本文概要:介绍DMN的基本原理,使用PyTorch进行实现一个简单QA
论文:Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
模型简介
概要说明
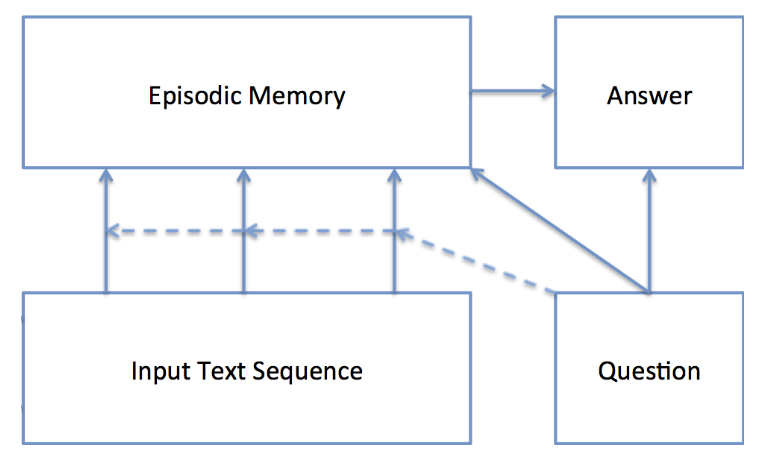
许多NLP问题都可以看做一个Question-Answer问题。Dynamic Memory Network 由4部分组成。
输入模块
对输入的句子facts(先embedding)使用GRU 进行编码,得到encoded_facts,给到后面的情景记忆模块。
问题模块
对输入的问题question使用GRU进行编码,得到encoded_question, 给到后面的情景记忆模块 和回答模块 。
情景记忆模块
Episodic Memory Module由memory和attention组成。
attention:会选择更重要的facts
memory:根据question、facts和 旧memory来生成新momery 。初始:memory=encoded_question
会在facts上迭代多次去计算memory。 每一次迭代会提取出新的信息。
输出最终的momery, 给到回答模块。
回答模块
memory + question, 在GRUCell上迭代原本的回答长度次, 得到最终的预测结果。
输入模块
输入
一个句子,有\(T_I\) 个单词
\(T_I\) 个句子,则把这些句子合并成一个大句子。在每个句子的末尾添加一个句子结束标记</s>。如上图蓝色的部分
GRU计算隐状态
句子过RNN时,对于每一时刻\(t\) 的单词\(w_t\) ,有\(h_t\) : \[
h_t = \rm{RNN}(w_t, h_{t-1})
\] 输出
使用RNN的h = hidden states 作为输入句子的向量表达,也就是encoded_facts
一个句子,输出所有时刻的\(h_t\)
多个句子,输出每个句子结束标记</s>时刻的\(h_t\) 。
问题模块
输入
输入一个句子question,有\(T_Q\) 个单词。
GRU计算隐状态 \[
q_t = \rm{RNN}(w_t^Q, q_{t-1})
\] 输出Q编码
最后时刻的隐状态\(q_{T_Q}\) 作为句子的编码。
情景记忆模块
总体思路
记忆模块收到两个编码表达:encoded_facts和encoded_question , 也就是\(h\) 和\(q\) 。
模块会生成一个记忆memory,初始时memory = encoded_question
记忆模块在encoded_facts上反复迭代多轮,每一轮去提取新的信息episode, 更新memory
遍历所有facts, 对于每一个的fact, 不停地更新当前轮的信息e
计算新的信息:\(e_{new}=\rm{RNN}(fact, e)\) ,使用当前fact和当前信息
计算新信息的保留比例注意门\(g\)
更新信息:\(e = g * e_{new} + (1-g) * e\) 计算保留比例g:结合当前fact 、memory、 question 去生成多个特征,再过一个两层前向网络G得到一个比例数值
更新memory ,\(m^i = \rm{GRU}(e, m^{i-1})\)
特征函数与前向网络
保留比例门g充当着attention的作用 。
特征函数\(z(c, m, q)\) , 其中c就是当前的fact ,(论文里面是9个特征): \[
z(c, m, q) = [c \circ q, c \circ m, \vert c-q\vert, \vert c-m\vert]
\] 前向网络\(g=G(c, m ,q)\) : \[
t = \rm{tanh}(W^1z(c, m, q) + b^1) \\
g = G(c, m, q) = \sigma(W^2 t + b^2)
\] e更新
在每个fact遍历中,e会结合fact和旧e去生成新的信息\(e_{new}\) ,再结合旧\(e\) 和新\(e_{new}\) 去生成最终的\(e^i\) : \[
e_{new}=\rm{RNN}(fact, e)
\]
\[
e = g * e_{new} + (1-g) * e
\]
记忆更新
每一轮迭代后,结合旧记忆和当前轮的信息e去更新记忆: \[
m^i = \rm{GRU}(e, m^{i-1})
\] 迭代停止条件
设置最大迭代次数\(T_M\)
在输入里面追加停止迭代信号,如果注意门选择它,则停止。
回答模块
回答模块结合memory和question,来生成对问题的答案。也是通过GRU来生成答案的。
设a 是answer_gru的hidden state,初始\(a_0= m^{T_M}\) \[
y_t = \rm{softmax}(W^a a_t) \\
a_t = \rm{GRU} ([y_{t-1}, q], a_{t-1})
\] 使用交叉熵去计算loss,进行优化。
实现细节
我的github源代码 ,实现参考自DSKSD的代码 。
数据处理
原始数据
使用过的数据是facebook的bAbi Tasks Data 1-20 里面的 en-10k下的qa5_three-arg-relations_train.txt 和test数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 1 Bill travelled to the office.2 Bill picked up the football there.3 Bill went to the bedroom.4 Bill gave the football to Fred.5 What did Bill give to Fred? football 4 6 Fred handed the football to Bill.7 Jeff went back to the office.8 Who received the football? Bill 6 9 Bill travelled to the office.10 Bill got the milk there.11 Who received the football? Bill 6 12 Fred travelled to the garden.13 Fred went to the hallway.14 Bill journeyed to the bedroom.15 Jeff moved to the hallway.16 Jeff journeyed to the bathroom.17 Bill journeyed to the office.18 Fred travelled to the bathroom.19 Mary journeyed to the kitchen.20 Jeff took the apple there.21 Jeff gave the apple to Fred.22 Who did