参数初始化、数据预处理、逐层归一化、各种优化方法、超参数优化。
任何数学技巧都不能弥补信息的缺失。本文介绍网络优化方法
神经网络的问题
神经网络有很强的表达能力。但有优化问题和泛化问题。主要通过优化和正则化来提升网络。
优化问题
优化问题的难点
- 网络是一个非凸函数,深层网络的梯度消失问题,很难优化
- 网络结构多样性,很难找到通用优化方法
- 参数多、数据大,训练效率低
- 参数多,存在高维变量的非凸优化
低维空间非凸优化:存在局部最优点,难在初始化参数和逃离局部最优点
高维空间非凸优化:难在如何逃离鞍点。 鞍点是梯度为0,但一些维度是最高点,另一些维度是最低点。
梯度下降法很难逃离鞍点。
梯度下降法面临的问题
- 如何初始化参数
- 预处理数据
- 如何选择合适的学习率,避免陷入局部最优
泛化问题
神经网络拟合能力很强,容易过拟合。解决过拟合的5个方法
参数初始化
对称权重问题
全0产生的对称权重问题
参数千万不能全0初始化。如果全0初始化,会导致隐层神经元激活值都相同,导致深层神经元没有区分性。这就是对称权重现象。
通俗点:
- 每个神经元输出相同 -- BP时梯度也相同 -- 参数更新也相同
- 神经元之间就失去了不对称性的源头
应该对每个参数随机初始化,打破这个对称权重现象,使得不同神经元之间区分性更好。
参数区间的选择
参数太小时
使得Sigmoid激活函数丢失非线性的能力。在0附近近似线性,多层神经网络的优势也不存在。
参数太大时
Sigmoid的输入会变得很大,输出接近1。梯度直接等于0。
选择一个合适的初始化区间非常重要。如果,一个神经元输入连接很多,那么每个输入连接上的权值就应该小一些。
高斯分布初始化
高斯分布也就是正态分布。
初始化一个深度网络,比较好的方案是保持每个神经元输入的方差为一个常量。
如果神经元输入是\(n_{in}\), 输出是\(n_{out}\), 则按照\(N(0, \sqrt{\frac {2}{n_{in} + n_{out}}})\) 来初始化参数。
均匀分布初始化
在\([-r, r]\)区间内,采用均匀分布来初始化参数
Xavier均匀分布初始化
会自动计算超参数\(r\), 来对参数进行\([-r, r]\)均匀分布初始化。
设\(n^{l}\)为第\(l\) 层神经元个数, \(n^{l-1}\) 是第\(l-1\)层神经元个数。
logsitic激活函数 :\(r = \sqrt{\frac{6}{n^{l-1} + n^l}}\)tanh激活函数: \(r = 4 \sqrt{\frac{6}{n^{l-1} + n^l}}\)
\(l\)层的一个神经元\(z^l\),收到\(l-1\)层的\(n^{l-1}\)个神经元的输出\(a_i^{l-1}\), \(i \in [1, n^{(l-1)}]\)。 \[ z^l = \sum_{i=1}^n w_i^l a_i^{l-1} \] 为了避免初始化参数使得激活值变得饱和,尽量使\(z^l\)处于线性区间,即神经元的输出\(a^l = f(z^l) \approx z^l\)。
