PyTorch上手及其常用API总结
PyTorch介绍
PyTorch
Torch 是一个使用Lua 语言的神经网络库,而PyTorch是Torch在Python的衍生。
PyTorch是一个基于python的科学计算包。本质上是Numpy的代替者,支持GPU、带有高级功能,可以用来搭建和训练深度神经网络;是一个深度学习框架,速度更快,弹性更好。
PyTorch和Tensorflow
Tensorflow 类似一个嵌入Python的编程语言。写的Tensorflow代码会被Python编译成一张计算图,然后由TensorFlow执行引擎运行。Tensorflow有一些额外的概念需要学习,上手时间慢。
对比参考这篇文章PyTorch还是Tensorflow 。下面是结论。后续再补充详细内容。
PyTorch更有利于研究人员、爱好者、小规模项目等快速搞出原型,易于理解。而TensorFlow更适合大规模部署,特别是需要跨平台和嵌入式部署时。
PyTorch和Tensorflow对比如下
| PyTORCH | Tensorflow | |
|---|---|---|
| 动静态 | 建立的神经网络是动态的 | 建立静态计算图 |
| 代码难度 | 易于理解,好看一些。有弹性 | 底层代码难以看懂 |
| 工业化 | 好上手 | 高度工业化 |
数据操作
Tensor
创建Tensor
Tensor实际上是一个数据矩阵,PyTorch处理的单位就是一个一个的Tensor。下面是一些创建方法
1 | import torch |
Tensor也可以通过Numpy来进行创建,或者从Tensor得到一个Numpy。
1 | import numpy as np |
Tensor操作
Tensor的运算也很简单,一般的四则运算都是支持的。
1 | x = torch.rand(5, 3) |
其中所有类似于x.add_(y)的操作都会改变自己x,如x.copy_(y) 、x.t_() 。
对于Tensor可以像Numpy那样索引和切片。
改变Tensor和Numpy
改变Tensor后,对应的Numpy也会发生改变
1 | a = torch.ones(5) |
CUDA Tensors
使用GPU很简单,只需使用.cuda就可以了
1 | if torch.cuda.is_available(): |
Variable
在神经网络中,最重要的是torch.autograd这个包,而其中最重要的一个类就是Variable。
本质上Variable和Tensor没有区别,不过Variable会放入一个计算图,然后进行前向传播,反向传播和自动求导。这也是PyTorch和Numpy不同的地方。
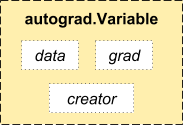
Variable由data, grad, creator 三部分组成。
- data: 包装的Tensor,即数据
- grad: 方向传播的梯度缓冲区
- creator: 得到这个Variable的操作,如乘法加法等等。
用一个Variable进行计算,返回的也是一个同类型的Variable。
梯度计算例子
线性计算\(z= 2 \cdot x + 3 \cdot y + 4\) ,求\(\frac{ \partial z}{\partial x}\) 和\(\frac{ \partial z}{\partial y}\) 。
1 | import torch |
复杂计算$ y = x + 2$, \(z = y * y * 3\), \(o = avg(z)\) ,求\(\frac{dz}{dx}\)
1 | x = Variable(torch.ones(2, 2), requires_grad = True) |
传递梯度
1 | x = Variable(torch.Tensor([2]), requires_grad = True) |
一些常用的API总结
1 | x = torch.Tensor([2, 2]) |

