大名鼎鼎的Transformer,Attention Is All You Need
Transformer概览
论文结构
![]()
总览结构
![]()
图解总览
其实也是一个Encoder-Decoder的翻译模型。
![]()
由一个Encoders和一个Decoders组成。
![]()
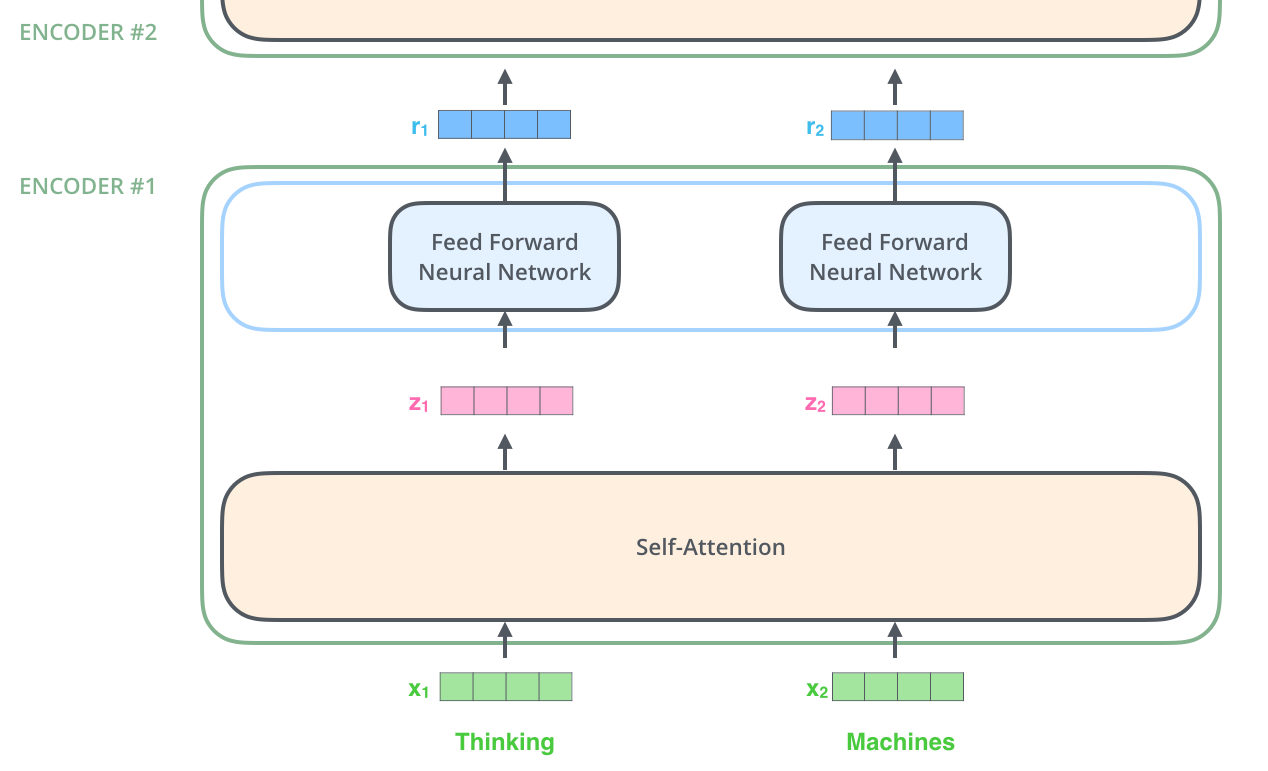
Encoders由多个Encoder块组成。
![]()
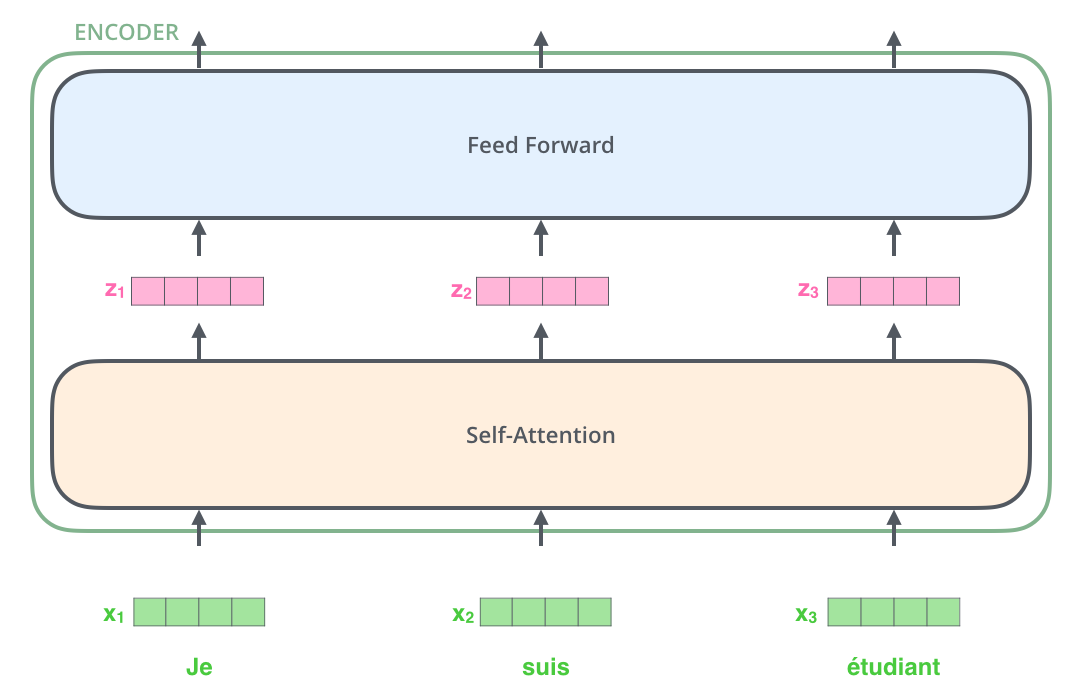
Encoder
总体结构
1个Encoder由Self-Attention和FFN组成
![]()
