入是A和B两个句子,标记是IsNext或NotNext,用来判断B是否是A后面的句子。这样,就能从大规模预料中学习到一些句间关系。

模型最终能达到97%-98%的准确率,对QA和NLI都很有效果。
预训练细节
数据组成
语料是下面两个库,合计33亿词汇。采用文档级别的语料,有利于学习长依赖序列。
BooksCorpus:8亿个词。(800M)英文维基百科:25亿个词。(2,500M)
从语料库中随机选择2个片段(较长)作为两个AB句子,构成一条输入数据:
- 0.5概率A-B两个句子连续,0.5概率随机选择B
- A使用A embedding,B使用B embedding
- A和B总长度最大为512 tokens
WordPiece Tokenization后再mask掉15%的词汇。
训练参数
batch_size:256。每条数据长度:512- 100万步,40个epoch。语料合计33亿词汇
- Adam :\(\beta_1=0.9, \beta_2=0.999\)
- L2权值衰减为0.01。所有层的dropout为0.1
- 学习率的warmup的step为10000
- GELU激活函数
- 训练loss:LM和NSP的loss加起来
- BERT base 16个TPU,Large 64个TPU,训练4天
Finetune细节
两种不同类型的任务所需要的向量,详情见特定任务的BERT
sentence-level:一般只拿CLS位置的向量,过线性层再softmax即可得到分类结果token-level:SQuAD或NER,取对应位置的向量,过线性层再softmax得到相应的结果
Finetune时超参数基本一致,但有一些是与特定任务相关的。下面是比较好的选择
Batch size:16, 32学习率:\(5*10^{-5}\),\(3*10^{-5}\),\(2*10^{-5}\)epoch:3,4
BERT与GPT比较
BERT和OpenAI GPT都是使用Transformer进行预训练语言模型, 再进行finetune达到不错的效果。区别如下:
| 项目 | BERT | GPT |
|---|---|---|
| 训练数据 | BooksCorpus(8亿)+维基百科(25亿) | BooksCorpus(8亿) |
| 任务 | 双向语言模型(MLM)+NSP+Finetune | 单向语言模型+Finetune |
| Transformer | Encoder | Decoder |
| 符号 | CLS, SEP, sentence A-B | Start, SEP, 结束(CLS) |
| 符号使用 | 预训练、finetune过程 | finetune过程 |
| Batch数据 | 1M步,128000个词汇 | 1M步,32000个词汇 |
| finetune学习率 | 与特定任务相关 | 与预训练一样,\(5*10^{-5}\) |
实验结果
9项GLUE任务
