cs224n的第一个作业,包括softmax、神经网络基础和词向量
Softmax
Softmax常数不变性
\[ \rm{softmax}(\mathbf{x})_i = \frac{e^{\mathbf x_i}}{\sum_{j}e^{\mathbf{x}_j}} \]
一般在计算softmax的时候,避免太大的数,要加一个常数。 一般是减去最大的数。 \[
\rm{softmax}(x) = \rm{softmax}(x+c)
\]
关键代码
1 | def softmax(x): |
神经网络基础
Sigmoid实现
我的sigmoid笔记 \[ \begin{align} & \sigma (z) = \frac {1} {1 + \exp(-z)}, \; \sigma(z) \in (0,1) \\ \\ & \sigma^\prime (z) = \sigma(z) (1 - \sigma(z)) \\ \end{align} \] 关键代码
1 | def sigmoid(x): |
Softmax求梯度
交叉熵和softmax如下,记softmax的输入为\(\theta\) ,\(y\)是真实one-hot向量。 \[ \begin{align} & \rm{CE}(y, \hat y) = - \sum_{i} y_i \times \log (\hat y_i) \\ \\ & \hat y = \rm{softmax} (\theta)\\ \end{align} \] softmax求导
引入记号: \[ \begin{align} & f_i = e^{\theta_i} & \text{分子} \\ & g_i = \sum_{k=1}^{K}e^{\theta_k} & \text{分母,与i无关} \\ & \hat y_i = S_i = \frac{f_i}{g_i} & \text{softmax}\\ \end{align} \] 则有\(S_i\)对其中的一个数据\(\theta_j\) 求梯度: \[ \frac{\partial S_i}{\partial \theta_j} = \frac{f_i^{\prime} g_i - f_i g_i^{\prime}}{g_i^2} \] 其中两个导数 \[ f^{\prime}_i(\theta_j) = \begin{cases} & e^{\theta_j}, & i = j\\ & 0, & i \ne j \\ \end{cases} \]
\[ g^{\prime}_i(\theta_j) = e^{\theta_j} \]
\(i=j\)时 \[ \begin{align} \frac{\partial S_i}{\partial \theta_j} & = \frac{e^{\theta_j} \cdot \sum_{k}e^{\theta_k}- e^{\theta_i} \cdot e^{\theta_j}}{\left( \sum_ke^{\theta_k}\right)^2} \\ \\ & = \frac{e^{\theta_j}}{\sum_ke^{\theta_k}} \cdot \left( 1 - \frac{e^{\theta_j}}{\sum_k e^{\theta_k}} \right) \\ \\ & = S_i \cdot (1 - S_i) \end{align} \] \(i \ne j\)时 \[ \begin{align} \frac{\partial S_i}{\partial \theta_j} & = \frac{ - e^{\theta_i} \cdot e^{\theta_j}}{\left( \sum_ke^{\theta_k}\right)^2} = - S_i \cdot S_j \end{align} \]
交叉熵求梯度
\[ \begin{align} & \rm{CE}(y, \hat y) = - \sum_{i} y_i \times \log (\hat y_i) \\ \\ & \hat y = \rm{S} (\theta)\\ \end{align} \]
只关注有关系的部分,带入\(y_i =1\) : \[ \begin{align} \frac{\partial CE}{\partial \theta_i} & = -\frac{\partial \log \hat y_i}{\partial \theta_i} = - \frac{1}{\hat y_i} \cdot \frac{\partial \hat y_i}{\partial \theta_i} \\ \\ & = - \frac{1}{S_i} \cdot \frac{\partial S_i}{\partial \theta_i} = S_i - 1 \\ \\ & = \hat y_i - y_i \end{align} \] 不带入求导 \[ \begin{align} \frac{\partial CE}{\partial \theta_i} & = - \sum_{k}y_k \times \frac{\partial \log S_k}{\partial \theta_i} \\ & = - \sum_{k}y_k \times \frac{1}{S_k}\times \frac{\partial S_k}{\partial \theta_i} \\ & = - y_i (1 - S_i) - \sum_{k \ne i} y_k \cdot \frac{1}{S_k} \cdot (- S_i \cdot S_k) \\ & = - y_i (1 - S_i) + \sum_{k \ne i} y_k \cdot S_i \\ & = S_i - y_i \end{align} \] 所以,交叉熵的导数是 \[ \frac{\partial CE}{\partial \theta_i} = \hat y_i - y_i, \quad \quad \frac{\partial CE(y, \hat y)}{\partial \theta} = \hat y - y \]
