ACL2018 Best Paper, 性价比很高的效果提升方法。ELMo: Deep contextualized word representations
背景
词向量的问题
Word2vec和Glove,可以学习到一些词汇在语义和语法上的信息。由于它是固定的,所以它无法根据上下文去表示一个词语,也无法解决一词多义的问题。
相关研究
1. 学习subword的信息
CHARAGRAM: Embedding Words and Sentences via Character n-grams
2. 为每种词义单独训练词向量
3. Context2vec
Learning Generic Context Embedding with Bidirectional LSTM
4. CoVe 从机器翻译中学习词向量
Learned in Translation: Contextualized Word Vectors
5. 半监督的
Semi-supervised sequence tagging with bidirectional language models
上述方法都得益于大规模数据集。其中CoVe非常火,但是受限制于双语语料,同时效果也没有ELMo好。
ELMo图解
ELMo的目的
ELMo全称是Embeddings from Language Model。ELMo的特点是根据上下文来确定词向量。

对于Glove来说,会选择played运动的意义。然而在ELMo中,却可以根据上下文来获得语义信息。

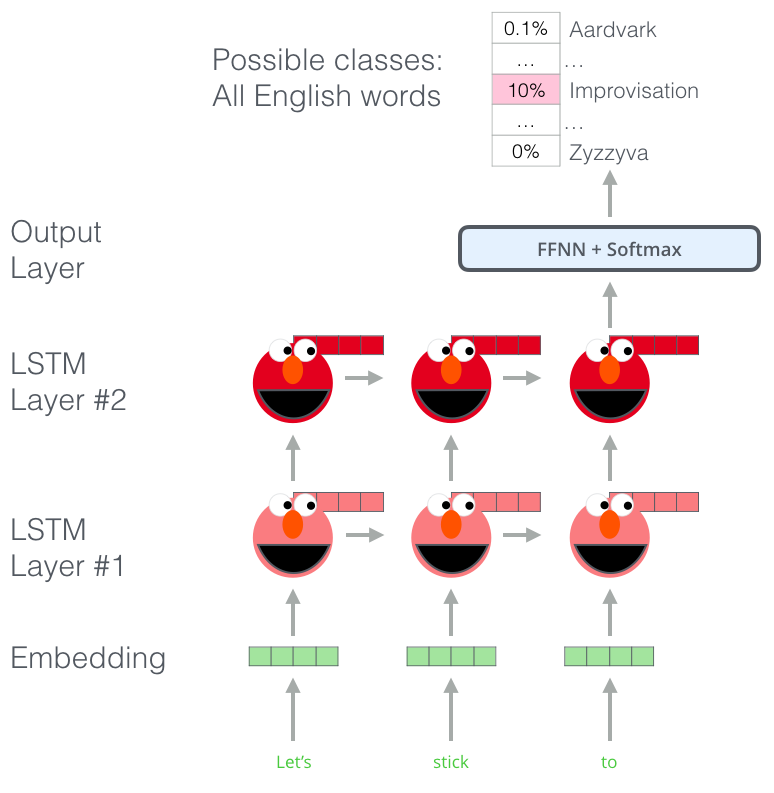
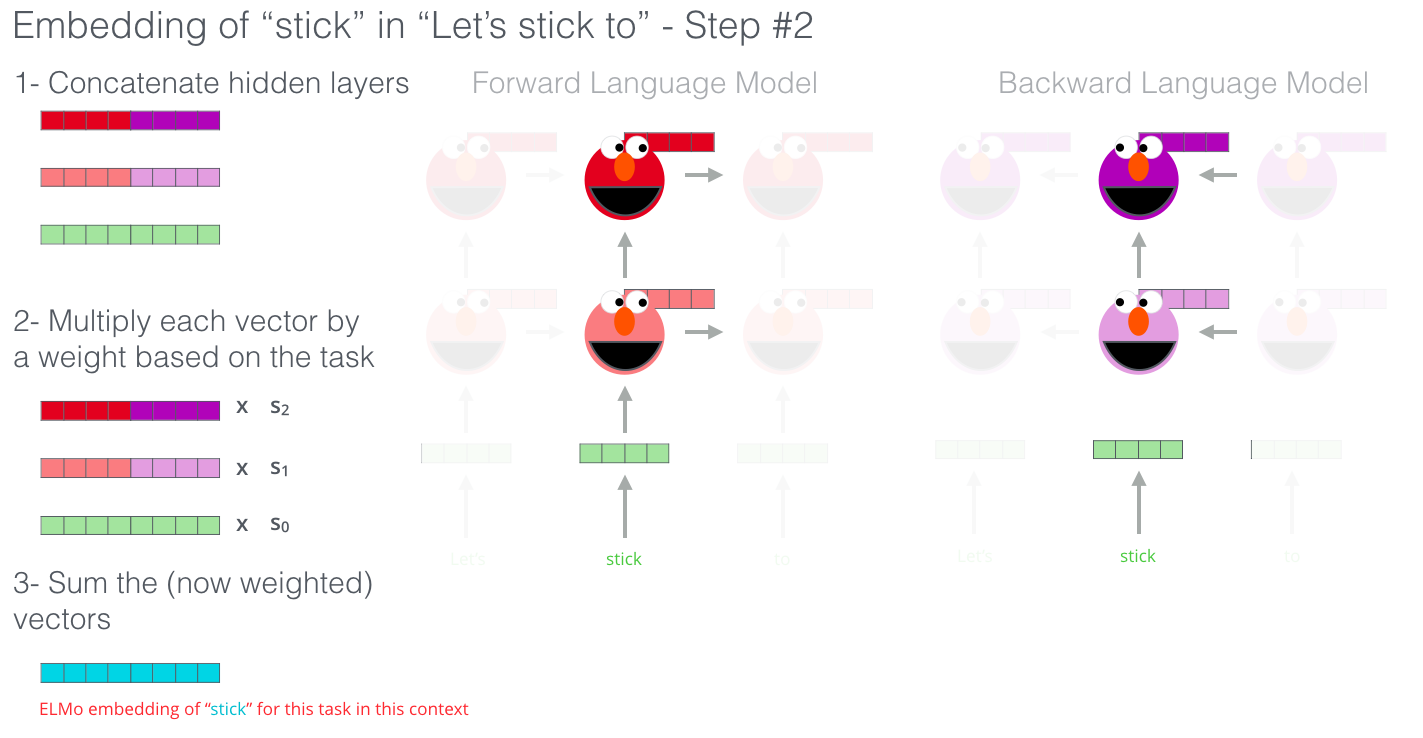
ELMo是一个2层BiLSTM的语言模型。把各个位置上的每层的输出线性组合起来便是最终的ELMo 词向量。
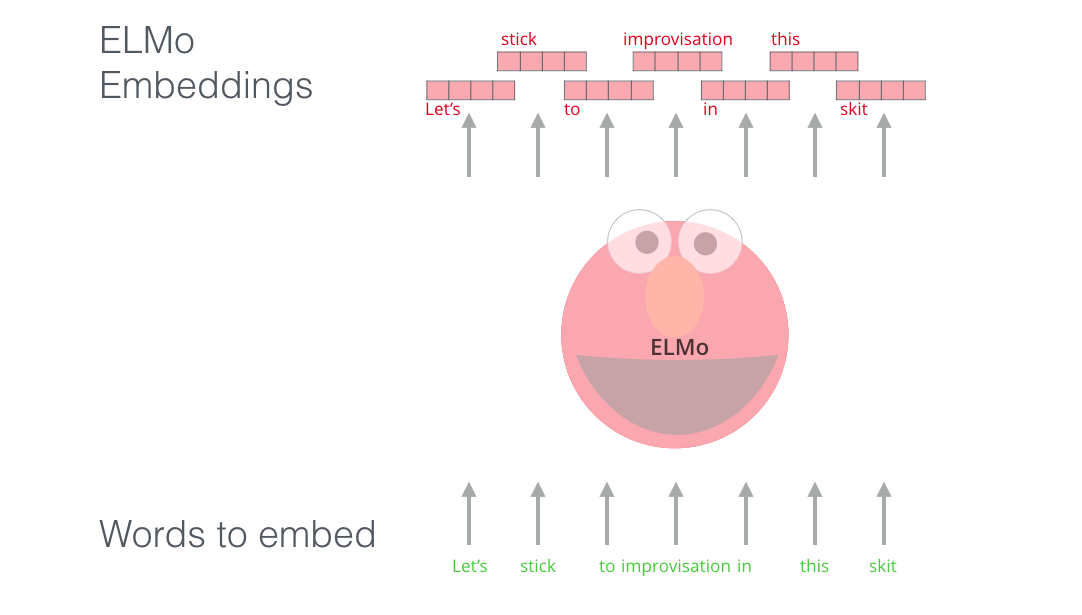
语言模型
