主要包含:机器阅读的起因和发展历史;MRC数学形式;MRC与QA的区别;MRC的常见数据集和关键模型
发展动机
传统NLP任务
1) 词性分析 part-of-speech tagging :判断词性
2) 命名实体识别 named entity recognition 识别实体
3) 句法依存 sytactic parsing 找到词间关系、语法结构信息
4) 指代消解 coreference resolution
阅读理解动机
让机器理解人类语言是AI领域长期存在的问题
阅读理解能综合评估各项NLP任务,是一个综合性任务
阅读理解探索更加深层次的理解
回答问题是检测机器是否读懂文章最好的办法
历史发展
早期系统
1. QUALM系统 Lehnert,1977年
2. 早期数据集 Hirschman,1999年
- 小学文章,3年级-6年级
- 60篇 - 60篇:dev - test
- 只需要返回包含正确答案的句子即可
- who what when where why
3. Deep Read系统 Hirschman,1999年
rule-based bag-of-words,基于规则的词袋模型- 浅层语言处理:词干提取、语义类识别、指代消解
4. QUARC系统 Riloff and Thelen,2000年
- rule-based
- 基于词汇和语义对应
还有3和4的结合(Charniak,2000年),准确率在30%-40%左右。
机器学习时代
1. 三元组
(文章,问题,答案)
2. 两个数据集
MCTest:四选一;660篇科幻小说
ProcessBank:二分类;585问题,200个段落;生物类型文章;需要理解实体关系和事件
3. 传统规则方法
不使用训练数据集
1)启发式的滑动窗口方法
计算word overlap、distance information
2)文本蕴含方法
用现有的文本蕴含系统,把(问题,答案)对转化为一个statement。
3)max-margin 学习框架,使用了很多语言特征:
句法依存、semantic frames、 指代消解、 discourse relation和 词向量等特征。
4. 机器学习方法
机器学习方法比规则方法好,但是任然有很多不足:
1)依赖于现有语言特征工具
- 许多NLP任务没有得到有效解决
- 任务泛化性差,一般在单一领域训练
- 语言特征任务添加了噪声
2)很难模拟人类阅读,难以构建有效特征
3)标记数据太少,难以训练出效果好的统计模型
深度学习时代
深度学习火热于2015年,DeepMind的Hermann大佬提出了一种新型低成本构建大规模监督数据的方法,同时提出了attention-based LSTM。
神经网络效果较好,能更好地在词/句子上做match。
1) CNN/Daily-Mail数据集
- 把文章标题/摘要中的名词mask掉,再提问这个名词
- 使用NER和指代消解等技术
- 半合成的数据集,存在误差,影响发展
2) SQuAD数据集
- 107785问答数据,546文章
- 第一个大规模机器阅读理解数据集
- 推动了很多机器阅读模型的发展
3) 深度学习的优点
- 不依赖于语言特征工具,避免了噪声误差等
- 传统NLP方法特征稀少、难以泛化
- 不用去手动构建特征, 工作重心在模型设计上
任务形式
阅读理解任务看作是一种监督学习任务,目的是学习一种映射关系: \[ f: (p, q) \to a \] 根据答案类型,分为如下四种形式的机器阅读任务。
完形填空
