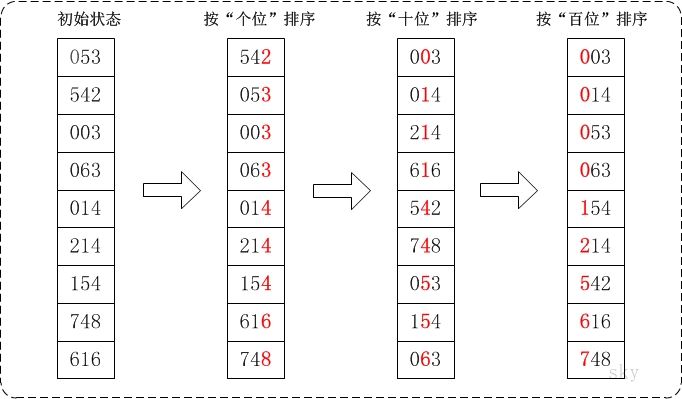
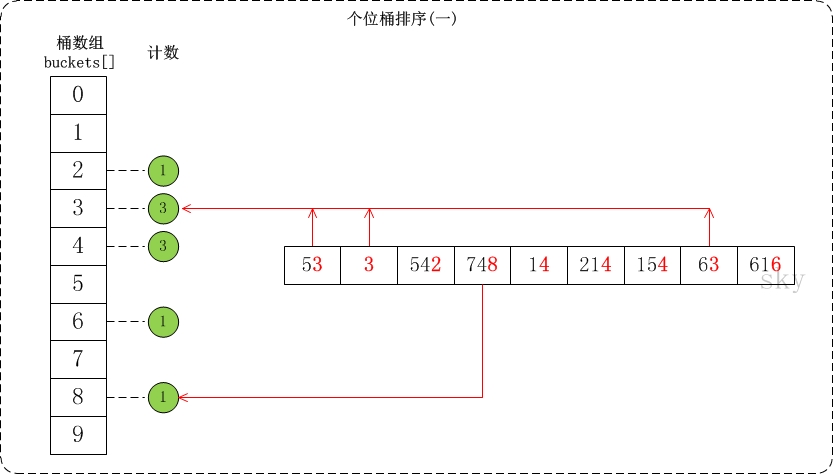
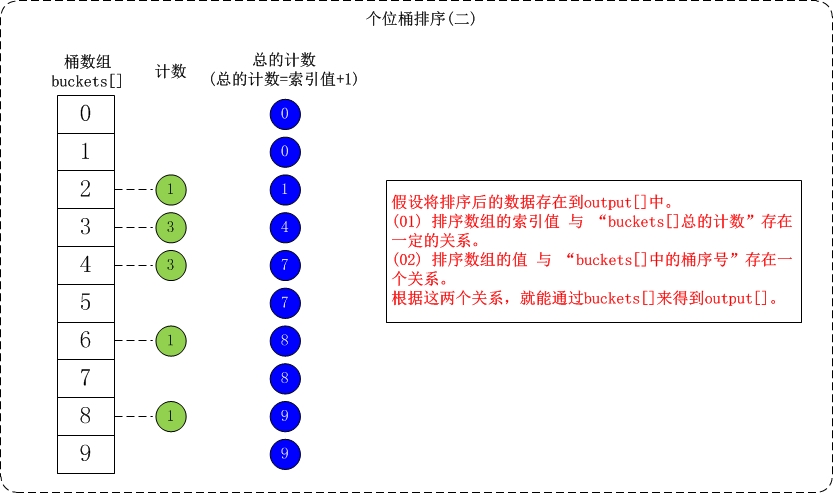
/** * 直接插入排序,先比较找位置,再移动 **/ voidinsert_sort(int a[], int n){ for (int i = 1; i < n; i++) { // 最大,追加在末尾即可 if (a[i] > a[i-1]) { continue; }
// 找到待插入的位置 int k = -1; for (int j = 0; j < i; j++) { if (a[i] < a[j]) { k = j; break; } } int t = a[i]; // 先挪动元素,向后移动 for (int j = i; j > k; j--) { a[j] = a[j-1]; } a[k] = t; } }
/** * 直接插入排序,边比较边移动 **/ voidinsert_sort2(int a[], int n){ for (int i = 1; i < n; i++) { if (a[i] < a[i-1]) { int t = a[i]; int j = i - 1; while (a[j] > t && j >= 0) { a[j+1] = a[j]; j--; } a[j+1] = t; } } }