一个Encoder的结果再给到下一个Encoder
Encoder-Decoder
![]()
编码实例
对一个句子进行编码

Self-Attention会对每一个单词进行编码,得到对应的向量。\(\mathbf{x_1}, \mathbf{x_2}, \mathbf{x_3} \to \mathbf{z_1}, \mathbf{z_2}, \mathbf{z_3}\),再给到FFN,会得到一个Encoder的结果\(\mathbf{r_1}, \mathbf{r_2}, \mathbf{r_3}\), 再继续给到下一个Encoder
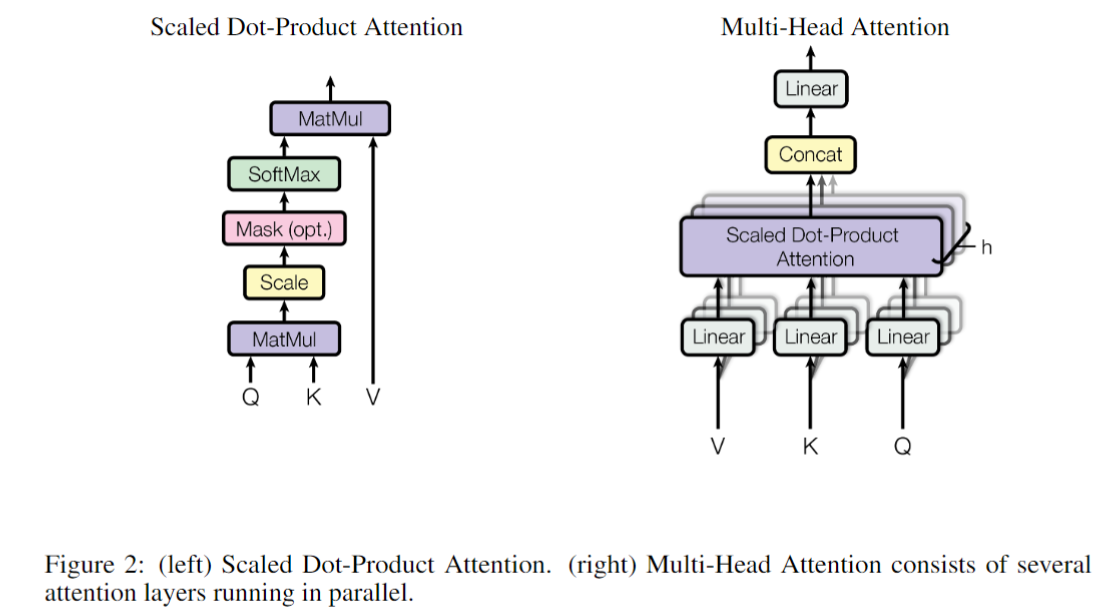
Attention