假设\(w_i^l\)和\(a_i^{l-1}\)相互独立,均值均为0,则a的均值为 \[ E[a^l] = E[\sum_{i=1}^n w_i^l a_i^{l-1}] = \sum_{i=1}^d E[\mathbf w_i] E[a_i^{l-1}] = 0 \] \(a^l\)的方差 \[ \mathrm{Var} [a^l] = n^{l-1} \cdot \mathrm{Var} [w_i^l] \cdot \mathrm{Var} [a^{l-1}_i] \] 输入信号经过该神经元后,被放大或缩小了\(n^{l-1} \cdot \mathrm{Var} [w_i^l]\)倍。
为了使输入信号经过多层网络后,不被过分放大或过分缩小,应该使\(n^{l-1} \cdot \mathrm{Var} [w_i^l]=1\)。
综合前向和后向,使信号在前向和反向传播中都不被放大或缩小,综合设置方差: \[ \mathrm{Var} [w_i^l] = \frac{2} {n^{l-1} + n^l} \]
数据预处理
为什么要归一化
每一维的特征的来源和度量单位不同,导致特征分布不同。
未归一化数据的3个坏处
- 样本之间的欧式距离度量不准。取值范围大的特征会占主导作用。类似于信息增益和信息增益比
- 降低神经网络的训练效率
- 降低梯度下降法的搜索效率
未归一化对梯度下降的影响
- 取值范围不同:大多数位置的梯度方向不是最优的,要多次迭代才能收敛
- 取值范围相同:大部分位置的梯度方向近似于最优搜索方向,每一步都指向最小值,训练效率大大提高
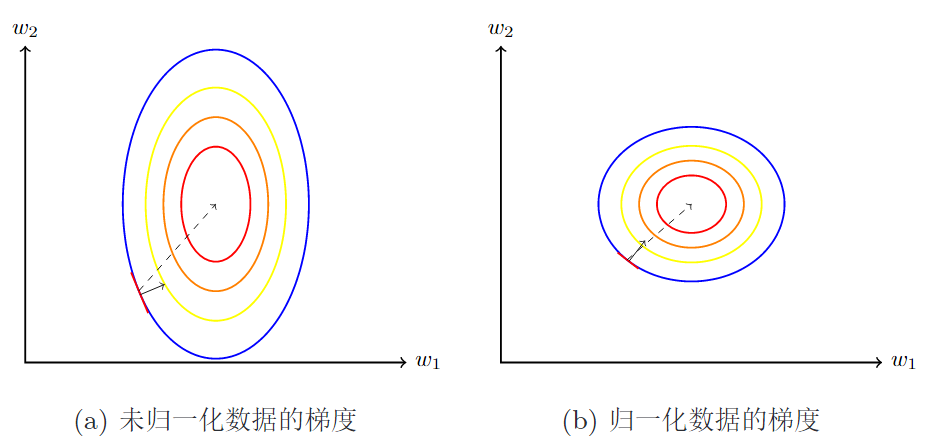
归一化要做的事情
- 各个维度特征归一化到同一个取值区间
- 消除不同特征的相关性
标准归一化
实际上是由中心化和标准化结合的。 把数据归一化到标准正态分布。\(X \sim N(0, 1^2)\)
计算均值和方差 \[
\mu = \frac{1}{N} \sum_{i=1}^n x^{(i)} \\
\sigma^2 = \frac{1}{N} \sum_{i=1}^n(x^{(i)} - \mu)^2
\] 归一化数据,减均值除以标准差。如果\(\sigma = 0\), 说明特征没有区分性,应该直接删掉。 \[
\hat x^{(i)} = \frac {x^{(i)} - \mu}{ \sigma }
\] 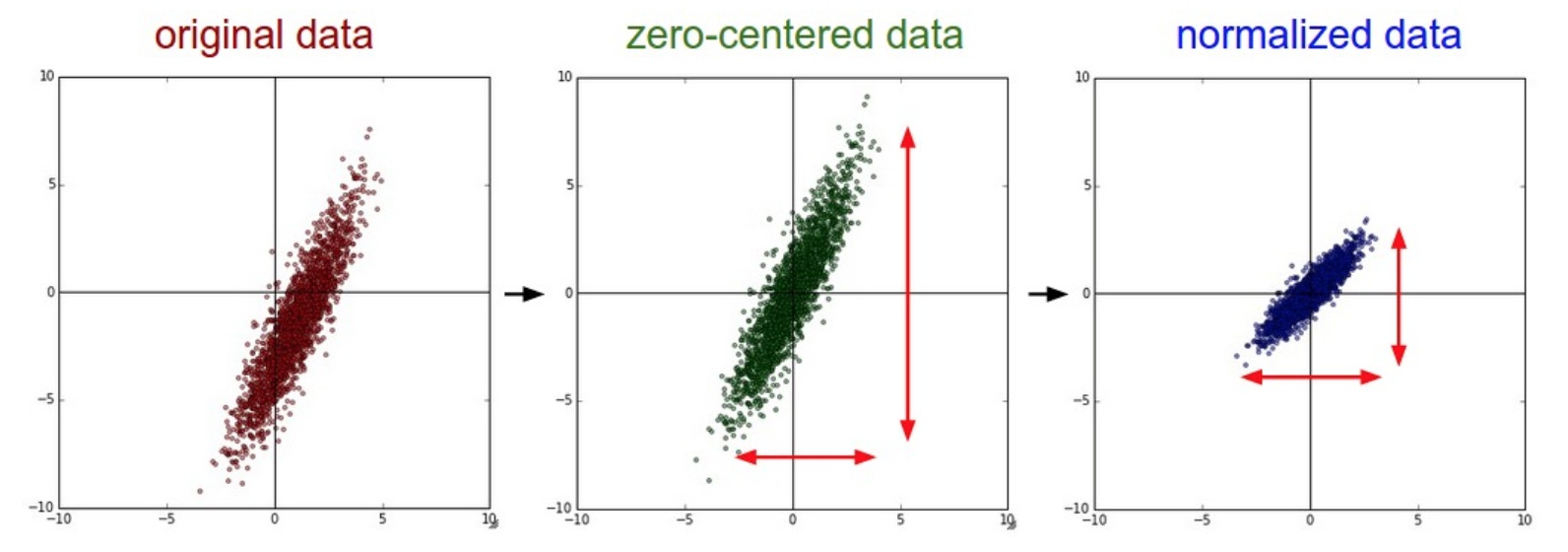
缩放归一化
把数据归一化到\([0, 1]\) 或者\([-1, 1]\) 直接。 \[ x^{(i)} = \frac {x^{(i)} - \min(x)}{\max(x) - \min (x)} \]
白化