即 \[ \frac{\partial CE(y, \hat y)}{\partial \theta_i} = \begin{cases} & \hat y_i - 1, & \text{i是label} \\ &\hat y_i, & \text{其它}\\ \end{cases} \]
简单网络
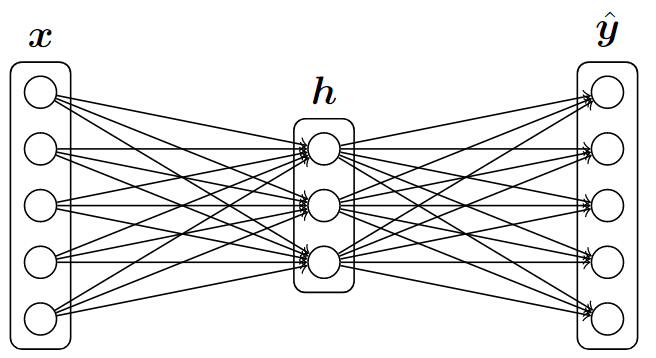
前向计算 \[ \begin{align} & z_1 = xW_1 + b_1 \\ \\ & h = \rm{sigmoid}(z1) \\ \\ & z_2 = hW_2 + b_2 \\ \\ & \hat y = \rm{softmax}(z_2) \end{align} \] 关键代码:
1 | def forward_backward_prop(data, labels, params, dimensions): |
loss函数 \[ J = \rm{CE}(y, \hat y) \] 关键代码:
1 | def forward_backward_prop(data, labels, params, dimensions): |
反向传播 \[ \begin {align} & \delta_2 = \frac{\partial J}{\partial z_2} = \hat y - y \\ \\ & \frac{\partial J}{\partial h} = \delta_2 \cdot \frac{\partial z_2}{\partial h} = \delta_2 W_2^T \\ \\ & \delta_1 = \frac{\partial J}{\partial z_1} = \frac{\partial J}{\partial h} \cdot \frac{\partial h}{\partial z_1} = \delta_2 W_2^T \circ \sigma^{\prime}(z_1) \\ \\ & \frac{\partial J}{\partial x} = \delta_1 W_1^T \end{align} \] 一共有\((d_x + 1) \cdot d_h + (d_h +1) \cdot d_y\) 个参数。
关键代码:
1 | def forward_backward_prop(data, labels, params, dimensions): |
梯度检查
1 | def gradcheck_naive(f, x): |
Word2Vec
词向量的梯度
符号定义
- \(v_c\) 中心词向量,输入词向量,\(V\), \(\mathbb{R}^{W\times d}\)
- \(u_o\) 上下文词向量,输出词向量,\(U=[u_1, u_2, \cdots, u_w]\) , \(\mathbb{R}^{d\times W}\)
前向
预测o是c的上下文概率,o为正确单词 \[ \hat y_o = p(o \mid c) = \rm{softmax}(o) = \frac{\exp(u_o^T v_c)}{\sum_{w} \exp(u_w^T v_c)} \] 得分向量: \[ z=U^T \cdot v_c, \quad [W,d] \times[ d] \in ,\mathbb{R}^{W } \] loss及梯度 \[ J_{\rm{softmax-CE}}(v_c, o, U) = CE(y, \hat y), \quad \text{其中} \; \frac{\partial CE(y, \hat y)}{\partial \theta} = \hat y - y \]
| 梯度 | 中文 | 计算 | 维数 |
|---|---|---|---|
| \(\frac{\partial J}{\partial z}\) | softmax | \(\hat y - y\) | \(W\) |
| \(\frac{\partial J}{\partial v_c}\) | 中心词 | \(\frac{\partial J}{\partial z} \cdot \frac{\partial z}{\partial v_c} = (\hat y - y) \cdot U^T\) | \(d\) |
| \(\frac{\partial J}{\partial U}\) | 上下文 | \(\frac{\partial J}{\partial z} \cdot \frac{\partial z}{\partial U^T}= (\hat y - y) \cdot v_c\) | \(d \times W\) |
关键代码
1 | def softmaxCostAndGradient(predicted, target, outputVectors, dataset): |