预测下一个词汇的任务,在大规模预料中进行训练,来理解语言,掌握一些语言模式。不是说能直接预测出下一个词是什么,而是正确的单词的概率远大于不会出现的单词。
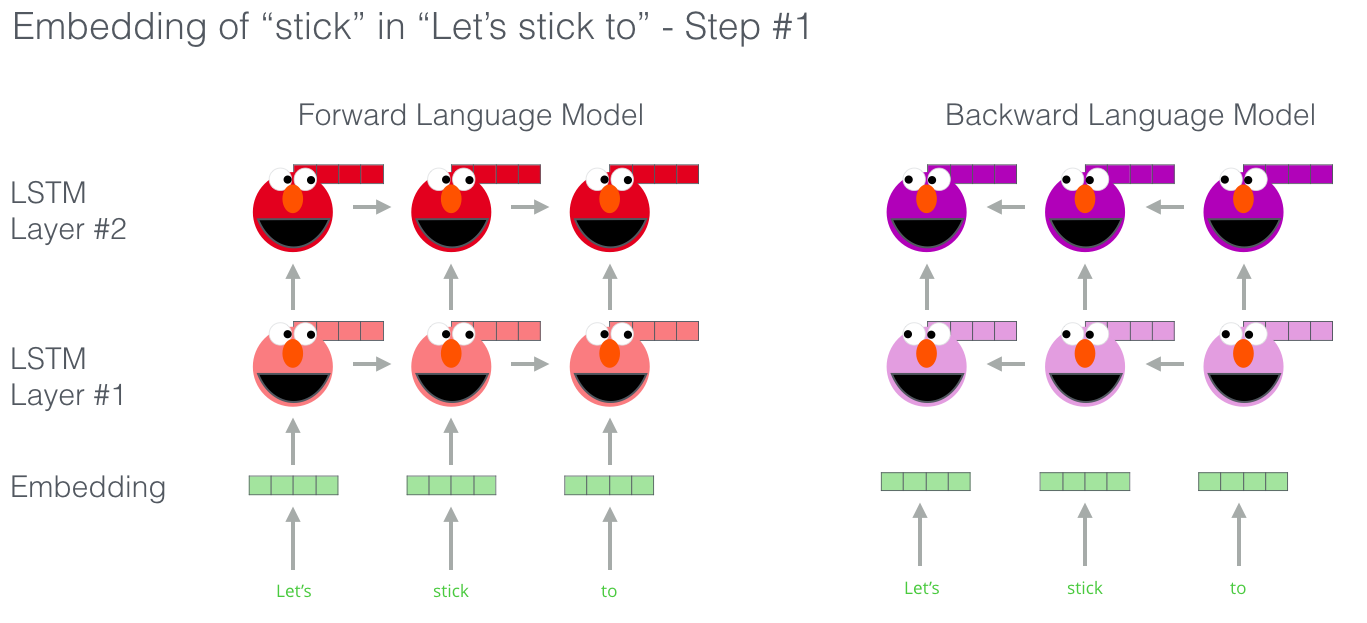
双向语言模型
双向语言模型中,词汇对下一个词汇和前一个词汇都有感知。
ELMo词向量
Deep Contextualized Vectors由如下步骤构成:
- 在每一层,把两个方向的隐状态拼接起来得到该层的隐状态
- 把初始词向量、第一层的隐状态、第二层的隐状态,线性组合起来得到最终的词向量
ELMo使用
