使用Transformer(Decoder)预训练单向语言模型,再进行有监督数据进行特定任务finetune
背景
问题提出
NLP中,无标注语料很多,有标注的数据很少。
- 很多任务不能从头开始训练(标注数据太少),需要减轻对标注数据的依赖
- 在大规模无标注语料中预训练的语言模型可以提升很多效果
- 从无标注数据中学习一个
good representations,很流行且有效果
从无标注数据中学习到词级以上的意义的难点:
- 没有一个有效的优化目标函数
- 对学习到的
representations没有通用的有效的迁移方法
半监督学习
半监督是指从无监督数据中学习一些通用表示,再做轻微的有监督finetune到各种各样的特定任务中。
1. 无监督特征表示
利用大量的语料和语言模型任务,去学习到一个神经网络。作为后面模型的网络初始参数。
语言模型网络可以使用LSTM和Transformer。Transformer可以解决LSTM的长依赖问题,具有更好的迁移能力。
2. 有监督任务训练
特定任务的监督数据去finetune初始的网络。一般需要根据任务类型加上输出层。
相关研究
1. 语义研究
词向量主要是迁移具有词级别的信息,但更需要其一些词级别以上的语义信息。主要有phrase-level和sentence-level embedding。
2. 无监督预训练
无监督预训练的目的在于为后续任务去初始化一个好的网络参数,而不需要去改变任务的目标。预训练主要是使用语言模型任务,Transformer比LSTM更好,更强的迁移能力和处理长依赖能力。
Ruder大神说NLP的ImageNet时代已经来了,足以说明预训练的重要性。
3. 辅助任务
- 加辅助特征(ELMo):网络的参数需要重新学习
- 辅助训练目标--语言模型和特定任务一起训练:其实无监督预训练已经学习到了语言特征,无需辅助训练目标了
GPT模型
预训练单向语言模型
采用的是单向语言模型,预测下一个词语,采用的是Tansformer的Decoder。
![]()
在Decoder之外加上线性层去预测下一个单词,训练语言模型任务。
![]()
迁移到下游监督任务
预训练的Tansformer已经具有处理语言的能力,再加上输出层,并且监督finetune,则可以达到一个不错的效果。如下
![]()
各种任务组织方式
利用traversal-style方法,把结构化数据处理成一个序列。每个序列都有一个开始和结束符号,也有分解符号,都是随机初始化的。
![]()
分类任务
开始符号 -- 文本 -- 结束符号
文本蕴含
开始 -- 前提 -- 分界 -- 假设 -- 结束
相似性
相似度计算与顺序无关,所以加了两个
问答和常识推理
文章和问题组成上下文,与每一个可能的答案作为拼接。一共有多组
分析
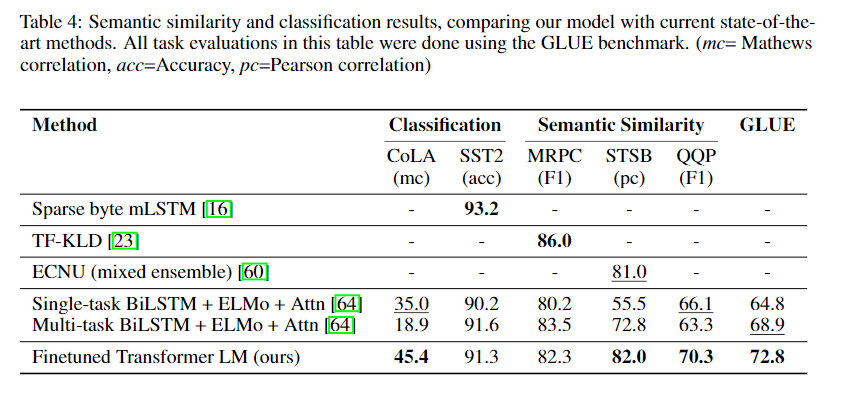
效果
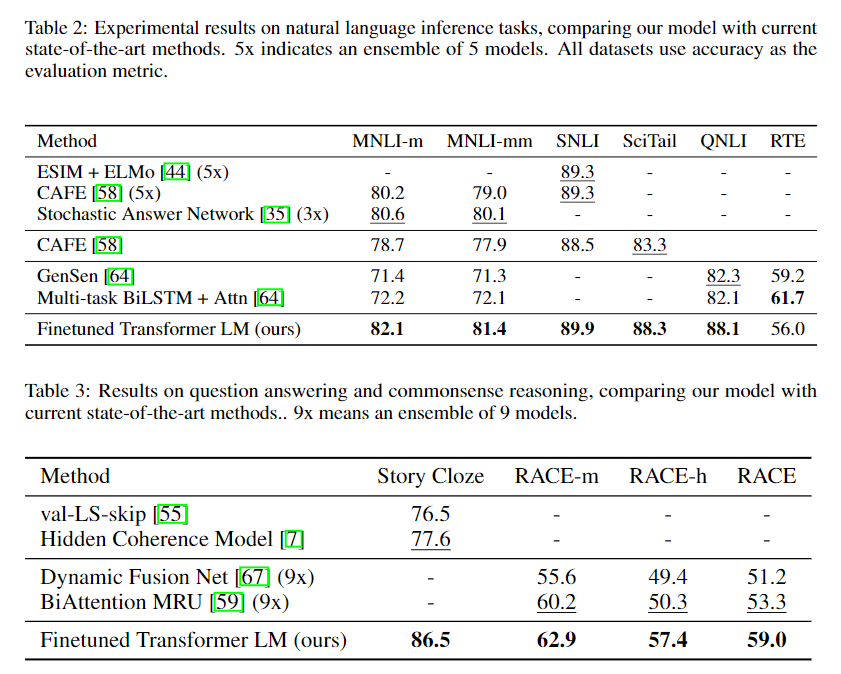
参数分析
- 右图:
zero-shot上Transformer的效果是比LSTM好的 - 左图:可以知道Transformer层数越多效果也越好