一些机器学习的知识点总结
Tensorflow
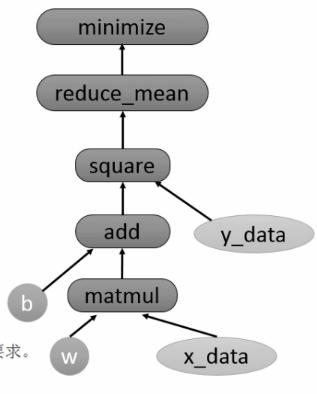
1 Tensorflow的计算图
Tensorflow通过计算图的形式来表示计算。是一个有向图。节点代表一个计算,边代表计算之间的依赖关系。
- 构建计算图
- 执行计算图,
session.run
1 | x_data = np.float32(np.random.rand(2,100)) |
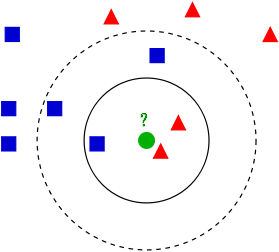
KNN
看中间的绿色属于哪一类?
- 和谁近就属于谁
- 看k个
1 欧式距离和曼哈顿距离
欧式距离是两点之间的距离 \[
d = \sqrt {(x_1-x_2)^2 +(y_1-y_2)^2 }
\] 曼哈顿距离也称作城市街区距离,两个十字路口的实际要走的距离 \[
d = \vert x_1 - x_2\vert + \vert y_1 -y_2 \vert
\] 2 K值的选择
- k较小:用较小范围进行预测。容易过拟合,模型复杂。
- k较大:用较大范围进行预测。较远不相似的也会起作用,会发生错误。模型简单。
- k=N:完全不可取。每个都是属于最多样本的类别
- 一般选择比较小的数值。如采用
交叉验证法来选择最优的k值。 (一部分训练,一部分测试)
Logistic Regression
| 问题列表 |
|---|
| 1 简介LR |
| 2 LR与SVM的区别和联系 |
| 3 LR与线性回归的区别和联系 |
1 简介LR
问一个女生喜欢你吗,SVM会告诉你喜欢或者不喜欢。很粗暴。
LR则会告诉你,有多喜欢你,多不喜欢你。就是告诉你一个可能性。多喜欢你是取决于她的看重点权值和你身上有的东西x。 \[
p(y=1\mid x;\theta)= \sigma(\theta^Tx)=\frac{1}{1+e^{-\theta^Tx}} \quad\quad = h_\theta(x)
\]
\[ p(y=1) = h(x), \quad p(y=0) = 1-h(x) \]
使用极大似然法进行参数估计:样本恰好使联合概率密度(似然函数)取得最大值。概率密度相乘。
对数似然函数: \[
\begin{align}
L(\theta)
& = \log \prod_{i=1}^N [h(x)^{y_i} ][1-h(x)]^{1-y_i} \\
& = \sum_{i=1}^N \left( y_i \log h(x) + (1-y_i)\log(1-h(x)) \right) \\
& = \sum_{i=1}^N (y_i \theta^Tx_i - \log(1+e^{\theta^Tx}))
\end{align}
\] 使\(L(\theta)\)最大,取负数就是其损失函数 : \[
J(\theta) = -\frac{1}{m} L(\theta) = -\frac{1}{m} \sum_{i=1}^N \left( y_i \log h(x) + (1-y_i)\log(1-h(x)) \right)
\] 令导数为0,发现无法解析求解。 \[
\begin{align}
\frac{\partial L(\theta)}{\partial \theta}
& =\sum_{i=1}^N y_i x_i - \sum_{i=1}^N \frac{e^{\theta^Tx}}{1 + e^{\theta^Tx}} x_i \\
& = \sum_{i=1}^N x_i (y_i - \sigma(\theta^Tx) )
\end{align}
\] 只能借助迭代法,如梯度下降法和拟牛顿法来进行求解。
2 LR和SVM的比较
相同点
- 都是分类算法,都是监督学习算法
- 如果不考虑核函数,LR和SVM都是
线性分类算法,决策面都是线性的 - LR和SVM都是判别式模型。 不关心数据怎么生成,只关心数据之间的差别。用差别来进行分类。
判别模型: KNN、 LR 、SVM 。 生成式模型:朴素贝叶斯、 HMM 。
不同点
- 损失函数不同 \[ J(\theta) = -\frac{1}{m} \sum_{i=1}^N \left( y_i \log h(x) + (1-y_i)\log(1-h(x)) \right) \]
\[ L(w, b, \lambda) =\frac{1}{2} \|w\|^2 - \sum_{i=1}^n \alpha_i \left(y_i(w^Tx_i+b) - 1\right) \]
LR基于概率理论,用sigmoid函数表示,通过极大似然法估计出参数的值。
SVM基于间隔最大化原理,认为最大几何间隔的分类面为最优分类面。
- SVM只在乎边界线附近的点(SV),LR在乎所有的点。
- SVM不直接依赖于数据分布;LR受所有点影响,如果不同类别不平衡,要对数据做
balancing - 处理非线性问题时,SVM使用核函数,LR不使用核函数
- SVM只有少数SV进行核计算,LR如果用核函数,则所有的点都会进行计算,代价太高
- 线性SVM依赖数据的距离测度,要对数据做归一化,而LR不用
- SVM损失函数自带L2正则项,而LR需要额外添加
3 LR与线性回归的联系
联系
LR本质上是一个线性核回归模型
区别
- 目标函数:线性回归最小二乘,LR是似然函数
- 线性回归整个实数范围内进行预测;LR预测值限定为
[0,1],sigmoid的非线性形式。轻松处理0/1分类问题