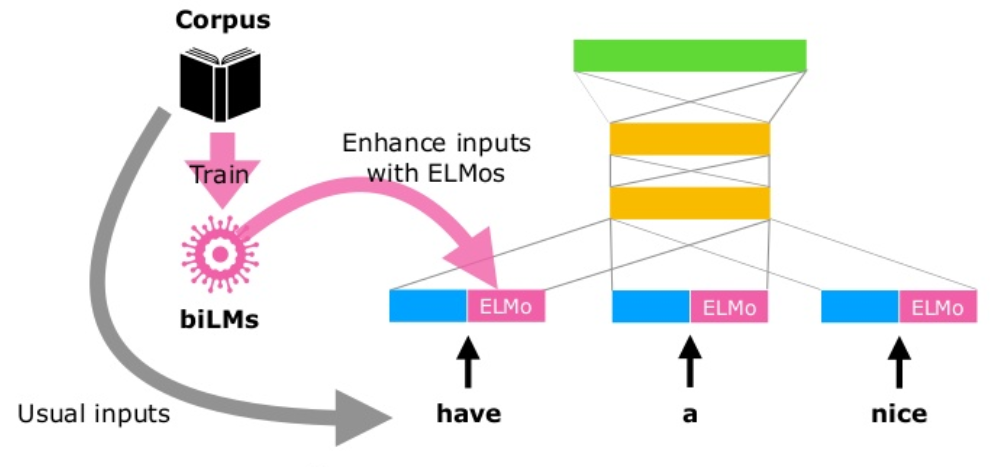
把ELMo词向量和传统词向量拼接起来,作为新的词向量输入。
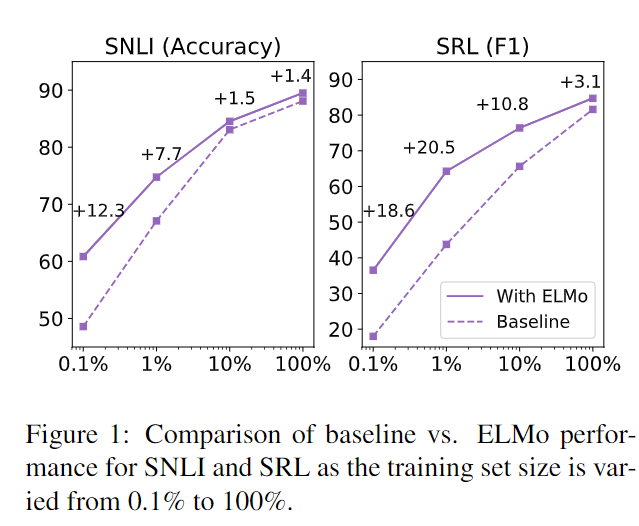
ELMo分析
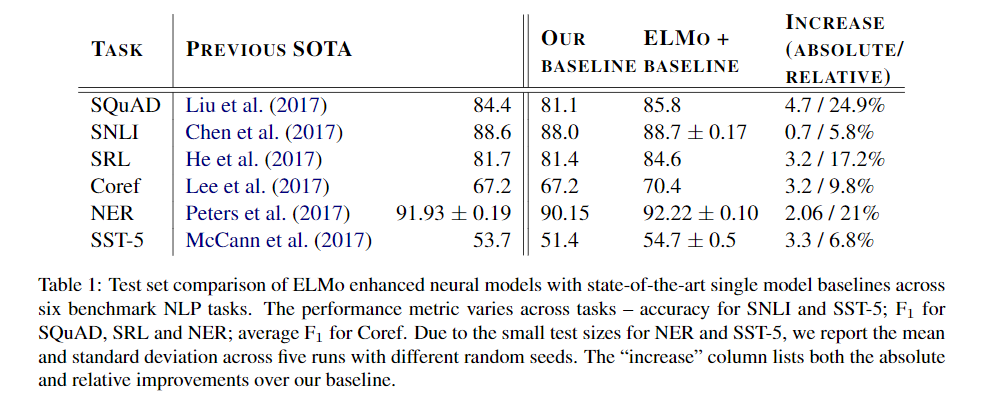
提升效果
语法和语义
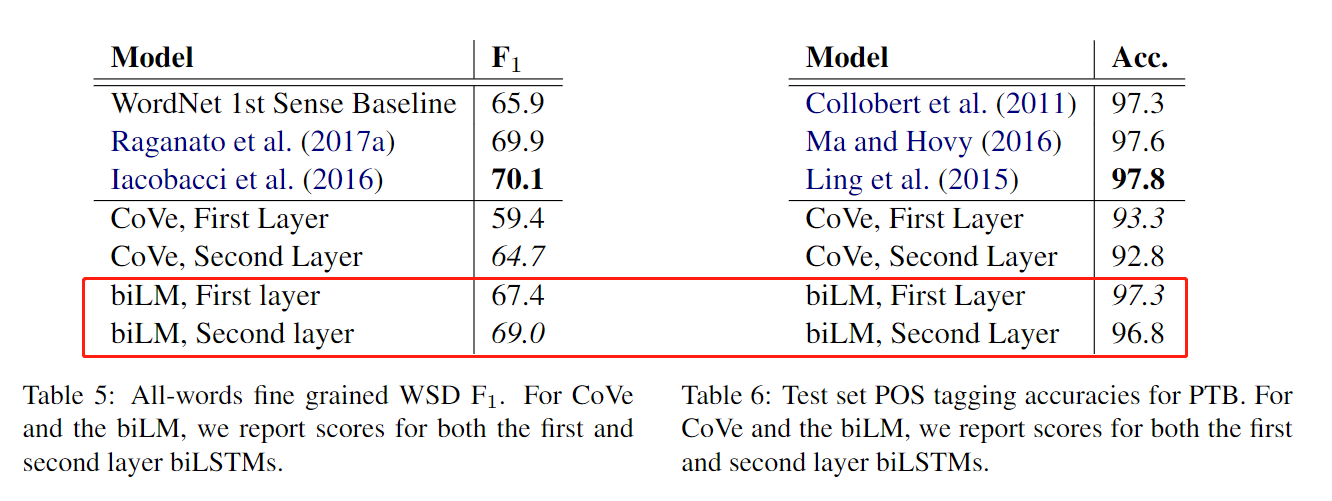
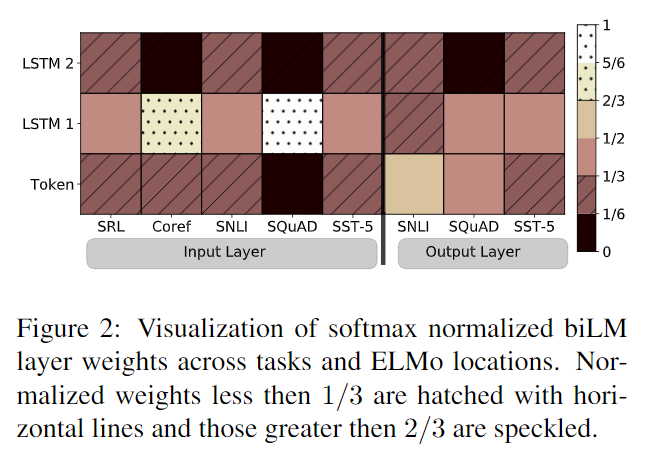
低层偏向语法信息,高层偏向语义信息。
偏爱语法信息
很多模型都偏爱低层的语法信息。
小数据集提升