白化用来降低输入数据特征之间的冗余性。白化主要使用PCA来去掉特征之间的相关性。我的白化笔记
处理后的数据
- 特征之间相关性较低
- 所有特征具有相同的方差
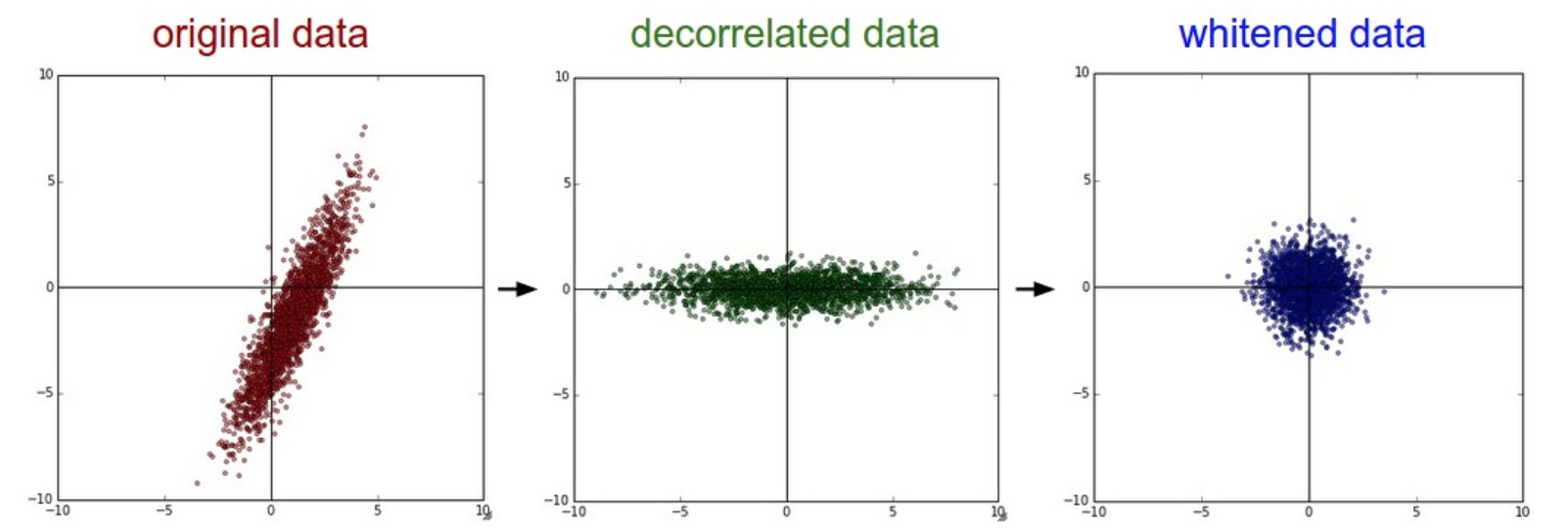
白化的缺点
可能会夸大数据中的噪声。所有维度都拉到了相同的数值范围。可能有一些差异性小、但大多数是噪声的维度。可以使用平滑来解决。
逐层归一化
原因
深层神经网络,中间层的输入是上一层的输出。每次SGD参数更新,都会导致每一层的输入分布发生改变。
像高楼,低楼层发生较小偏移,就会导致高楼层发生较大偏移。
如果某个层的输入发生改变,其参数就需要重新学习,这也是内部协变量偏移问题。
在训练过程中,要使得每一层的输入分布保持一致。简单点,对每一个神经层进行归一化。
- 批量归一化
- 层归一化
- 其它方法
批量归一化
针对每一个维度,对每个batch的数据进行归一化+缩放平移。
批量归一化Batch Normalization ,我的BN详细笔记。 对每一层(单个神经元)的输入进行归一化 \[
\begin{align}
& \mu = \frac{1}{m} \sum_{i=1}^m x_i & \text{求均值} \\
& \sigma^2 = \frac{1}{m} \sum_{i=1}^m (x_i - \mu)^2 & \text{求方差} \\
& \hat x = \frac{x - E(x)} {\sqrt{\sigma^2 + \epsilon}} & \text{标准归一化} \\
& y = \gamma \hat x+ \beta & \text{缩放和平移}
\end{align}
\] 缩放参数\(\gamma\) ,和平移参数 \(\beta\) 的作用
- 强行归一化会破坏刚学习到的特征。用这两个变量去还原应该学习到的数据分布
- 归一化会聚集在0处,会减弱神经网络的非线性性质。缩放和平移解决这个问题
注意:
- BN是对中间层的单个神经元进行归一化
- 要求批量样本数量不能太小,否则难以计算单个神经元的统计信息
- 如果层的净输入的分布是动态变化的,则无法使用批量归一化。如循环神经网络
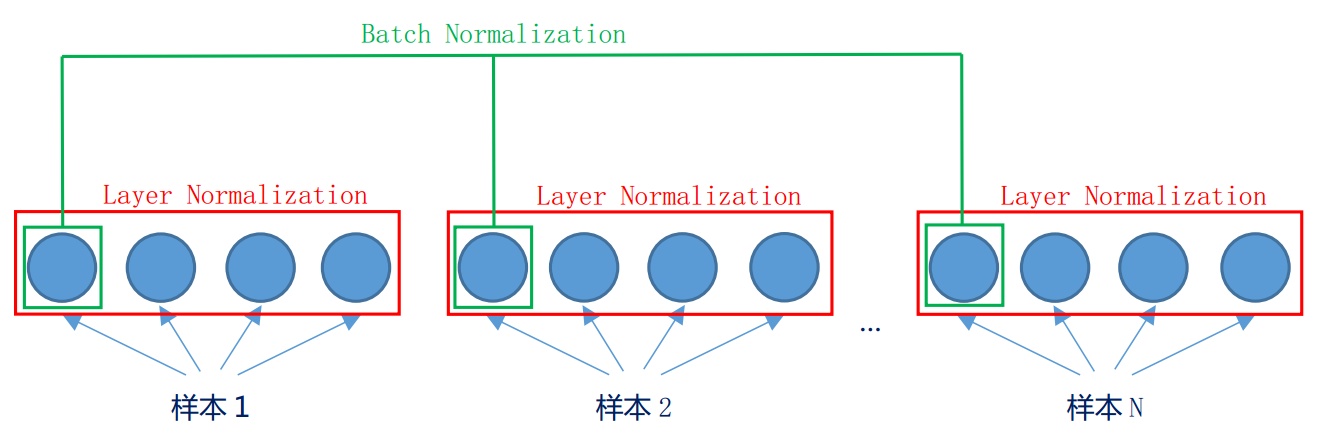
层归一化
对每个样本,对所有维度做一个归一化,即对同层的所有神经元的输入做归一化。
层归一化是对一个中间层的所有神经元进行归一化- 批量归一化是对一个中间层的单个神经元进行归一化
设第\(l\)层的净输入为\(\mathbf z^{(l)}\), 求第\(l\)层所有输入的均值和方差 \[
\begin{align}
& \mu^{(l)} = \frac{1}{n^l} \sum_{i=1}^{n^l} z_i^{(l)} & \text{第l层输入的均值} \\
& \sigma^{(l)^2} = \frac{1}{n^l} \sum_{i=1}^{n^l} (z_i^{(l)} - \mu^{(l)})^2 & \text{第l层输入的方差} \\