Jeff give the apple to? Fred 21 23 Bill went back to the bathroom.24 Bill left the milk.25 Who received the apple? Fred 21 1 Mary travelled to the garden.2 Mary journeyed to the kitchen.3 Bill went back to the office.4 Bill journeyed to the hallway.5 Jeff went back to the bedroom.6 Fred moved to the hallway.7 Bill moved to the bathroom.8 Jeff went back to the garden.9 Jeff went back to the kitchen.10 Fred went back to the garden.11 Mary got the football there.12 Mary handed the football to Jeff.13 What did Mary give to Jeff? football 12
比如1-25是一个大的情景
没有问号的都是陈述句,是情景数据fact。只有.号, 都是简单句
带问号的:是问句,带有答案和答案所在句子。使用tab分割
加载原始数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def load_raw_data (file_path, seq_end='</s>' ) : ''' 从文件中读取文本数据,并整合成[facts, question, answer]一条一条的可用数据,原始word形式 Args: file_path -- 数据文件 seq_end -- 句子结束标记 Returns: data -- list,元素是[facts, question, answer] ''' source_data = open(file_path).readlines() print (file_path, ":" , len(source_data), "lines" ) source_data = [line[:-1 ] for line in source_data] data = [] for line in source_data: index = line.split(' ' )[0 ] if index == '1' : facts = [] if '?' in line: tmp = line.split('\t' ) question = tmp[0 ].strip().replace('?' , '' ).split(' ' )[1 :] + ['?' ] answer = tmp[1 ].split() + [seq_end] facts_for_q = deepcopy(facts) data.append([facts_for_q, question, answer]) else : sentence = line.replace('.' , '' ).split(' ' )[1 :] + [seq_end] facts.append(sentence) return data
把数据转成id格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def triple_word2id (triple_word_data, th) : '''把文字转成id Args: triple_word_data -- [(facts, q, a)] word形式 th -- textheler Returns: triple_id_data -- [(facts, q, a)]index形式 ''' for t in triple_word_data: for i, fact in enumerate(t[0 ]): t[0 ][i] = th.sentence2indices(fact) t[1 ] = th.sentence2indices(t[1 ]) t[2 ] = th.sentence2indices(t[2 ]) return triple_word_data
根据batch_size取数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def get_data_loader (data, batch_size=1 , shuffle=False) : ''' 以batch的格式返回数据 Args: data -- list格式的data batch_size -- shuffle -- 每一个epoch开始的时候,对数据进行shuffle Returns: 数据遍历的iterator ''' if shuffle: random.shuffle(data) start = 0 end = batch_size while (start < len(data)): batch = data[start:end] start, end = end, end + batch_size yield batch if end >= len(data) and start < len(data): batch = data[start:] yield batch
对每一个batch进行padding
这部分有点复杂。要求问题、答案、fact的长度一致,每个问题的fact的数量也要一样。
其实和模型也有关,模型写的有点坑,就是每条数据的所有fact应该连接在一起成为一个大的fact送进GRU里,在每个fact后面加上结束标记。但是我这却分开了,分成了多个标记好的fact,也怪当时没有仔细看好论文,这个也是参考别人的实现。循环也导致训练贼慢,但是现在忙着找实习,就先不改了。后面好好写DMNPLUS吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 def pad_batch_data (raw_batch_data, th) : ''' 对数据进行padding,问题、答案、fact长度分别一致,同时每条数据的fact的数量一致。