Self-Attention
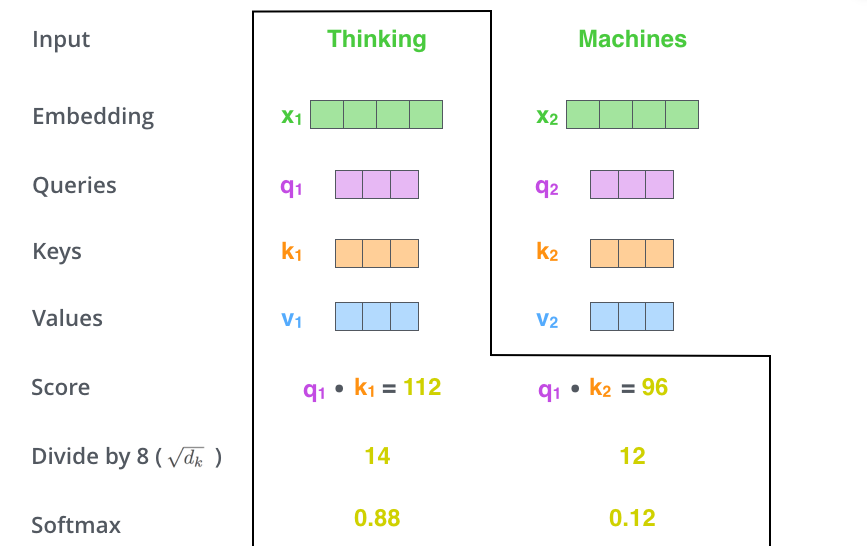
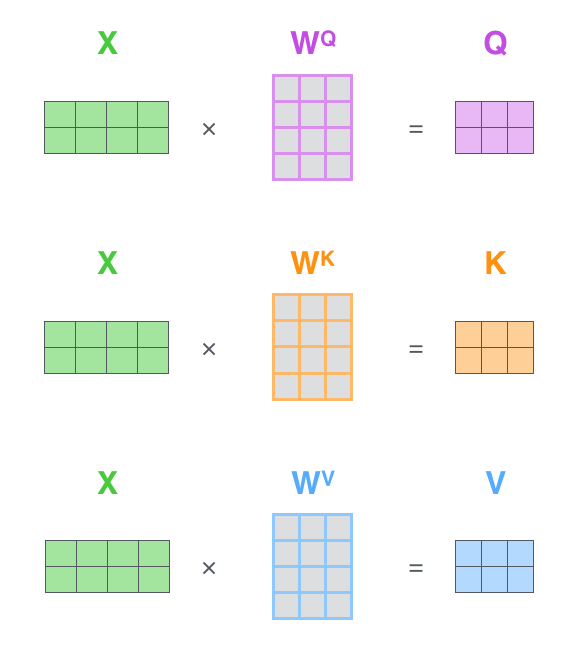
1. 乘以3个矩阵生成3个向量:Query、Key、Value
![]()
2. 计算与每个位置的score
编码一个单词时,会计算它与句子中其他单词的得分。会得到每个单词对于当前单词的关注程度。
![]()
3. 归一化和softmax得到每个概率
4. 依概率结合每个单词的向量
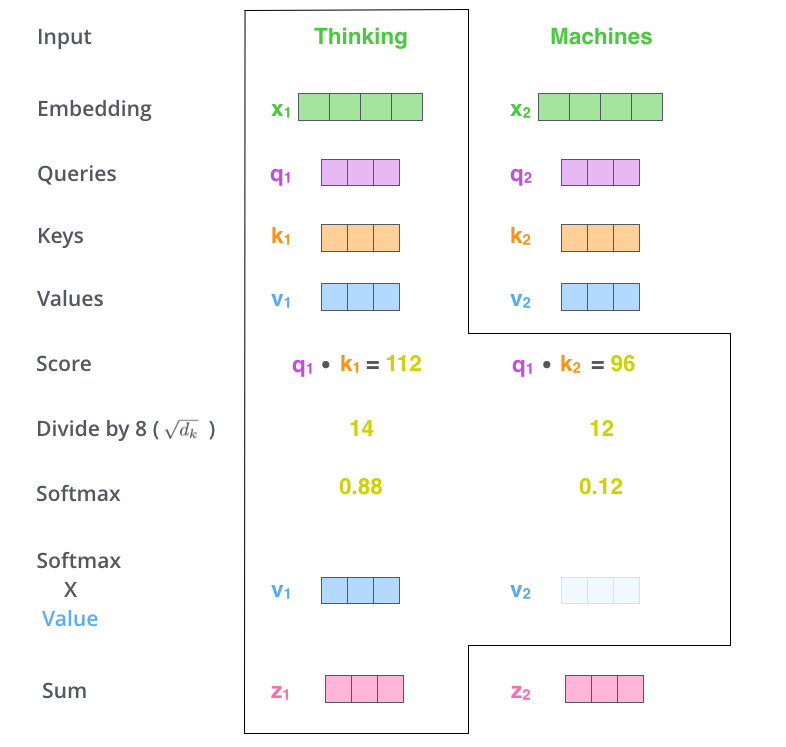
Attention图示
![]()
矩阵形式
其实就是一个注意力矩阵公式