\end{align}
\] 层归一化 如下,其中\(\gamma, \beta\)是缩放和平移的参数向量,与\(\mathbf z^{(l)}\)维数相同 \[
\hat {\mathbf z}^{(l)} = \rm{LayerNorm}_{\gamma, \beta} (\mathbf z^{(l)})
= \frac {\mathbf z^{(l) - \mu^{(l)}}}{\sqrt{\sigma ^{(l)^2} + \epsilon}} \cdot \gamma + \beta
\] 层归一化的RNN \[
\mathbf z_t = U\mathbf h_{t-1} + W \mathbf x_t \\
\mathbf h_t = f (\rm{LN}_{\gamma, \beta}(\mathbf z_t)))
\] RNN的净输入一般会随着时间慢慢变大或变小,导致梯度爆炸或消失。
层归一化的RNN可以有效缓解梯度消失和梯度爆炸。
批归和层归对比
思想类似,都是标准归一化 + 缩放和平移。
- 批量归一化:针对每一个维度,对batch的所有数据做归一化
- 层归一化:针对每一个样本,对所有维度做归一化。可以用在RNN上,减小梯度消失和梯度爆炸。
其它归一化
权重归一化
对神经网络的连接权重进行归一化。
局部相应归一化
对同层的神经元进行归一化。但是局部响应归一化,用在激活函数之后,对邻近的神经元进行局部归一化。
梯度下降法的改进
梯度下降法
Mini-Batch梯度下降法。设\(f(\mathbf x ^{(i)}, \theta)\) 是神经网络。
在第\(t\)次迭代(epoch)时,选取\(m\)个训练样本\(\{\mathbf x^{(i)}, y^{(i)} \}_{i=1}^m\)。 计算梯度\(\mathbf g_t\) \[ \mathbf g_t = \frac{1}{m} \sum_{i \in I_t} \frac {\partial J(y^{(i)}, f(\mathbf x ^{(i)}, \theta))}{\partial \theta} + \lambda \|\theta\| ^2 \] 更新参数,其中学习率\(\alpha \ge 0\) : \[ \theta_t = \theta_{t-1} - \alpha \mathbf g_t \]
\[ \theta_t = \theta_{t-1}+ \Delta \theta_t \]
1. BGD
Batch Gradient Descent
意义:每一轮选择所有整个数据集去计算梯度更新参数
优点
- 凸函数,可以保证收敛到全局最优点;非凸函数,保证收敛到局部最优点
缺点
- 批量梯度下降非常慢。因为在整个数据集上计算
- 训练次数多时,耗费内存
- 不允许在线更新模型,例如更新实例
2. SGD