General Language Understanding Evaluation 包含了很多自然语言理解的任务。
1. MNLI
Multi-Genre Natural Language Inference是一个众包大规模的文本蕴含任务。
给2个句子,判断第二个句子与第一个句子之间的关系。蕴含、矛盾、中立的
2. QQP
给2个问题,判断是否语义相同
3. QNLI
Question Natural Language Inference 是一个二分类任务,由SQuAD数据变成。
给1个(问题,句子)对,判断句子是否包含正确答案
4. SST-2
Stanford Sentiment Treebank,二分类任务,从电影评论中提取。
给1个评论句子,判断情感
5. CoLA
The Corpus of Linguistic Acceptablity,二分类任务,判断一个英语句子是否符合语法的
给1个英语句子,判断是否符合语法
6. STS-B
The Semantic Textual Similarity Benchmark,多分类任务,判断两个句子的相似性,0-5。由新闻标题和其他组成
给2个句子,看相似性
7. MRPC
Microsoft Research Paraphrase Corpus,2分类任务,判断两个句子是否语义相等,由网上新闻组成。05年的,3600条训练数据。
给1个句子对,判断2个句子语义是否相同
8. RTE
Recognizing Textual Entailment,二分类任务,类似于MNLI,但是只是蕴含或者不蕴含。训练数据更少
9. WNLI
Winograd NLI一个小数据集的NLI。据说官网评测有问题。所以评测后面的评测没有加入这个
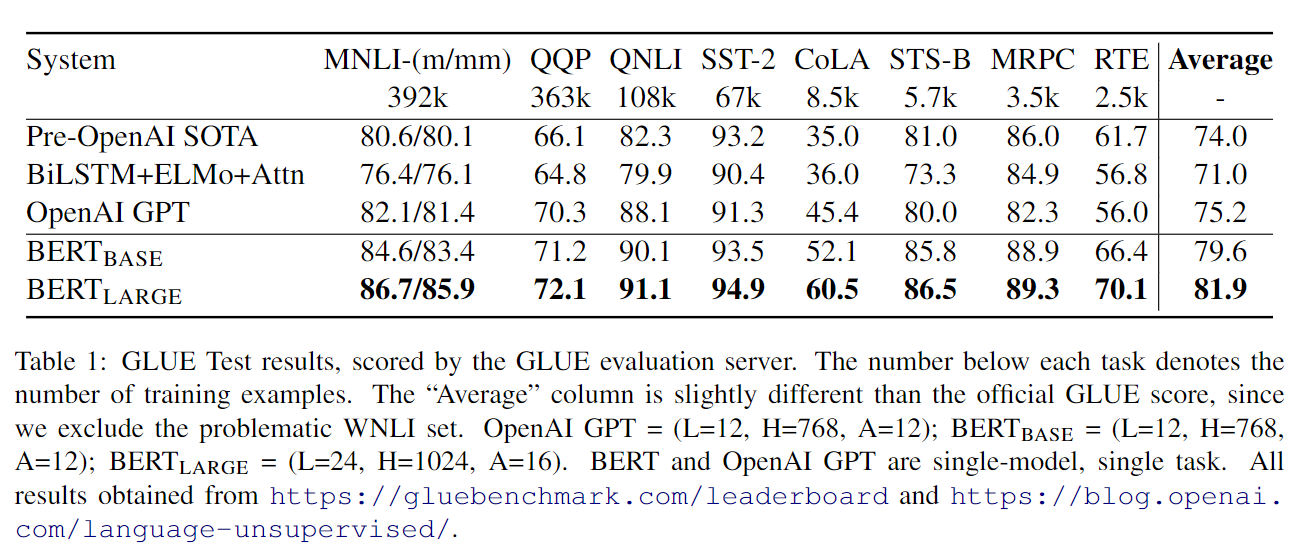
GLUE评测结果
对于sentence-level的分类任务,只用CLS位置的输出向量来进行分类。
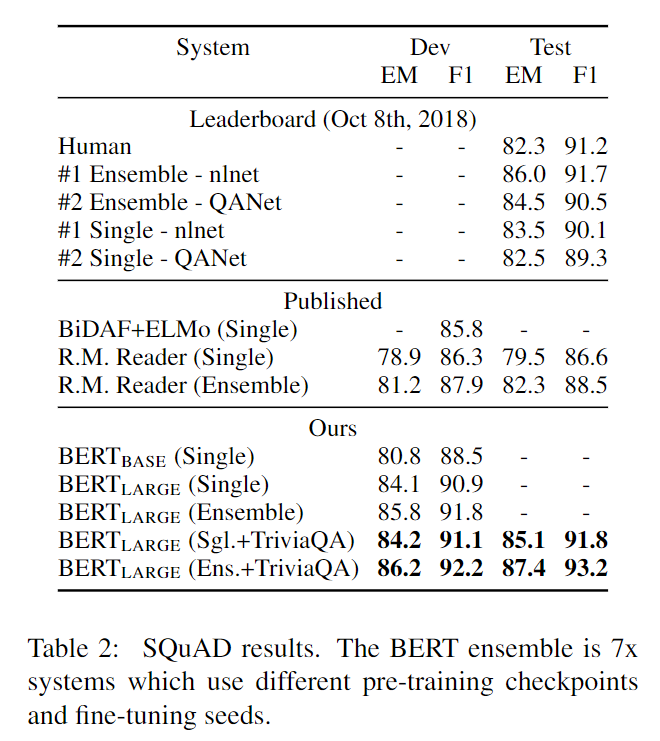
SQuAD-v1.1
SQuAD属于token-level的任务,不是用CLS位置,而是用所有的文章位置的向量去计算开始和结束位置。
Finetune了3轮,学习率为\(5*10^{-5}\),batchsize为32。取得了最好的效果
NER

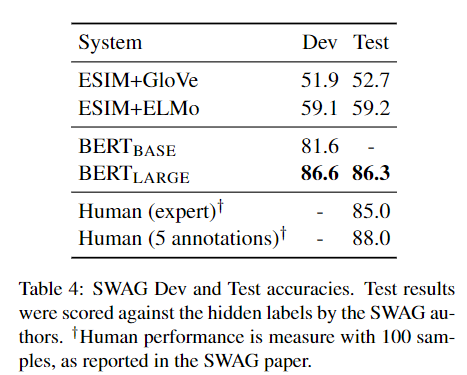
SWAG
The Situations With Adversarial Generations 是一个常识性推理数据集,是一个四分类问题。给一个背景,选择一个最有可能会发生的情景。
Finetune了3轮,学习率为\(2*10^{-5}\),batchsize=16
效果分析
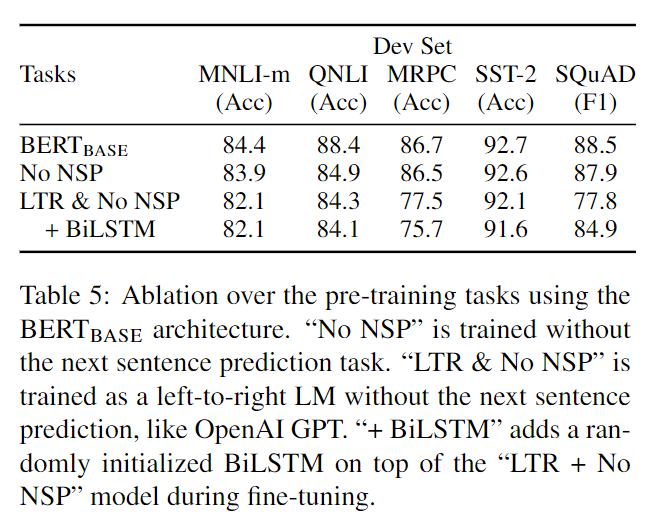
任务影响
No NSP:不加NSP任务;LTR 单向语言模型。
- NSP:对SQuAD、QNLI、MNLI有影响,下降1个点左右