/** * 插入排序,折半查找出位置,再统一移动 **/ voidinsert_sort_bisearch(int a[], int n){ for (int i = 1; i < n; i++) { if (a[i] > a[i-1]) { continue; } // 折半查找,a[i]要插入的位置为l int l = 0, r = i - 1; while (l <= r) { int m = (l + r) / 2; if (a[i] > a[m]) { // 查找右边 l = m + 1; } elseif (a[i] < a[m]){ // 查找左边 r = m - 1; } else { l = m + 1; break; } } int t = a[i]; for (int j = i; j > l; j--) { a[j] = a[j-1]; } a[l] = t; } }
/* * 希尔排序,按照步长,去划分为多个组。对这些组分别进行插入排序 */ voidshell_sort(vector<int>& a){ // 步长gap==组的个数 for (int gap = a.size() / 2; gap > 0; gap = gap / 2) { // 对各个组进行排序 for (int i = 0; i < gap; i++) { group_sort(a, i, gap); } } }
/* * 对希尔排序中的单个组进行排序,直接插入 * Args: * a -- 数组 * start -- 该组的起始地址 * gap -- 组的步长,也是组的个数 */ voidgroup_sort(vector<int> &a, int start, int gap){ for (int i = start + gap; i < a.size(); i += gap) { if (a[i] < a[i - gap]) { int t = a[i]; int j = i - gap; // 从后向前比较,边比较,边移动 while (a[j] > t && j >= start) { a[j + gap] = a[j]; j -= gap; } a[j + gap] = t; } } }
voidbubble_sort1(int* a, int n){ for (int i = n-1; i > 0; i--) { // 每一轮把a[0,...,i]中最大的向下沉 for (int j = 0; j < i; j++) { if (a[j] > a[j+1]) { int t = a[j]; a[j] = a[j+1]; a[j+1] = t; } } } }
// 若当前轮,已经没有发生交换,说明已经全部有序 voidbubble_sort2(int* a, int n){ int swapped = 0; for (int i = n - 1; i > 0; i--) { swapped = 0; for (int j = 0; j < i; j++) { if (a[j] > a[j+1]) { int t = a[j]; a[j] = a[j+1]; a[j+1] = t; swapped = 1; } } if (swapped = 0) { break; } } }