Stochastic Gradient Descent
意义:每轮值选择一条数据去计算梯度更新参数
优点
- 算法收敛快(BGD每轮会计算很多相似样本的梯度,冗余的)
- 可以在线更新
- 有一定几率跳出比较差的局部最优而到达更好的局部最优或者全局最优
缺点
- 容易收敛到局部最优,并且容易困在鞍点
3. Mini-BGD
Mini-Batch Gradient Descent
意义: 每次迭代只计算一个mini-batch的梯度去更新参数
优点
- 计算效率高,收敛较为稳定
缺点
- 更新方向依赖于当前batch算出的梯度,不稳定
4. 梯度下降法的难点
- 学习率\(\alpha\)难以选择。太小,导致收敛缓慢;太大,造成较大波动妨碍收敛
- 学习率一直相同是不合理的。出现频率低的特征,大学习率;出现频率小的特征,小学习率
- 按迭代次数和loss阈值在训练时去调整学习率。然而次数和阈值难以设定,无法适应所有数据
- 很难逃离鞍点。梯度为0,一些特征是最高点(上升),一些特征是最低点(下降)
- 更新方向依赖于当前batch算出的梯度,不稳定
主要通过学习率递减和动量法来优化梯度下降法。
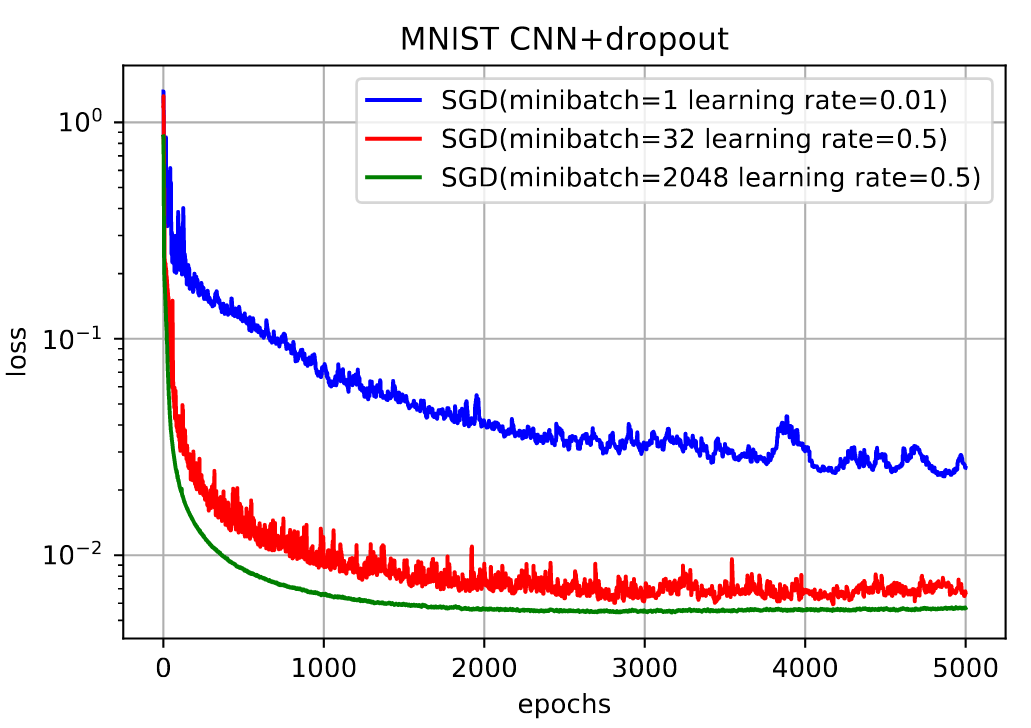
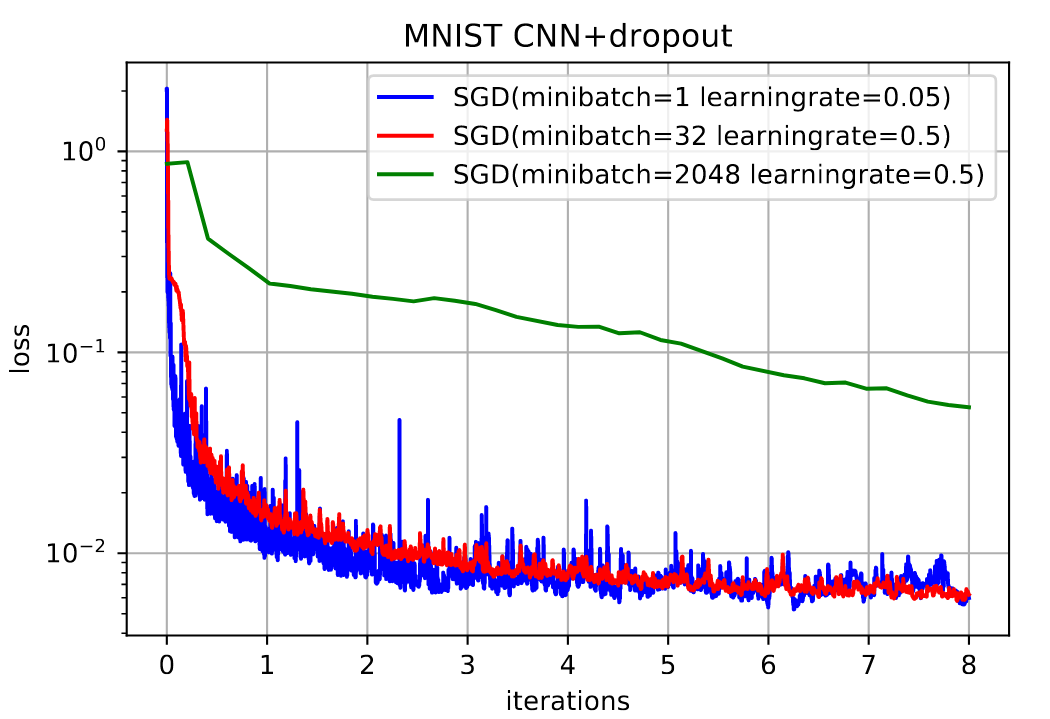
可以看出
- SGD,整体下降,但局部会来回震荡
- MBGD,一个batch来说,batch越大,下降越快,越平滑
- MBGD,整体来说,batch越小,下降越明显
学习率递减
0 指数加权平均
求10天的平均温度,可以直接利用平均数求,每天的权值是一样的,且要保存所有的数值才能计算。 \[ v_{avg} = \frac {v_1 + \cdots + v_{100}}{100} \] 设\(v_t\)是到第t天的平均温度,\(\theta_t\)是第t天的真实温度,\(\beta=0.9\)是衰减系数。
则有指数加权平均:
\[
v_t = \beta * v_{t-1} + (1-\beta) \theta_t
\]
\[ v_{100} = 0.1 \cdot \theta_{100} + 0.1(0.9)^1 \cdot \theta_{99} + 0.1 (0.9)^2 \cdot \theta_{98} + 0.1(0.9)^3 \cdot \theta_{97} + \ldots \]
离当前越近,权值越大。越远,权值越小(指数递减),也有一定权值。
1. 按迭代次数递减
设置\(\beta = 0.96\)为衰减率
反时衰减 \[
\alpha_t = \alpha_0 \cdot \frac {1} {1 + \beta \times t}
\] 指数衰减 : \[
\alpha_t = \alpha_0 \cdot \beta^t
\] 自然指数衰减 \[
\alpha_t = \alpha_0 \cdot e^{-\beta \cdot t}