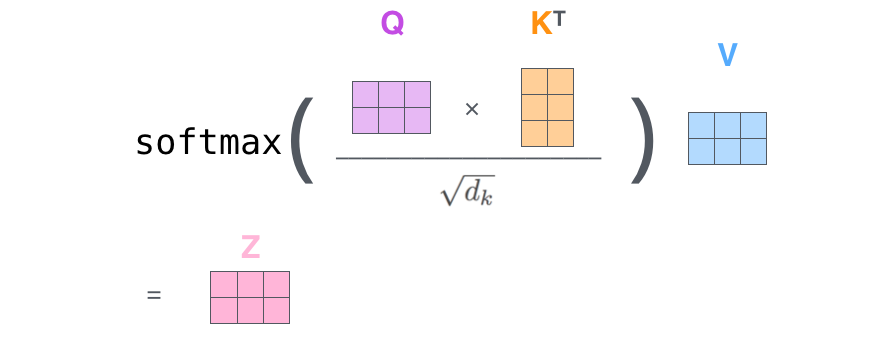
多头注意力
其实就是多个KV注意力。从两个方面提升了Attention Layer的优点
- 让模型能够关注到句子中的各个不同位置
- Attention Layer可以有多个不同的表示子空间
representation subspaces
![]()
多头注意力矩阵形式
经过多头注意力映射,会生成多个注意力\(Z_0, Z_1, \cdots, Z_7\)。
![]()
把这些注意力头拼接起来,再乘以一个大矩阵,最终融合得到一个信息矩阵。会给到FFN进行计算。
![]()
注意力总结
![]()
Attention图示
![]()
![]()