预测一个词汇,一般平均3.5个词汇长度。准确率评估。
四选一
从k个答案中选择一个,一般是一个词、一个短语和一个答案。准确率评估。
Span预测
抽取式问答,预测答案在文章中start和end位置。
Exact Match 评估:准确率。测试集会有多个正确答案,EM匹配一个就好。
F1 score评估:句子单词之间的overlap,忽略字符和a an the。计算最优的F1。 \[
\rm{
F1 = \frac{2*Precision*Recall}{Precision + Recall}
}
\]
自然形式
自然语言回答,没有固定的形式free-form answer。没有明确统一的评估指标。有如下几个:
- BLEU(注意看新文章,好像说这个评测不是很好)
- Meteor
- ROUGE
MRC和QA的比较
机器阅读理解是Question Answering的一个特例。
1) 相同点:问题形式、解决方法和评估方法
2) 不同点
问答系统在于:
- 旨在构建问答系统,依赖于各种资源
- 资源包括:结构化数据、非结构化文本、半结构化表格和其他形式的资源
- QA致力于:寻找和识别有用资源;集成各种资源的信息;研究人们常问的问题
机器阅读在于:
- 文本问答
- 需要去理解文本信息
- 答案只依赖于文章
- 会设计不同类型问题去测试机器对文章不同方面的理解
数据集和模型
机器阅读的发展原因:大规模数据和端到端神经网络模型的出现。
数据集促进了模型,模型又进一步促进了数据集的发展。
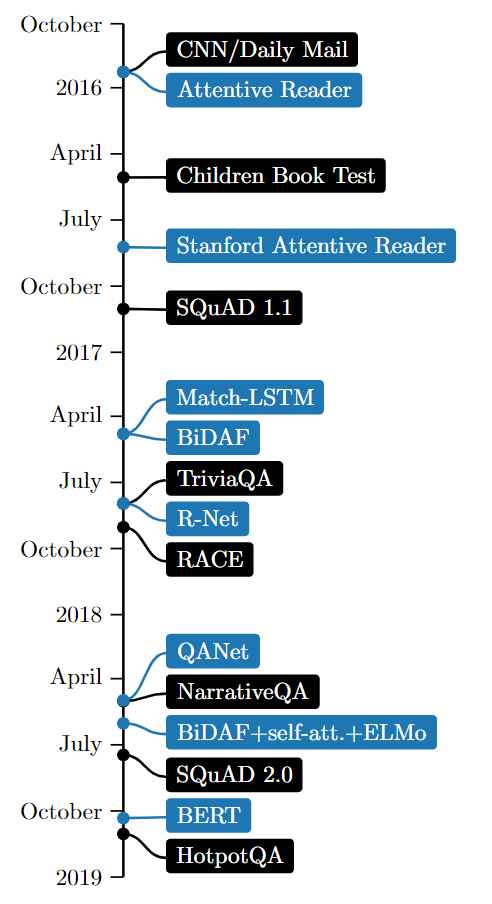
主要模型
- Attentive Reader
- Stanford Attentive Reader
- Match-LSTM
- BiDAF
- R-Net
- QANet
- BiDAF+self-attn+ELMo
- BERT
CNN/Daily Mail
完型填空,名词
MCTest
四选一,MCTest论文
SQuAD 1.1
span预测。SQuAD1.1有如下缺点:
- 问题是根据文章提出的,降低了回答问题的难度
- 答案缺少yes/no、计数、why、how等问题类型
- 答案很短,只有span类型
- 缺少多句推理,SQuAD只需要一个句子便能回答
TriviaQA
- 从web和维基百科中构建,先收集QA,再收集P;更容易构建大规模数据集
- 650k (p, q, a),文章p很长,20倍SQuAD
优点:解决了SQuAD问题依赖于文章的问题缺点:不能保证文章一定包含该问题,这影响训练数据质量
RACE
NarrativeQA
free-form答案形式。NarrativeQA和数据集论文
- 书籍/电影:原文和摘要
- 摘要问答和原文问答,平均长度分别是659和62528
- 如果是原文,需要IR提取相关片段
- free-form 难以评估
SQuAD 2.0
Span预测。加入no-answer。SQuAD 2.0和数据集论文
HotpotQA
113k问答数据,可解释的多步推理问答。HotpotQA和数据集论文
- 要对多个文档进行查找和推理才能回答问题
- 问题多样化,不局限于已有知识库和知识模式
- 提供句子级别的支持推理线索
supporting fact,系统能利用强大的监督知识去推理回答,并对结果作出解释 - 提供了新型模拟比较型问题,来测试 QA 系统提取相关线索、执行必要对比的能力
- 评估方法1:给10个片2个相关,8个不相关;自行识别相关片段并进行回答
- 评估方法2:利用整个维基百科去进行回答