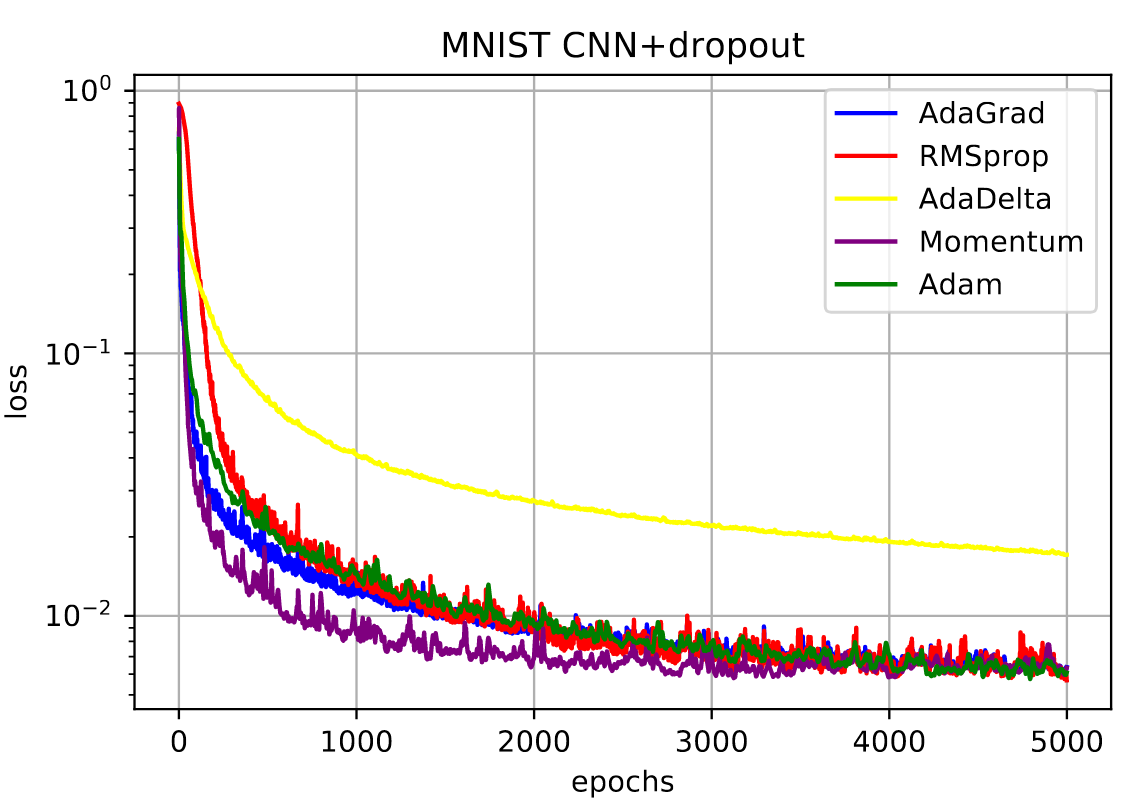
\] 2. AdaGrad
Adaptive Gradient
意义:每次迭代时,根据历史梯度累积量来减小学习率,减小梯度。梯度平方的累计值来减小梯度
初始学习率\(\alpha_0\)不变,实际学习率减小。\(\alpha = \frac {\alpha_0} {\sqrt {G_t + \epsilon}}\) \[ G_t = \sum_{i=1}^t g_i^2 \]
\[ \Delta \theta_t = - \frac {\alpha_0}{\sqrt {G_t + \epsilon}} \cdot g_t \]
优点
- 累积梯度\(G_t\)的\(\frac{1}{\sqrt{G_t + \epsilon}}\)实际上构成了一个约束项
- 前期\(G_t\)较小, 约束值大,能够放大梯度
- 后期\(G_t\)较大, 约束值小,能够约束梯度
- 适合处理稀疏梯度
缺点
- 经过一些迭代,学习率会变非常小,参数难以更新。过早停止训练
- 依赖于人工设置的全局学习率\(\alpha_0\)
- \(\alpha_0\)设置过大,约束项大,则对梯度的调节太大
3. RMSprop
意义:计算梯度\(\mathbf g_t\)平方的指数递减移动平均, 即梯度平方的平均值来减小梯度 \[
G_t = \beta G_{t-1} + (1-\beta) \cdot \mathbf g_t^2
\]
\[ \Delta \theta_t = - \frac {\alpha_0}{\sqrt {G_t + \epsilon}} \cdot \mathbf g_t \]
优点
- 解决了AdaGrad学习率一直递减过早停止训练的问题,学习率可大可小
- 训练初中期,加速效果不错,很快;训练后期,反复在局部最小值抖动
- 适合处理非平稳目标,对于RNN效果很好
缺点
- 依然依赖于全局学习率\(\alpha_0\)
4. AdaDelta
意义 不初始化学习率。计算梯度更新差平方的指数衰减移动平均来作为分子学习率, \[
G_t = \beta G_{t-1} + (1-\beta) \cdot \mathbf g_t^2
\]
\[ \Delta X_{t-1}^2 = \beta \Delta X_{t-2}^2 + (1-\beta) \Delta \theta_{t-1}^2 \]
\[ \Delta \theta_t = - \frac { \sqrt {\Delta X_{t-1}^2 + \epsilon}}{\sqrt {G_t + \epsilon}} \cdot \mathbf g_t \]
优点
- 初始学习率\(\alpha_0\)改成了动态计算的\(\sqrt {\Delta X_{t-1}^2 + \epsilon}\) ,一定程度上平抑了学习率的波动。