/** * 划分,左边小于x,中间x,右边大于x * Args: * a: * l: * r: * Returns: * i: x=a[l]的最终所在位置 **/ intpartition(int* a, int l, int r){ int x = a[l]; int i = l; int j = r; // 划分 while (i < j) { // 从右到左,找到第一个小于x的a[j],放到a[i]上 while (a[j] >= x && j > i) { j--; } // 把a[j]放到左边i上 if (j > i) { a[i++] = a[j]; } // 从左到右,找到一个大于x的[i] while (a[i] <= x && i < j) { i++; } // 把a[i]放到右边j上 if (i < j) { a[j--] = a[i]; } } // x放在中间 a[i] = x; return i; }
递归快排
1 2 3 4 5 6 7 8 9 10 11
voidquick_sort(int* a, int l, int r){ // 1. 递归终止 if (l >= r) { return; } // 2. 划分,左边小于x,中间x,右边大于x int k = partition(a, l, r); // 3. 递归快排左右两边 quick_sort(a, l, k - 1); quick_sort(a, k + 1, r); }
voidquick_sort_stack(int* a, int l, int r){ int i, j; stack<int> st; // 注意进栈和出栈的顺序 st.push(r); st.push(l); while (st.empty() == false) { // 每次出栈一组 i = st.top(); st.pop(); j = st.top(); st.pop(); if (i < j) { int k = partition(a, i, j); // 左边的 if (k > i) { st.push(k - 1); st.push(i); } // 右边的 if (k < j) { st.push(j); st.push(k + 1); } } } }
/** * 简单选择排序,选择后面最小的来与当前有序的最后一个(最大的)交换 **/ voidselect_sort(int *a, int n){ for (int i = 1; i < n; i++) { int k = min_index(a, i, n-1); if (a[i-1] > a[k]) { swap(a, i-1, k); } } }
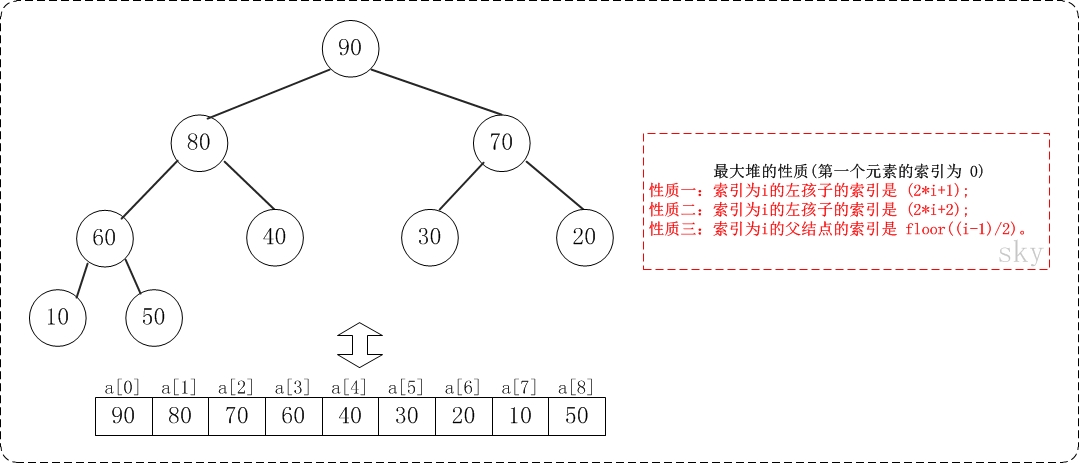
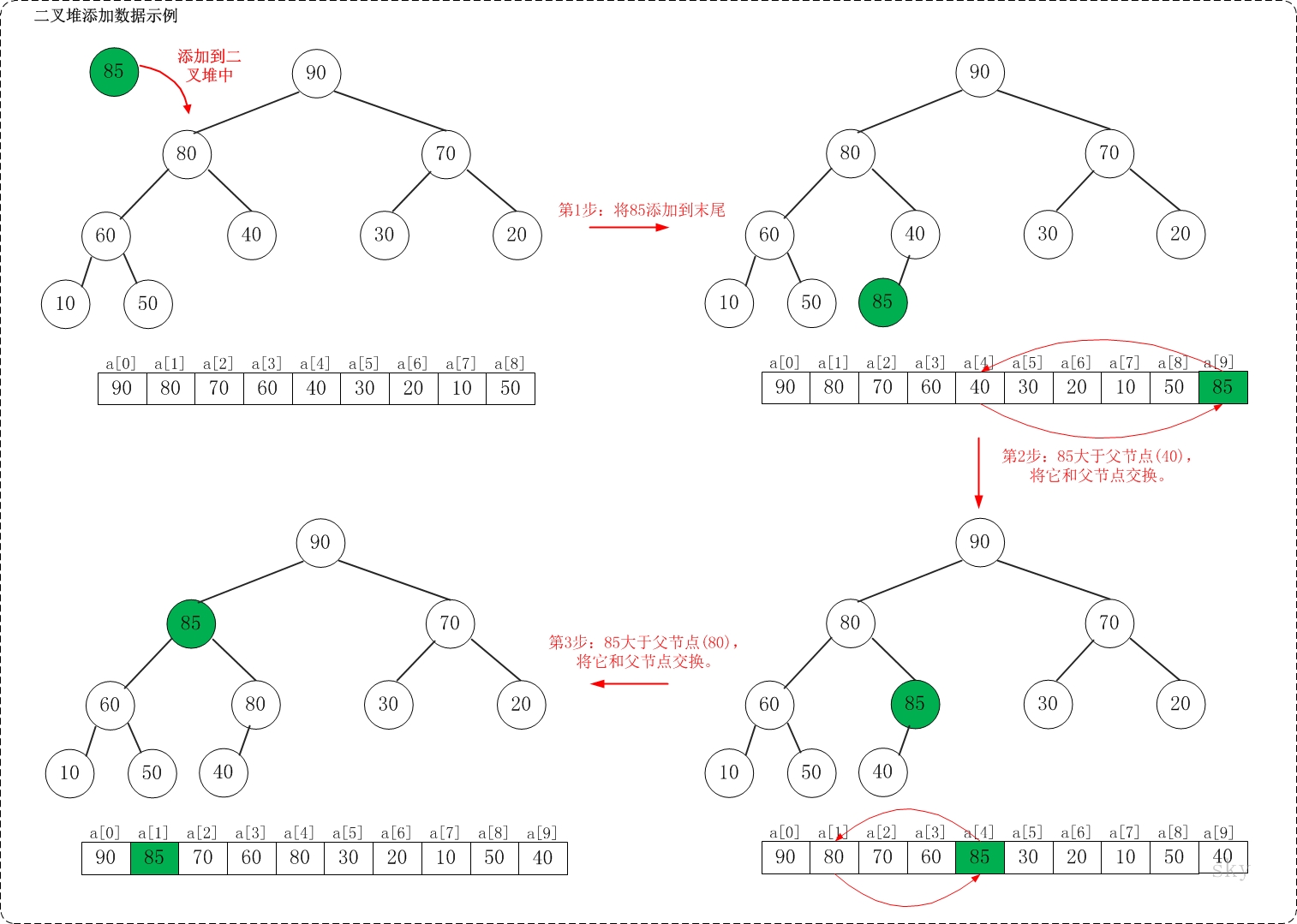
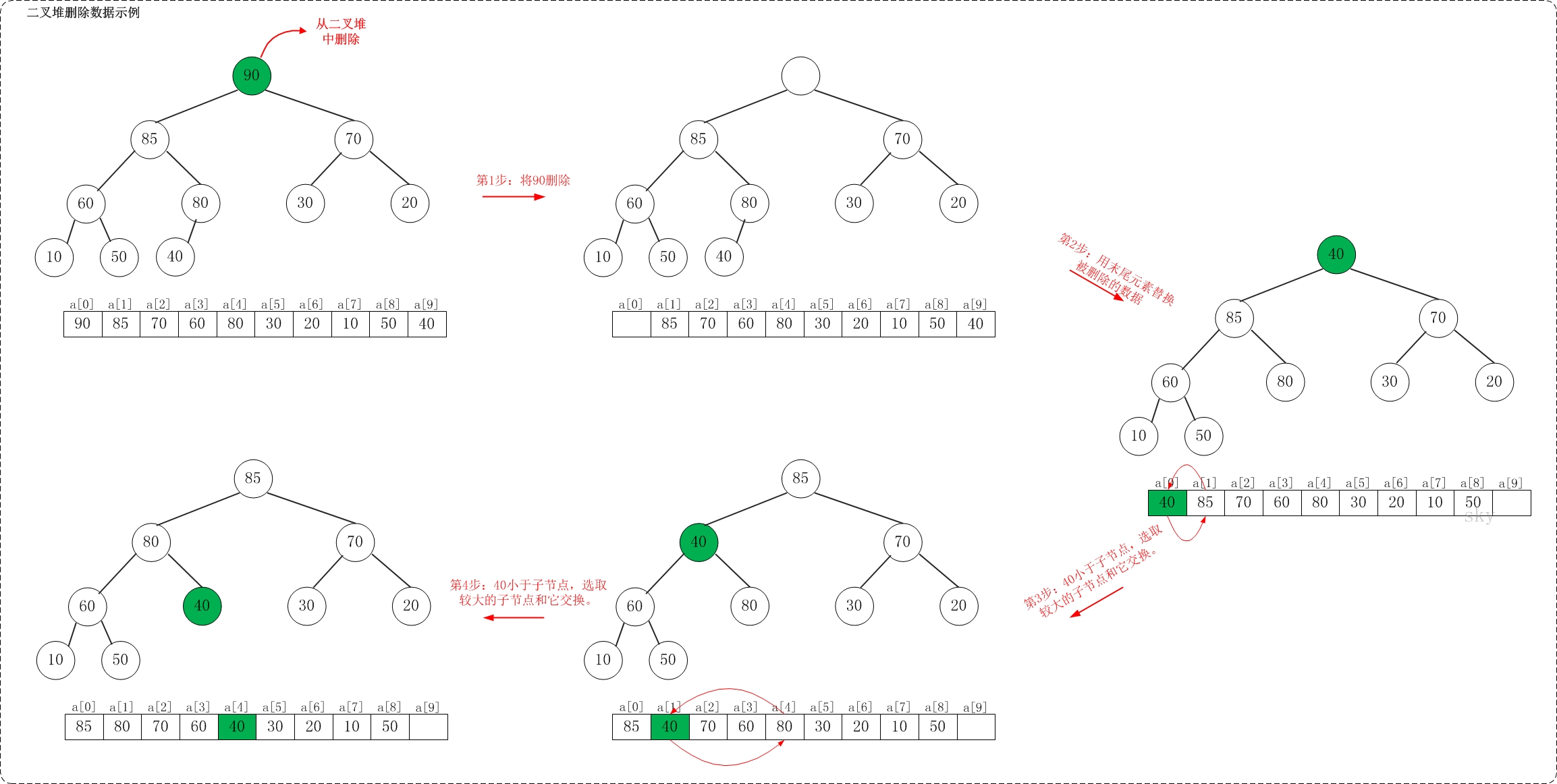
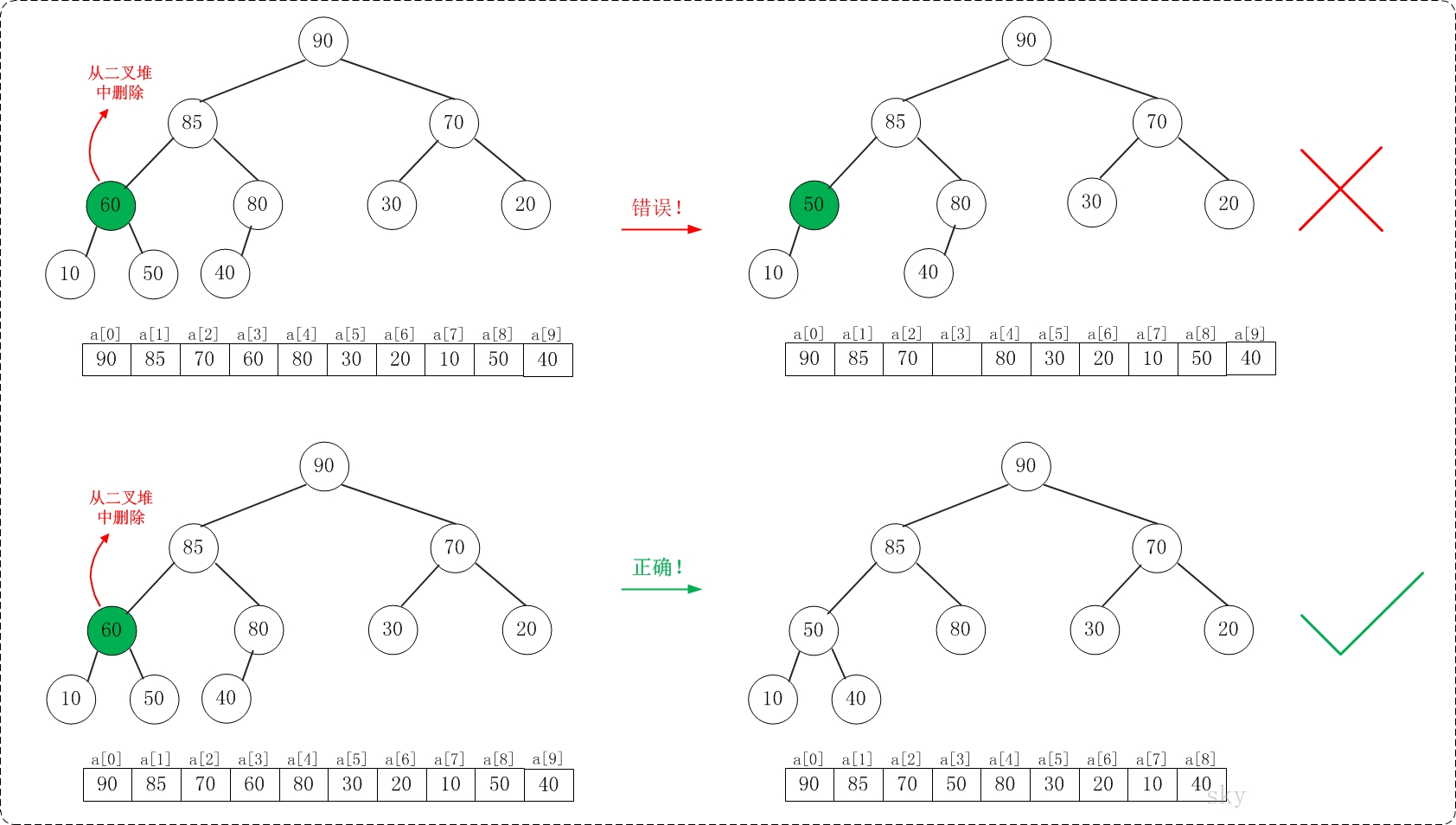
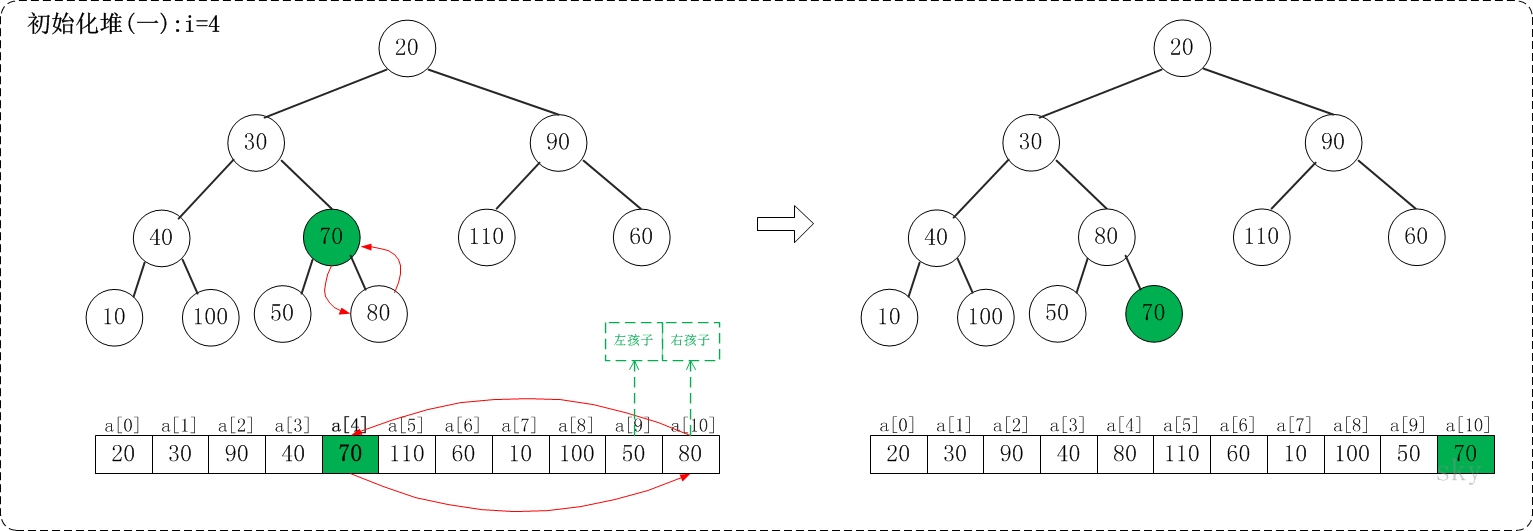