输入到网络的时候要用 Args: raw_batch_data -- [[facts, q, a]],都是以list wordid表示 th -- TextHelper Returns: all_facts -- [b, nfact, flen],pad后的facts,Variable all_facts_mask -- [b, nfact, flen],facts的mask,Variable questions -- [b, qlen],pad后的questions,Variable questions_mask -- [b, qlen],questions的mask,Variable answers -- [b, alen],pad后的answers,Variable ''' all_facts, questions, answers = [list(i) for i in zip(*raw_batch_data)] batch_size = len(raw_batch_data) n_fact = max([len(facts) for facts in all_facts]) flen = max([len(f) for f in flatten(all_facts)]) qlen = max([len(q) for q in questions]) alen = max([len(a) for a in answers]) padid = th.word2index(th.pad) all_facts_mask = [] for i in range(batch_size): facts = all_facts[i] for j in range(len(facts)): t = flen - len(facts[j]) if t > 0 : all_facts[i][j] = facts[j] + [padid] * t while (len(facts) < n_fact): all_facts[i].append([padid] * flen) mask = [tuple(map(lambda v: v == padid, fact)) for fact in all_facts[i]] all_facts_mask.append(mask) q = questions[i] if len(q) < qlen: questions[i] = q + [padid] * (qlen - len(q)) a = answers[i] if len(a) < alen: answers[i] = a + [padid] * (alen - len(a)) all_facts = get_variable(torch.LongTensor(all_facts)) all_facts_mask = get_variable(torch.ByteTensor(all_facts_mask)) answers = get_variable(torch.LongTensor(answers)) questions = torch.LongTensor(questions) questions_mask = [(tuple(map(lambda v: v == padid, q))) for q in questions] questions_mask = torch.ByteTensor(questions_mask) questions, questions_mask = get_variable(questions), get_variable(questions_mask) return all_facts, all_facts_mask, questions, questions_mask, answers
模型
模型定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class DMN (nn.Module) : def __init__ (self, vocab_size, embed_size, hidden_size, padding_idx, seqbegin_id, dropout_p=0.1 ) : ''' Args: vocab_size -- 词汇表大小 embed_size -- 词嵌入维数 hidden_size -- GRU的输出维数 padding_idx -- pad标记的wordid seqbegin_id -- 句子起始的wordid dropout_p -- dropout比率 ''' super(DMN, self).__init__() self.vocab_size = vocab_size self.hidden_size = hidden_size self.seqbegin_id = seqbegin_id self.embed = nn.Embedding(vocab_size, embed_size, padding_idx=padding_idx) self.input_gru = nn.GRU(embed_size, hidden_size, batch_first=True ) self.question_gru = nn.GRU(embed_size, hidden_size, batch_first=True ) self.gate = nn.Sequential( nn.Linear(hidden_size * 4 , hidden_size), nn.Tanh(), nn.Linear(hidden_size, 1 ), nn.Sigmoid() ) self.attention_grucell = nn.GRUCell(hidden_size, hidden_size) self.memory_grucell = nn.GRUCell(hidden_size, hidden_size) self.answer_grucell = nn.GRUCell(hidden_size * 2 , hidden_size) self.answer_fc = nn.Linear(hidden_size, vocab_size) self.dropout = nn.Dropout(dropout_p) self.init_weight() def init_hidden (self, batch_size) : '''GRU的初始hidden。单层单向''' hidden = torch.zeros(1 , batch_size, self.hidden_size) hidden = get_variable(hidden) return hidden def init_weight (self) : nn.init.xavier_uniform(self.embed.state_dict()['weight' ]) components = [self.input_gru, self.question_gru, self.gate, self.attention_grucell, self.memory_grucell, self.answer_grucell] for component in components: for name, param in component.state_dict().items(): if 'weight' in name: nn.init.xavier_normal(param) nn.init.xavier_uniform(self.answer_fc.state_dict()['weight' ]) self.answer_fc.bias.data.fill_(0 )
