常年SQuAD榜单排名第一的模型。QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
论文模型
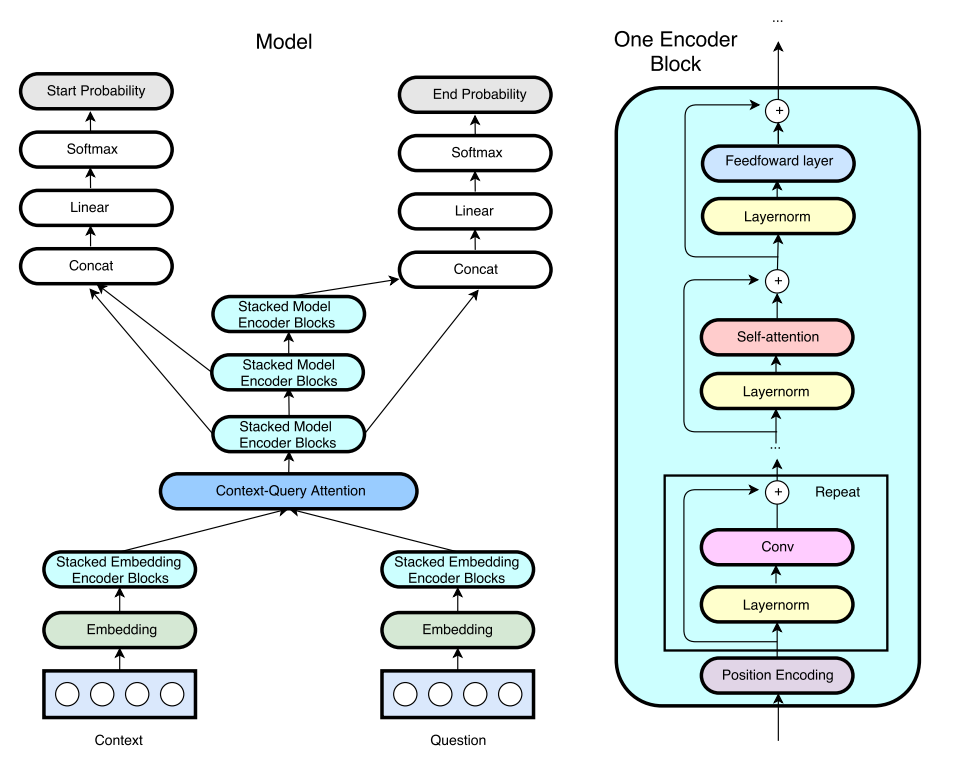
概览
机器阅读任务就不说了。这个模型的主要创新点在于
- 卷积(可分离卷积)捕捉局部信息 (并行计算,加速)
- Self-Attention捕捉全局信息
- 数据扩增
一个Encoder Block主要是,其中Transformer的EncoderBlock只有Attention和FFN,没有卷积。
- Positional Encoder
- 可分离卷积 (多个,提高内存效率和泛化性)
- Self-Attention
- 前向神经网络
Input Embedding
词向量
Glove 300维,Fix;UNK词向量可以训练
字向量
- CNN字符向量,200维,可以训练
- 每个单词的字符最多16个
- 对单词的16个字符的向量过卷积(可分离卷积)
- 选择所有字符中最大的向量作为单词的最终字符向量
拼接
对词向量和字符向量拼接起来,\([x_w;x_c] \in \mathcal{R}^{d_w+d_c}\)。再过两层的HighwayNetwork,得到最终的单词向量表示。
Embedding Encoder
每一个Encoder块是由卷积、Self-Attention、全连接层组成,一共有4个Encoder块。输入向量维数是\(d=500(200+300)\),输出是\(d=128\)
- 可分离卷积:
kernal size=7,d = 128。变成128维向量 - Self-Attention:8头注意力,键值对注意力
- 全连接:输出也是128
- QANet:层归一化+残差连接:\(f(\rm{LayerNorm}(x)) + x\)
- Transformer 是
Add&Norm,\(\rm{LayerNorm(f(x) +x)}\)
Attention Layer
Context: \(n\)个单词,Question:m个单词。\(C \in \mathcal{R}^{n\times d}\),\(Q \in \mathcal{R}^{m \times d}\)
关联性矩阵
采用的是BiDAF的计算策略: \[ S = f(q, c) = W_0 [q, c, q \odot c] \in \mathcal{R} ^{n \times m} \] DCN: \(S = C \cdot Q^T \in \mathcal{R}^{n \times m}\)
Context2Query Attention
C2Q的attention weights,对行做softmax \[ A^Q = \rm{softmax}(S) \in \mathcal{R}^{n \times m} \] C2Q Attention(Context) \[ S^C = A^Q \cdot Q \in \mathcal{R} ^{n \times d} \] Query2Context Attention
Q2C Attention weights,对列做Softmax \[ A^C = \rm{softmax}(S^T) \in \mathcal{R}^{m \times n} \] Q2C Attention(Query) \[ S^Q = A^C \cdot C \in \mathcal{R}^{m \times d} \] Context的Coattention,参考自DCN的Coattention \[ C^C = A^Q \cdot S^Q \in \mathcal{R}^{n \times d} \] 最终得到两个对Context的编码
- 普通Attention:\(A = S^C \in \mathcal{R}^{n \times d}\)
- Coattention:\(B = C^C \in \mathcal{R}^{n \times d}\)
Model Encoder
输入是3个关于Context的矩阵信息:
- 原始Context:\(C \in \mathcal{R}^{n\times d}\)
- Context的Attention: \(A \in \mathcal{R}^{n\times d}\)
- Context的Coattention:\(B \in \mathcal{R}^{n \times d}\)
每个单词的编码信息为上面三个矩阵的一个拼接: \[ f(w) = [c, a, c \odot a, c \odot b] \] 一个有7个Encoder-Block,每个Encoder-Block:2个卷积层、Self-Attention、FFN。其它参数和Embedding Encoder一样。
一共有3个Model-Encoder,共享所有参数。输出依次为\(M_0, M_1, M_2\)
Output Layer
这一层是和特定任务相关的。输出各个位置作为开始和结束位置的概率: \[ p^1 = \rm{softmax}(W_1[M_0; M_1]), \quad p^2 = \rm{softmax}(W_1[M_0; M_2]) \] 目标函数 \[ L(\theta) = -\frac{1}{N} \sum_{i}^N [\log(p^1_{y_i^1}) + \log(p^2_{y_i^2})] \]