- 双向LM:如果是LTR,SQuAD、MRPC都严重下降10个点。因为token-level的任务,更需要右边上下文的信息
模型大小
BERT的base和large的参数分别为:110M和340M。
一般来说,对于大型任务,扩大模型会提升效果。但是,BERT得到充分预训练以后,扩大模型,也会对小数据集有提升!这是第一个证明这个结论的任务。
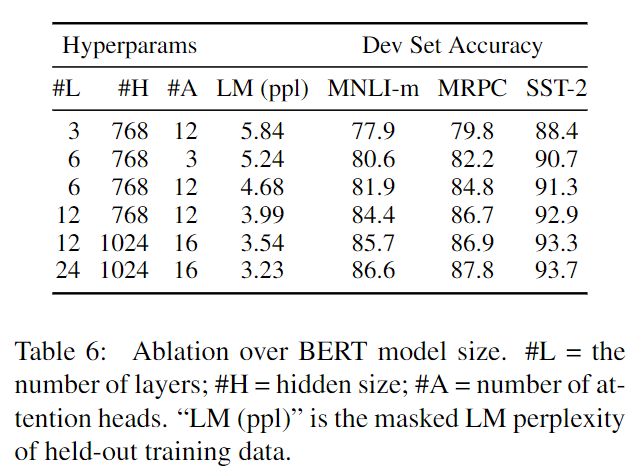
训练步数
- 确实需要训练100万步。12800词/batch
- MLM收敛到最优慢,但是效果好。在早期就早早超过单向语言模型了
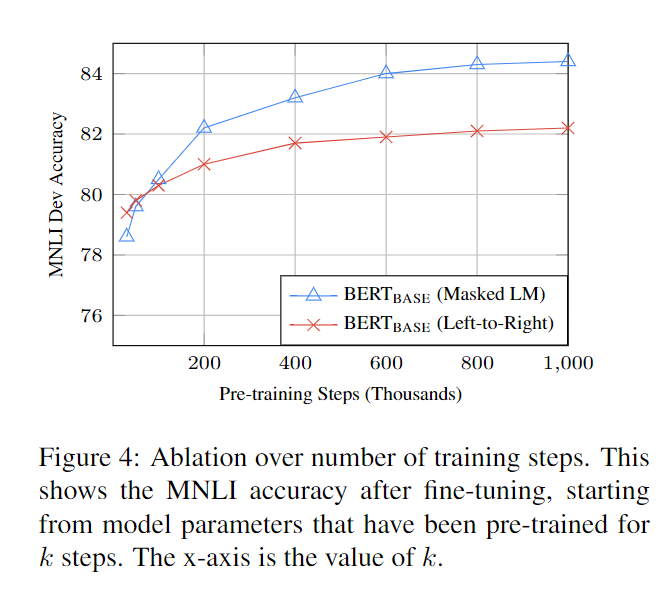
BERT使用方法
基于finetune
基于特征
Finetune稍微麻烦一些。可以使用BERT预训练好的contextualized embeddings,每一层都有。
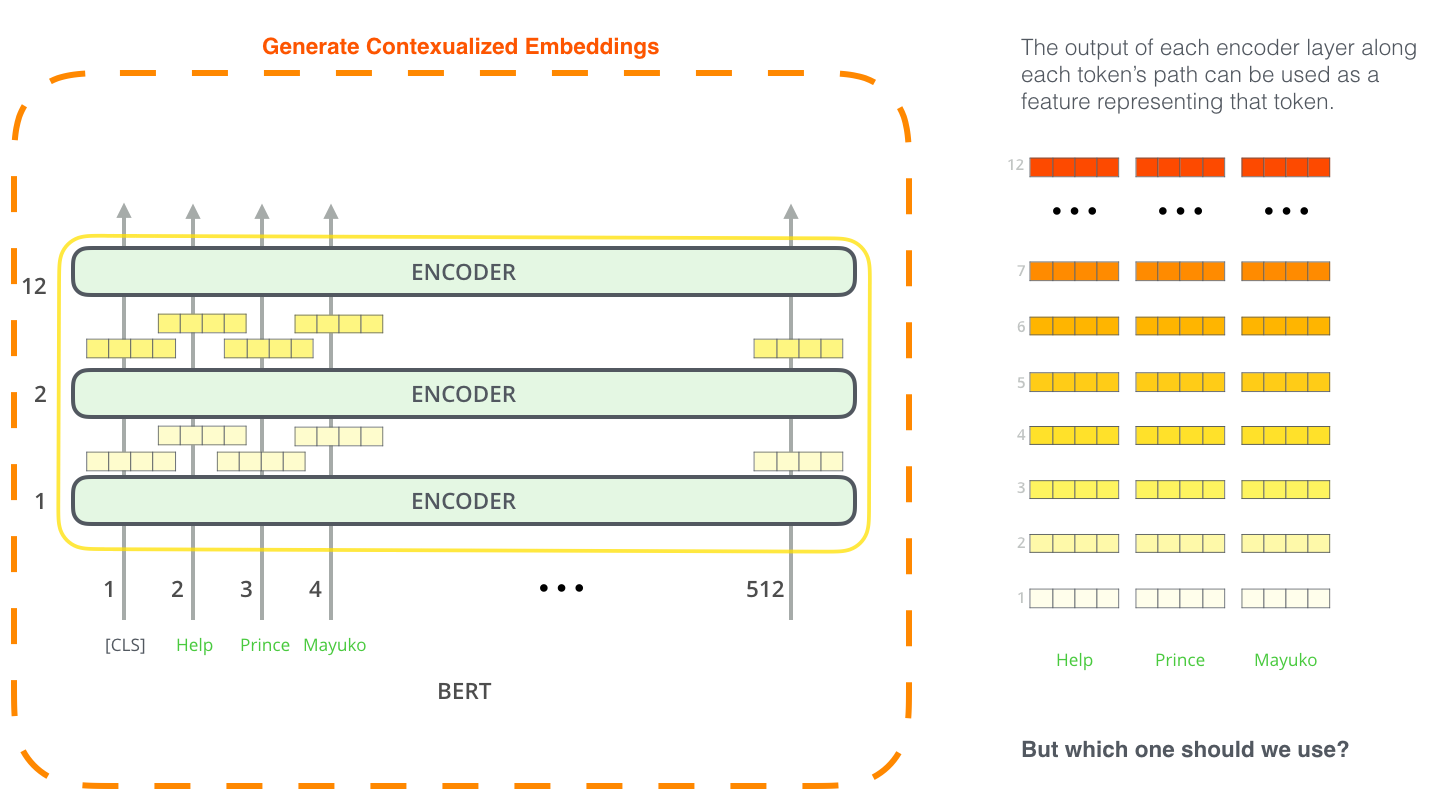
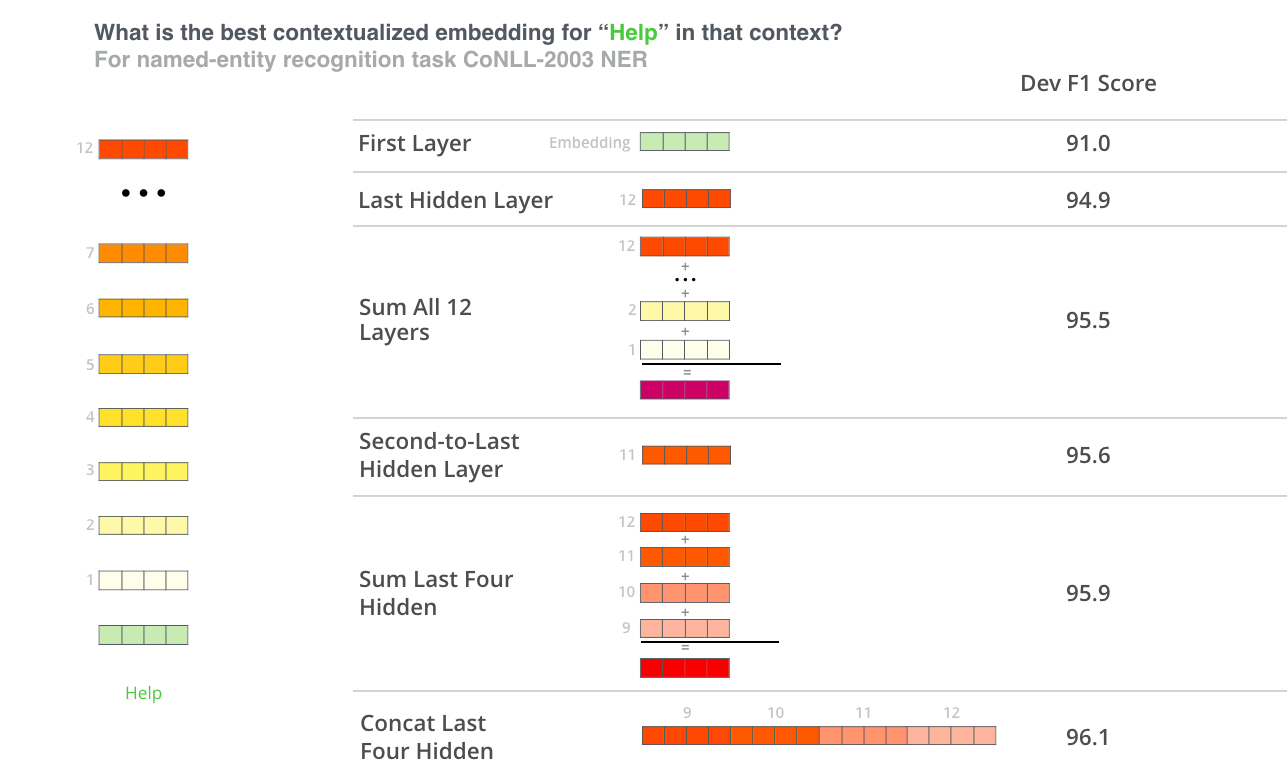
其中效果最好的方法,就是拼接最后四层的向量。

参考和思考
参考
思考
- 今年很流行 无监督预训练和有监督finetune,那么有什么演变历程吗?
- BERT的成功会是因为更多的数据吗?
- BERT很通用太重量级,8个GPU据说要训练一年。普通人难以训练。
- BERT是一个通用预训练模型,那么我们还要继续研究特定任务的架构吗?