前向计算参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def forward (self, allfacts, allfacts_mask, questions, questions_mask, alen, n_episode=3 ) : ''' Args: allfacts -- [b, n_fact, flen],输入的多个句子 allfacts_mask -- [b, n_fact, flen],mask=1表示是pad的,否则不是 questions -- [b, qlen],问题 questions_mask -- [b, qlen],mask=1:pad alen -- Answer len seqbegin_id -- 句子开始标记的wordid n_episodes -- Returns: preds -- [b * alen, vocab_size],预测的句子。b*alen合在一起方便后面算交叉熵 ''' bsize = allfacts.size(0 ) nfact = allfacts.size(1 ) flen = allfacts.size(2 ) qlen = questions.size(1 )
输入模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 encoded_facts = [] for facts, facts_mask in zip(allfacts, allfacts_mask): facts_embeds = self.embed(facts) facts.embeds = self.dropout(facts_embeds) hidden = self.init_hidden(nfact) outputs, hidden = self.input_gru(facts_embeds, hidden) real_hiddens = [] for i, o in enumerate(outputs): real_len = facts_mask[i].data.tolist().count(0 ) real_hiddens.append(o[real_len - 1 ]) hiddens = torch.cat(real_hiddens).view(nfact, -1 ).unsqueeze(0 ) encoded_facts.append(hiddens) encoded_facts = torch.cat(encoded_facts)
问句模块
1 2 3 4 5 6 7 8 9 10 11 questions_embeds = self.embed(questions) questions_embeds = self.dropout(questions_embeds) hidden = self.init_hidden(bsize) outputs, hidden = self.question_gru(questions_embeds, hidden) real_questions = [] for i, o in enumerate(outputs): real_len = questions_mask[i].data.tolist().count(0 ) real_questions.append(o[real_len - 1 ]) encoded_questions = torch.cat(real_questions).view(bsize, -1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 memory = encoded_questions for i in range(n_episode): e = self.init_hidden(bsize).squeeze(0 ) encoded_facts_t = encoded_facts.transpose(0 , 1 ) for t in range(nfact): bfact = encoded_facts_t[t] f1 = bfact * encoded_questions f2 = bfact * memory f3 = torch.abs(bfact - encoded_questions) f4 = torch.abs(bfact - memory) z = torch.cat([f1, f2, f3, f4], dim=1 ) gt = self.gate(z) e = gt * self.attention_grucell(bfact, e) + (1 - gt) * e memory = self.memory_grucell(e, memory)
回答模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 answer_hidden = memory begin_tokens = get_variable(torch.LongTensor([self.seqbegin_id]*bsize)) last_word = self.embed(begin_tokens) preds = [] for i in range(alen): inputs = torch.cat([last_word, encoded_questions], dim=1 ) answer_hidden = self.answer_grucell(inputs, answer_hidden) probs = self.answer_fc(answer_hidden) probs = F.log_softmax(probs.float()) _, indics = torch.max(probs, 1 ) last_word = self.embed(indics) preds.append(probs.view(bsize, 1 , -1 )) preds = torch.cat(preds, dim=1 ) return preds.view(bsize * alen, -1 )
配置信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class DefaultConfig (object) : '''配置文件''' train_file = "./datasets/tasks_1-20_v1-2/en-10k/qa5_three-arg-relations_train.txt" test_file = "./datasets/tasks_1-20_v1-2/en-10k/qa5_three-arg-relations_test.txt" seq_end = '</s>' seq_begin = '<s>' pad = '<pad>' unk = '<unk>' batch_size = 128 shuffle = False num_workers = 1 embed_size = 64 hidden_size = 64 n_episode = 3 dropout_p = 0.1 max_epoch = 500 learning_rate = 0.001 min_loss = 0.01 print_every_epoch = 5 use_cuda = True device_id = 0 model_path = "./models/DMN.pkl"