动量法
结合前面更新的方向和当前batch的方向,来更新参数。
解决了MBGD的不稳定性,增加了稳定性。可以加速或者减速。
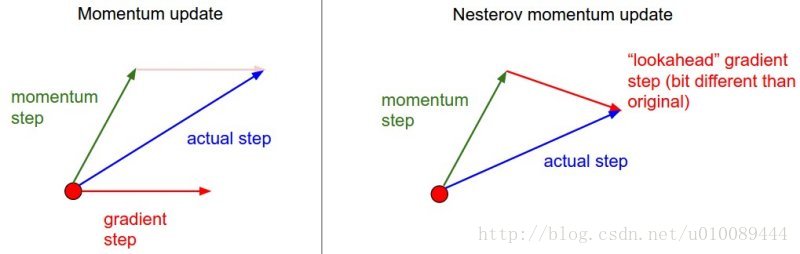
1. 普通动量法
设\(\rho = 0.9\)为动量因子,计算负梯度的移动加权平均 \[
\Delta \theta_t = \rho \cdot \Delta \theta_{t-1} - \alpha \cdot \mathbf g_t
\]
当前梯度与最近时刻的梯度方向:
- 前后梯度方向一致:参数更新幅度变大,会加速
- 前后梯度方向不一致:参数更新幅度变小,会减速
优点:
- 迭代初期,梯度方向一致,动量法加速,更快到达最优点
- 迭代后期,梯度方向不一致,在收敛值附近震荡,动量法会减速,增加稳定性
当前梯度叠加上上次的梯度,可以近似地看成二阶梯度。
Adam
Adaptive Momentum Estimation = RMSProp + Momentum, 即自适应学习率+稳定性(动量法)。
意义:计算梯度\(\mathbf g_t\)的指数权值递减移动平均(动量),计算梯度平方\(\mathbf g_t^2\)的指数权值递减移动平均(自适应alpha)
设\(\beta_1 = 0.9\), \(\beta_2 = 0.99\) 为衰减率 \[ M_t = \beta_1M_{t-1} + (1-\beta_1) \mathbf g_t \quad \quad \sim E(\mathbf g_t) \]
\[ G_t = \beta_2 G_{t-1} + (1-\beta_2) \mathbf g_t^2 \quad \quad \sim E(\mathbf g_t^2) \]
\[ \hat M_t = \frac {M_t}{1 - \beta_1^t}, \quad \hat G_t = \frac{G_t}{1 - \beta_2^t} \quad \quad \text{初始化偏差修正} \]
\[ \Delta \theta_t = - \frac {\alpha_0}{\sqrt{\hat G_t + \epsilon}} \hat M_t \]
优点
- 有RMSprop的处理非稳态目标的优点,有Adagrad处理稀疏梯度的优点
- 对内存需求比较小,高效地计算
- 为不同的参数计算不同的自适应学习率
- 适用于大多数的非凸优化
- 超参数好解释,只需极少量的调参
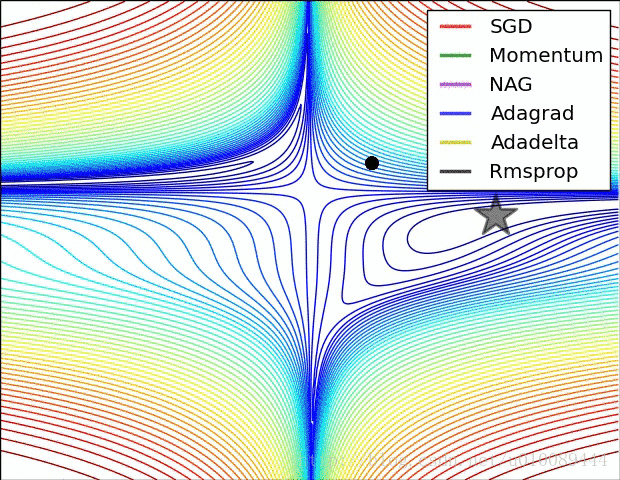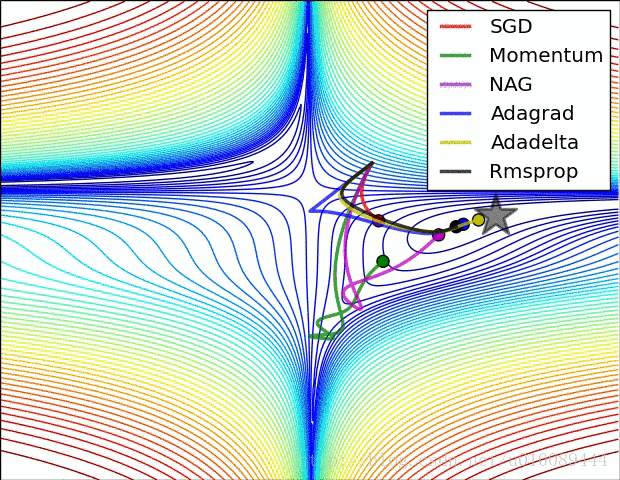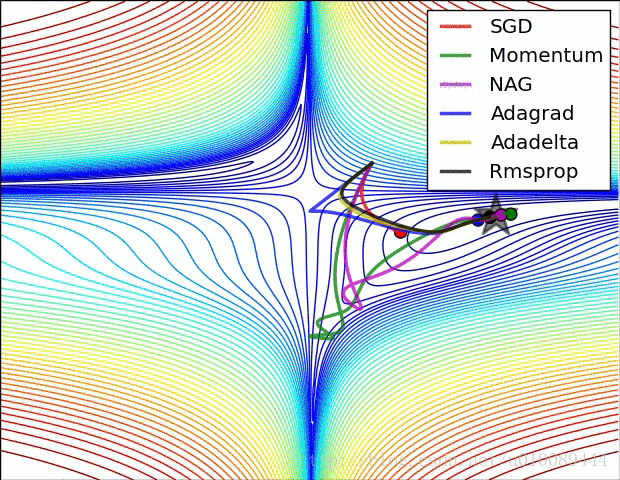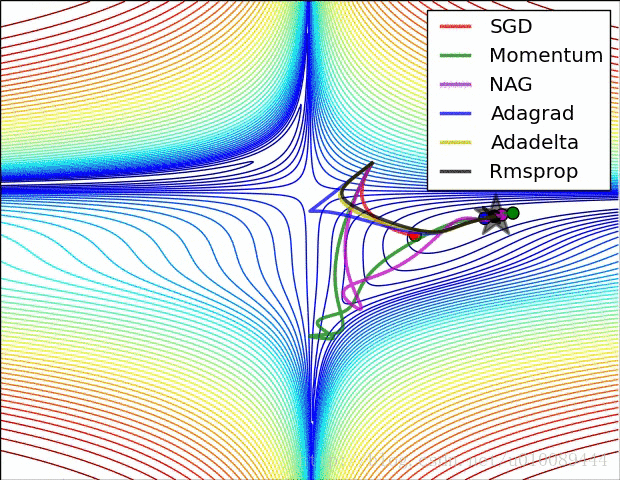