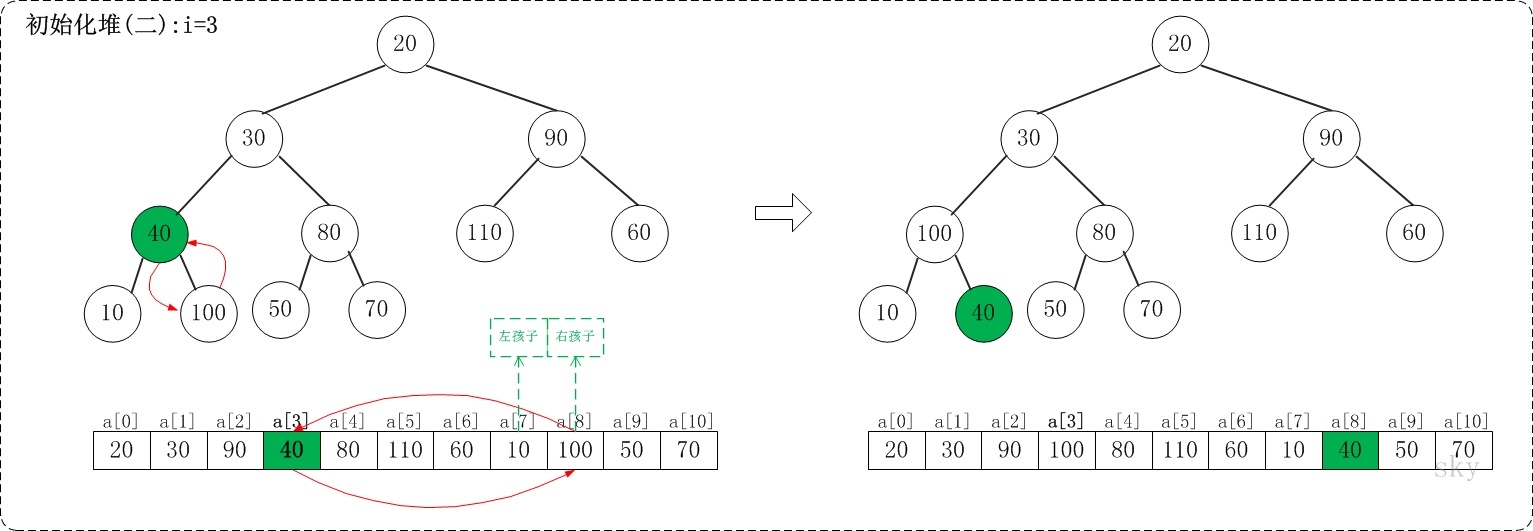
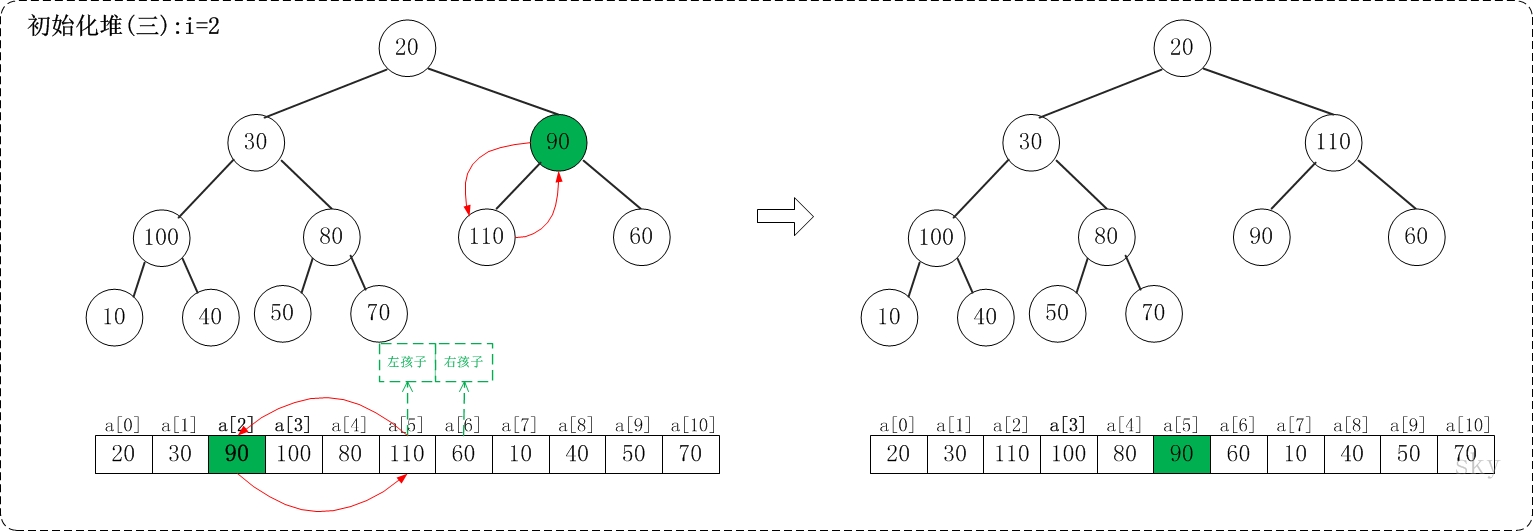
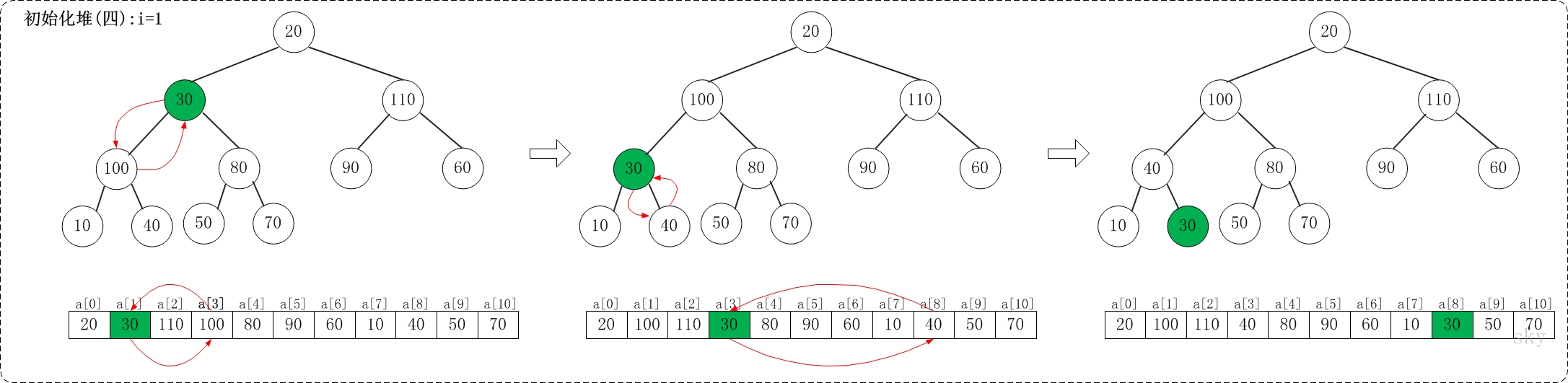
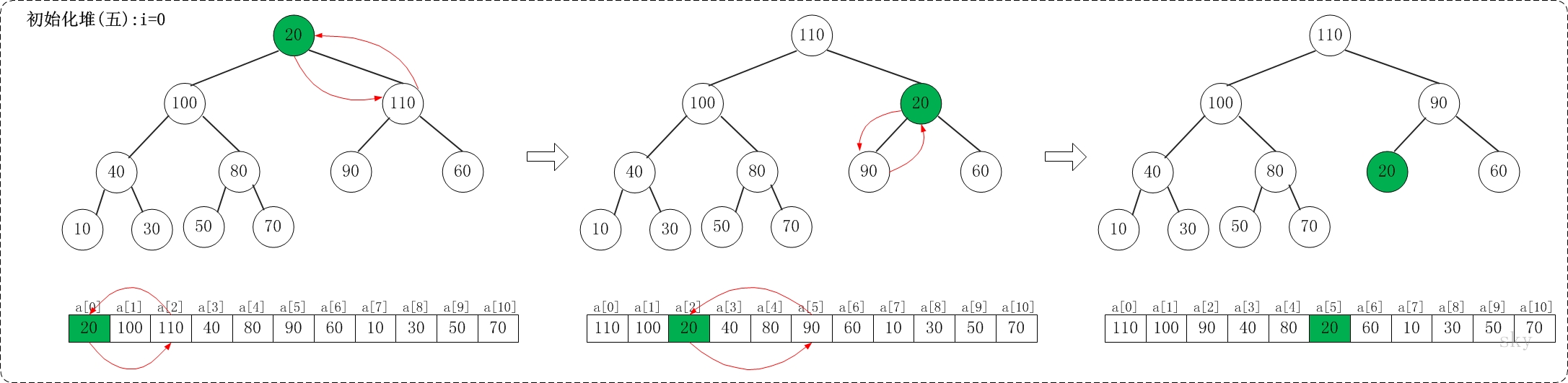
/** * 保证以start为根节点的子树是一个最大堆,末尾元素为end * * Args: * a: 存放堆的数组 * start: 根节点 * end: 子树的末尾元素 * Returns: * None **/ voidmax_heap_down(vector<int>& a, int start, int end){ // 当前节点 int c = start; // 左孩子 int l = 2 * c + 1; // 当前父亲节点 int t = a[c]; for (; l <= end; c = l, l = 2*c + 1) { // 选择较大的孩子与父亲交换 if (l + 1 <= end && a[l] < a[l + 1]) { // 有右孩子,并且右孩子比左孩子大,则选择右孩子 l++; } if (t >= a[l]) { // 父亲大于孩子 break; } else { // 交换 a[c] = a[l]; a[l] = t; } } }
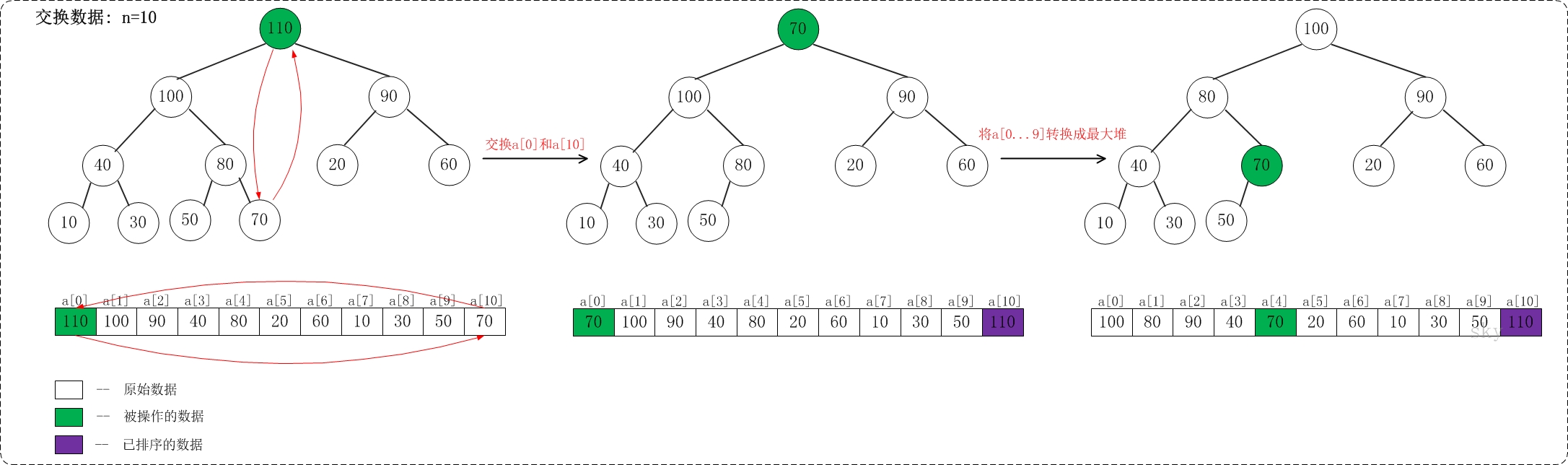