训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 def train (opt, th, train_data) : ''' 训练 Args: opt -- 配置信息 th -- TextHelper实例 train_data -- 训练数据,[[facts, question, answer]] ''' seqbegin_id = th.word2index(th.seq_begin) model = DMN(th.vocab_size, opt.embed_size, opt.hidden_size, seqbegin_id, th.word2index(th.pad)) if opt.use_cuda: model = model.cuda(opt.device_id) optimizer = optim.Adam(model.parameters(), lr = opt.learning_rate) loss_func = nn.CrossEntropyLoss(ignore_index=th.word2index(th.pad)) for e in range(opt.max_epoch): losses = [] for batch_data in get_data_loader(train_data, opt.batch_size, opt.shuffle): allfacts, allfacts_mask, questions, questions_mask, answers = \ pad_batch_data(batch_data, th) preds = model(allfacts, allfacts_mask, questions, questions_mask, answers.size(1 ), opt.n_episode) optimizer.zero_grad() loss = loss_func(preds, answers.view(-1 )) losses.append(loss.data.tolist()[0 ]) loss.backward() optimizer.step() avg_loss = np.mean(losses) if avg_loss <= opt.min_loss or e % opt.print_every_epoch == 0 or e == opt.max_epoch - 1 : info = "e={}, loss={}" .format(e, avg_loss) losses = [] print (info) if e == opt.max_epoch - 1 and avg_loss > opt.min_loss: print ("epoch finish, loss > min_loss" ) torch.save(model, opt.model_path) break elif avg_loss <= opt.min_loss: print ("Early stop" ) torch.save(model, opt.model_path) break
预测和效果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 def cal_test_accuracy (model, test_data, th, n_episode=DefaultConfig.n_episode) : '''测试,测试数据''' batch_size = 1 model.eval() correct = 0 for item in get_data_loader(test_data, batch_size, False ): facts, facts_mask, question, question_mask, answer = pad_batch_data(item, th) preds = model(facts, facts_mask, question, question_mask, answer.size(1 ), n_episode) preds = preds.max(1 )[1 ].data.tolist() answer = answer.view(-1 ).data.tolist() if preds == answer: correct += 1 print ("acccuracy = " , correct / len(test_data)) def test_one_data (model, item, th, n_episode=DefaultConfig.n_episode) : ''' 测试一条数据 Args: model -- DMN模型 item -- [facts, question, answer] th -- TextHelper Returns: None ''' model.eval() item = [item] facts, facts_mask, question, question_mask, answer = pad_batch_data(item, th) preds = model(facts, facts_mask, question, question_mask, answer.size(1 ), n_episode) item = item[0 ] preds = preds.max(1 )[1 ].data.tolist() fact = item[0 ][0 ] facts = [th.indices2sentence(fact) for fact in item[0 ]] facts = [" " .join(fact) for fact in facts] q = " " .join(th.indices2sentence(item[1 ])) a = " " .join(th.indices2sentence(item[2 ])) preds = " " .join(th.indices2sentence(preds)) print ("Facts:" ) print ("\n" .join(facts)) print ("Question:" , q) print ("Answer:" , a) print ("Predict:" , preds) print ()
在本数据集上效果较好,但是数据量小、句子简单,还没有在别的数据集上面进行测试。等忙完了测试一下。