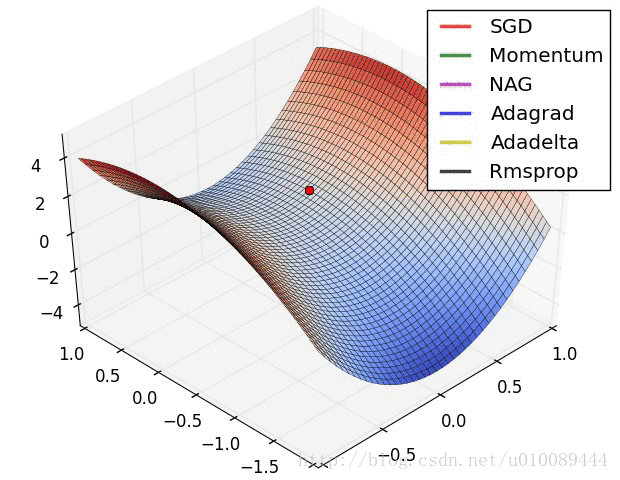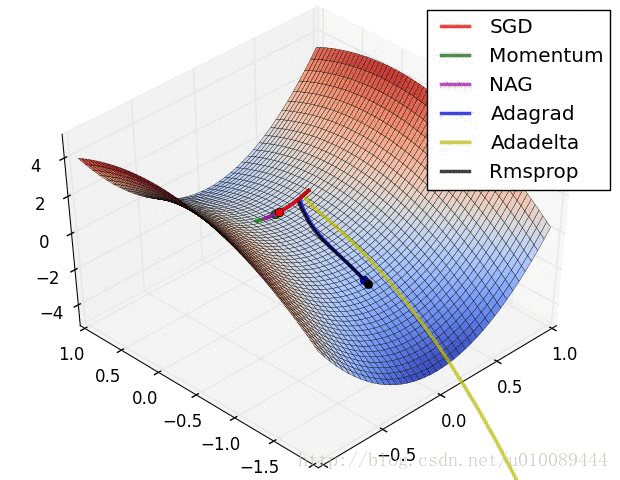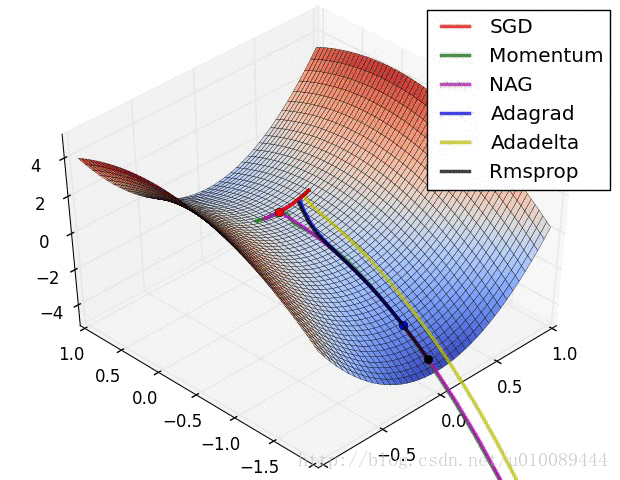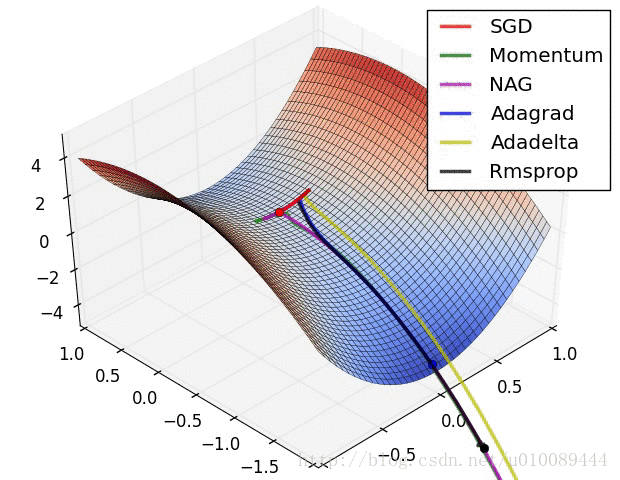
梯度截断
一般按模截断,如果\(\|\mathbf g_t\|^2 > b\), 则 \[ \mathbf g_t = \frac{b}{\|\mathbf g_t\|} \mathbf g_t \]
超参数优化
优化内容和难点
优化内容
- 网络结构:神经元之间连接关系、层数、每层的神经元数量、激活函数类型等
- 优化参数:优化方法、学习率、小批量样本数量
- 正则化系数
优化难点
- 参数优化是组合优化问题,没有梯度下降法来优化,没有通用的有效的方法
- 评估一组超参数配置的实际代价非常高
配置说明
- 有\(K\)个超参数, 每个超参数配置表示为1个向量\(\mathbf x \in X\)
- \(f(\mathbf x)\) 是衡量超参数配置\(\mathbf x\)效果的函数
- \(f(\mathbf x)\)不是\(\mathbf x\)的连续函数,\(\mathbf x\)也不同。 无法使用梯度下降等优化方法
超参数设置-搜索
超参数设置:人工搜索、网格搜索、随机搜索。
缺点:没有利用到不同超参数组合之间的相关性,搜索方式都比较低效。
1. 网格搜索
对于\(K\)个超参数,第\(k\)个参数有\(m_k\)种取值。总共的配置数量: \[ N = m_1 \times m_2 \times \cdots \times m_K \] 如果超参数是连续的,可以根据经验选择一些经验值,比如学习率 \[ \alpha \in \{0.01, 0.1, 0.5, 1.0\} \] 对这些超参数的不同组合,分别训练一个模型,测试在开发集上的性能。选取一组性能最好的配置。
2. 随机搜索
有的超参数对模型影响力有限(正则化),有的超参数对模型性能影响比较大。网格搜索会遍历所有的可能性。
随机搜索:对超参数进行随机组合,选择一个性能最好的配置。
优点:比网格搜索好,更容易实现,更有效。
贝叶斯优化
根据当前已经试验的超参数组合,来预测下一个可能带来的最大收益的组合。
贝叶斯优化过程:根据已有的N组试验结果来建立高斯过程,计算\(f(\mathbf x)\)的后验分布。
动态资源分配
在早期阶段,估计出一组配置的效果会比较差,则中止这组配置的评估。把更多的资源留给其他配置。
这是多臂赌博机的泛化问题:最优赌博机。在给定有限次数的情况下,玩赌博机,找到收益最大的臂。
神经架构搜索
通过神经网络来自动实现网络架构的设计。
- 变长字符串 -- 描述神经网络的架构
- 控制器 -- 生成另一个子网络的架构描述
- 控制器 -- RNN来实现
- 控制器训练 -- 强化学习来完成
- 奖励信号 -- 生成的子网络在开发集上的准确率