/** * 堆排序,升序 **/ voidheap_sort_asc(vector<int>& a){ int n = a.size(); // 初始化一个最大堆 for (int i = n / 2 - 1; i >= 0; i--) { max_heap_down(a, i, n - 1); } // 依次取堆顶元素放到末尾 for (int i = n - 1; i >= 0; i--) { // max放到a[i] int t = a[i]; a[i] = a[0]; a[0] = t; // 保证a[0...i-1]依然是个最大堆 max_heap_down(a, 0, i-1); } return; }
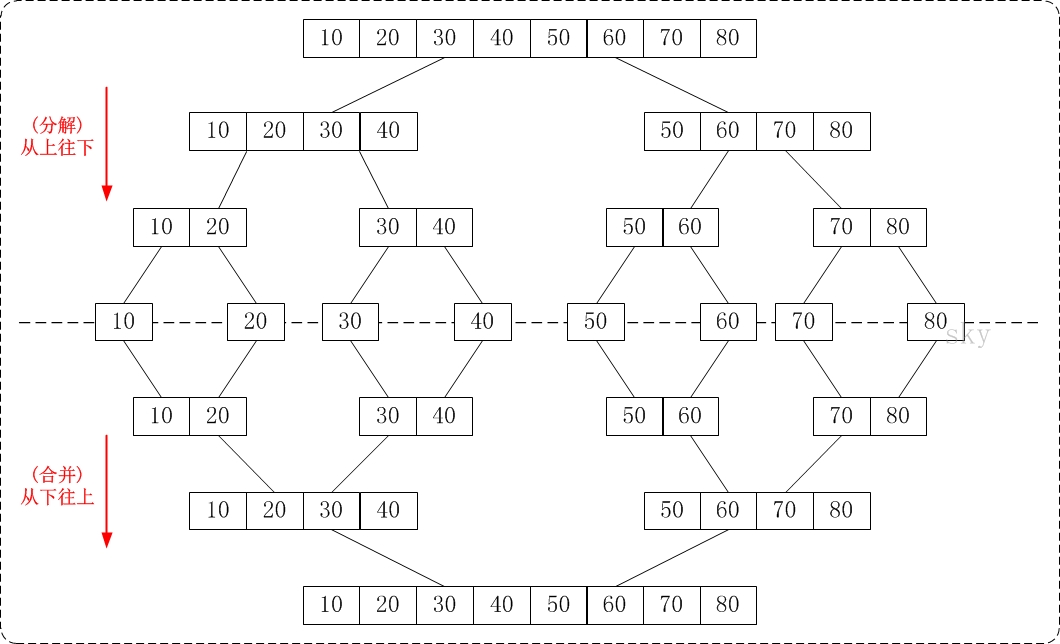
/** * 将a中前后两个有序序列合并在一起 **/ voidmerge(vector<int> &a, int start, int mid, int end){ // 把有序序列临时存放到t中 int * t = newint [end - start + 1]; int i = start; int j = mid + 1; int k = 0; // 依次合并 while (i <= mid && j <= end) { if (a[i] < a[j]) { t[k++] = a[i++]; } else { t[k++] = a[j++]; } }
while (i <= mid) { t[k++] = a[i++]; }