前向神经网络
Position-wise Feed-Forward Network,会对每个位置过两个线性层,其中使用ReLU作为激活函数。 \[
\rm{FFN}(x) = \rm{Linear}(\rm{ReLU}(\rm{Linear}(x))) = \rm{max}(0, xW_1 + b_1)W_2 + b_2
\]
位置编码
词向量+位置信息=带位置信息的词向量 \[ \rm{PE}(pos, 2i) = \sin (\rm{pos} / 10000^{\frac{2i}{d}}) \]
\[ \rm{PE}(pos, \rm{2i+1}) = \cos (\rm{pos} / 10000^{\frac{2i}{d}}) \]
![]()
示例
再把sin和cos的两个值拼接起来,就得到如下图所示。
![]()
![]()
Encoder-Block
残差连接
![]()
层归一化
![]()
总览
![]()
Decoder
单步
![]()
多步
![]()
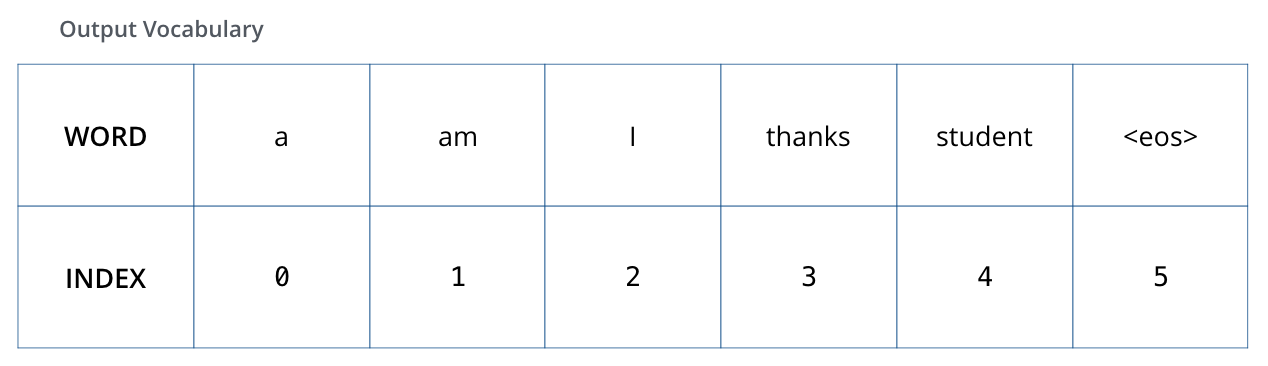
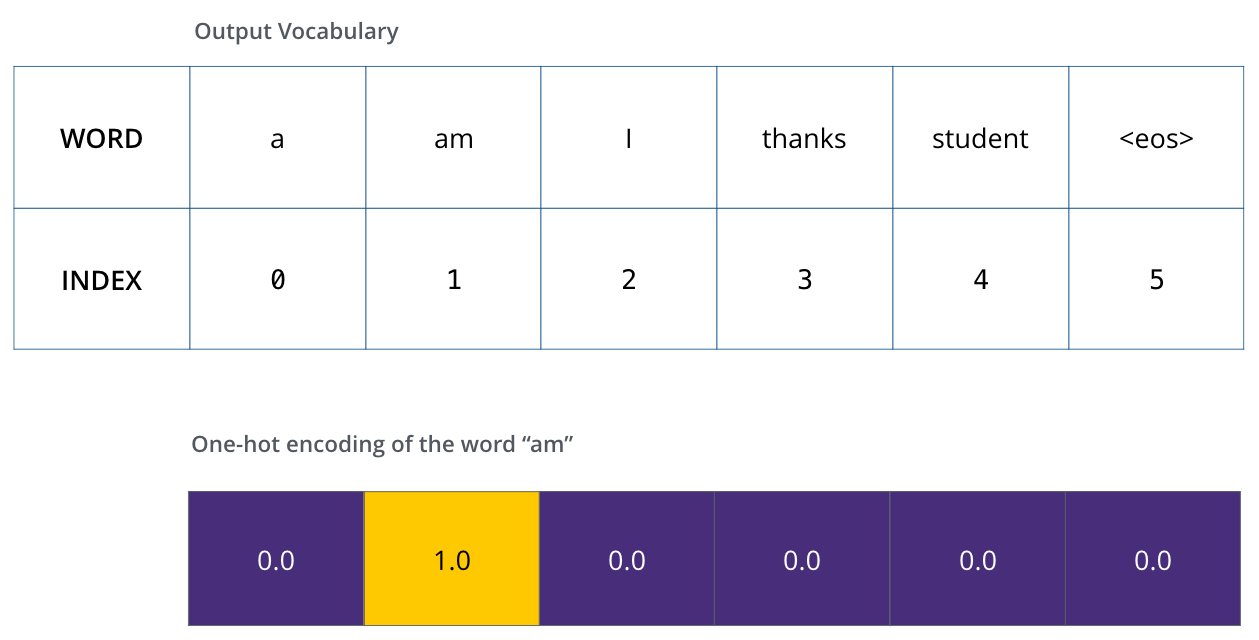
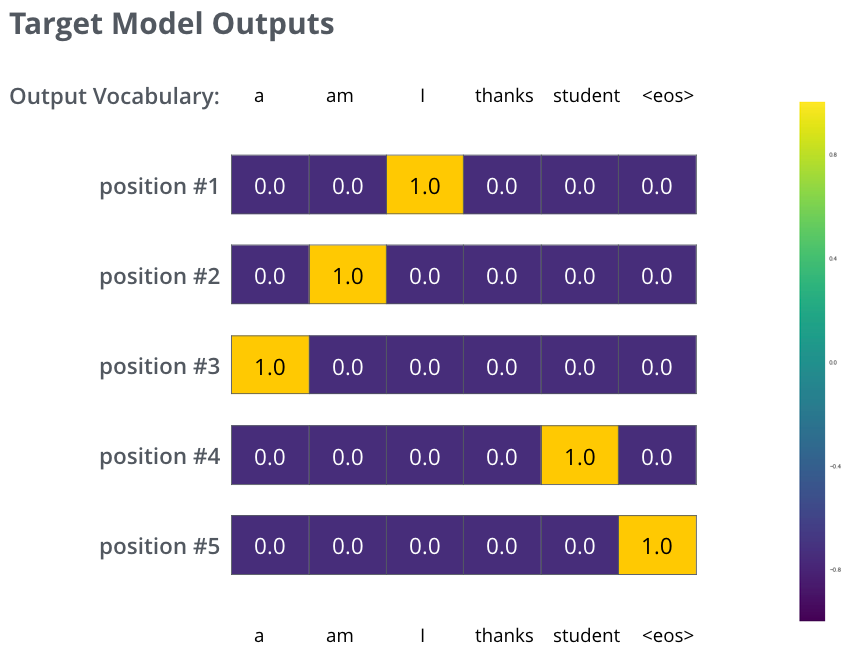
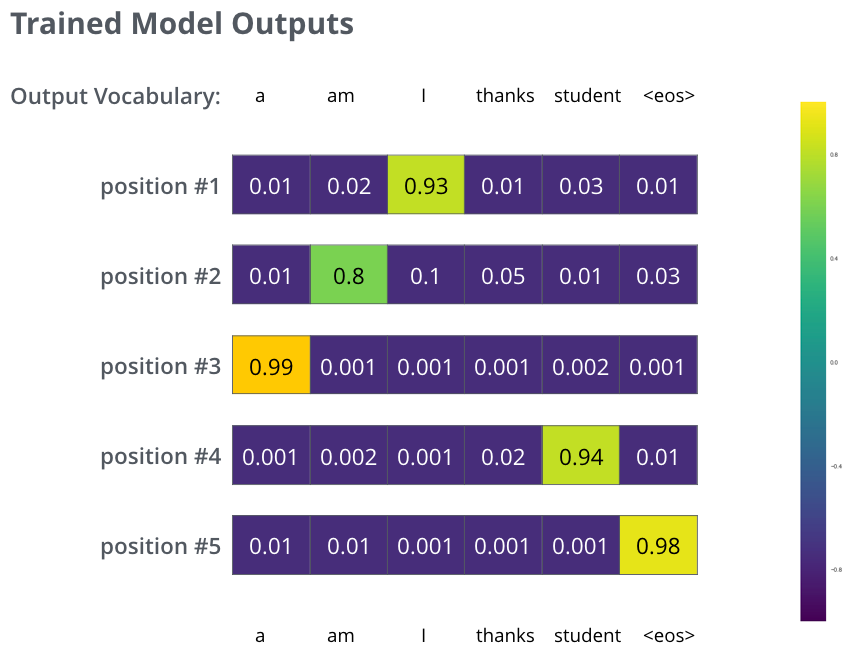
Linear-Softmax
![]()
模型样例