while (j <= end) { t[k++] = a[j++]; } // 把新的有序列表复制回a中 for (int i = 0; i < k; i++) { a[start + i] = t[i]; }
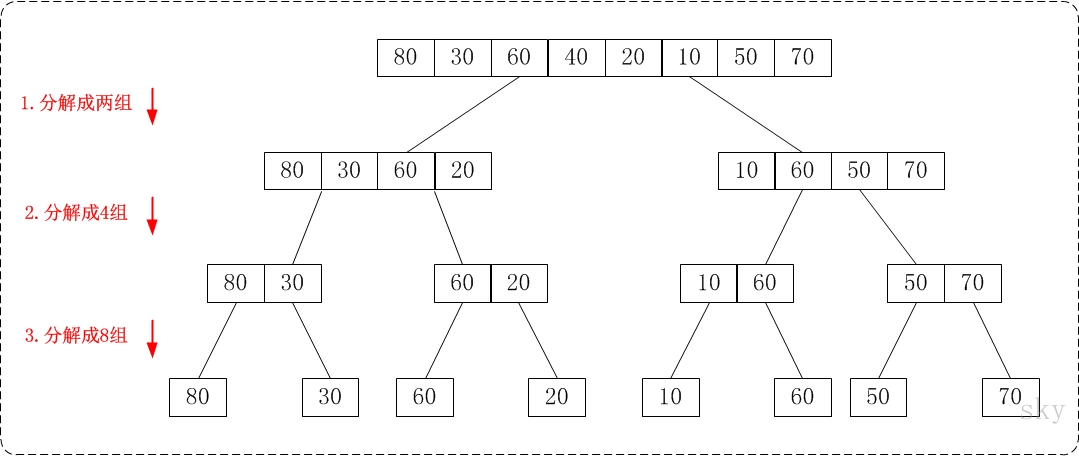
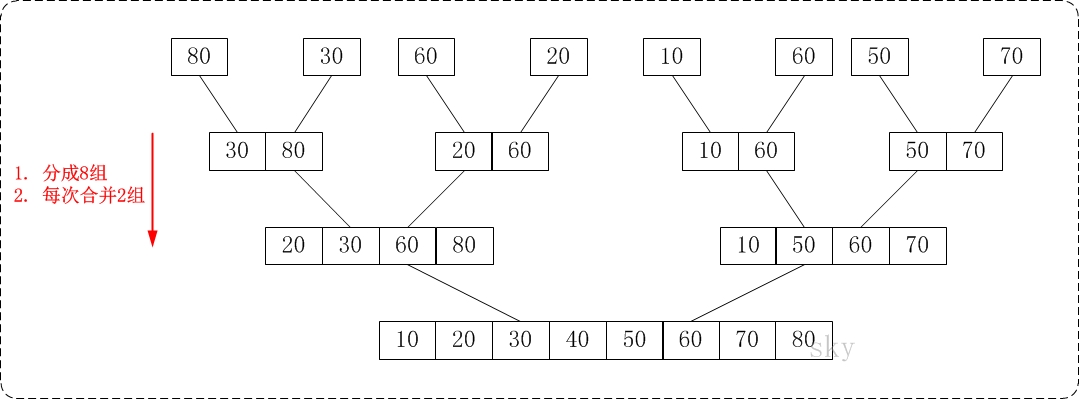
/** * 归并排序,从下到上 **/ voidmerge_sort_down2up(vector<int> &a){ if (a.size() <= 0) return; for (int i = 1; i < a.size(); i = i * 2) merge_groups(a, i); }
/* * 对a做若干次合并,分为若干个gap。对每相邻的两个gap进行合并排序 * Args: * a: 数组 * gap: 一个子数组的长度 */ voidmerge_groups(vector<int> &a, int gap){ int twolen = 2 * gap; int i; for (i = 0; i + twolen - 1 < a.size(); i += twolen) { int start = i; int mid = i + gap - 1; int end = i + twolen - 1; merge(a, start, mid, end); } // 最后还有一个gap if (i + gap - 1 < a.size() - 1) { merge(a, i, i + gap - 1, a.size() - 1); } }