阿里小蜜的任务型问答
小蜜包含QA问答、开放域聊天、任务型对话。
任务型对话
1、TaskBot:由任务驱动的多轮对话,每一轮去读取用户的slot信息,直到槽填满,全部ok
2、Action Policy:强化学习去管理多轮对话,小蜜每一轮给出一个动作,询问用户或者完成订单
3、Belief Tracker:深度学习去提取slot信息,LSTM-CRF标注
1. TaskBot
任务型对话是指由任务驱动的多轮对话。在对话中帮助用户完成某个任务,比如订机票、订酒店等。
传统:用slot filling来做,但需要大量人工模板、规则和训练语料小蜜:基于强化学习和Neural Belief Tracker的端到端可训练的TaskBot方案
在每轮对话中,都需要抽取用户当前给的slot状态(任务需要的组件信息)。不断地去填满所有的slot,最后去下单。
2. Action Policy - 强化学习
系统如何给用户合适的回复:接着询问用户、出订单。使用强化学习去管理这个多轮对话。各个定义如下:
- 智能体:小蜜(系统)
- 策略:小蜜给用户的回答,反问哪个slot、出订单
- 环境:用户
- 状态:用户回答中提取出的slot状态(信息)
- 反馈:继续聊天、退出、下单
3. Belief Tracker - 深度学习
Belief Tracker用来提取用户的slot状态,实际是一个序列标注问题。使用LSTM-CRF进行标注。传统是slot filling
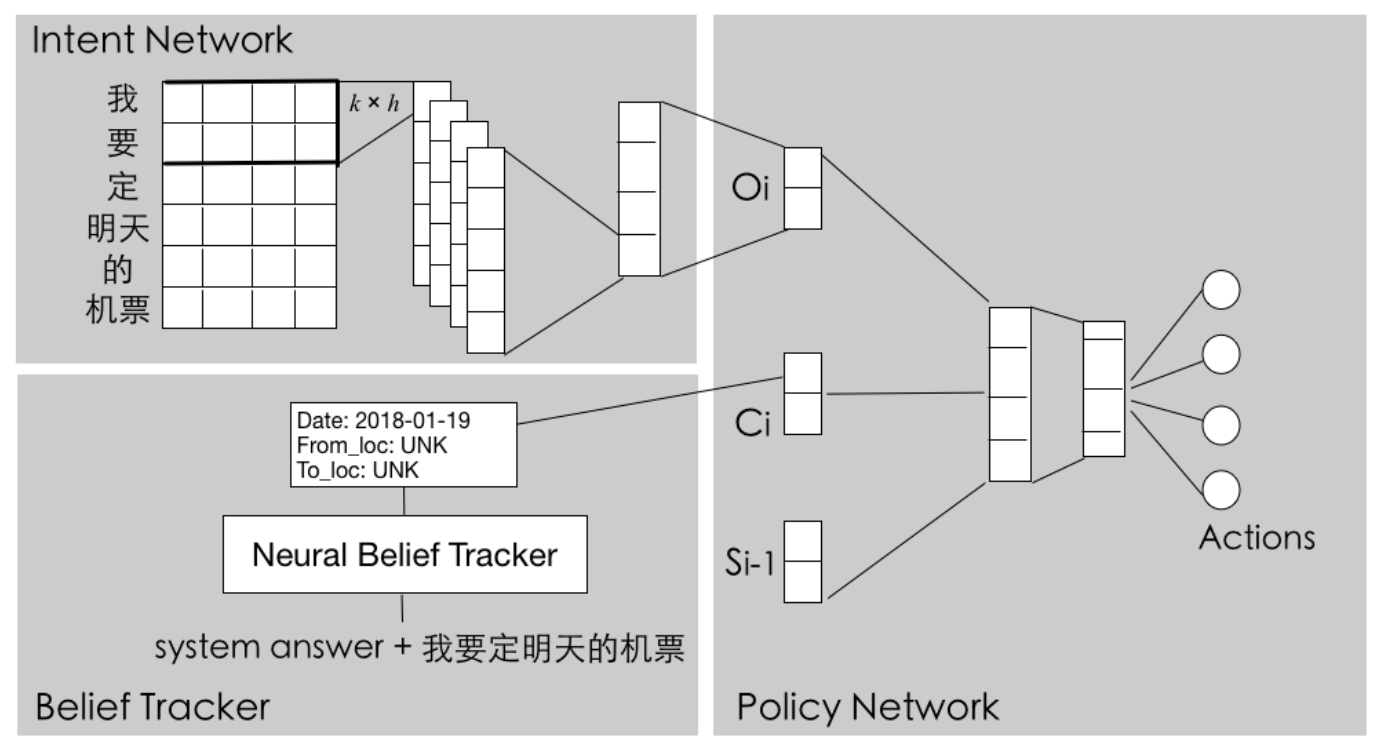
系统结构
系统分为下面三层。
数据预处理层: 分词、实体抽取等。端到端的对话管理层:强化学习任务生成层
强化学习包括:
- Intent Network :处理用户输入
- Neural Belief Tracker :记录读取slot信息
- Policy Network :决定小蜜的回答:反问哪个slot 或 出订单。
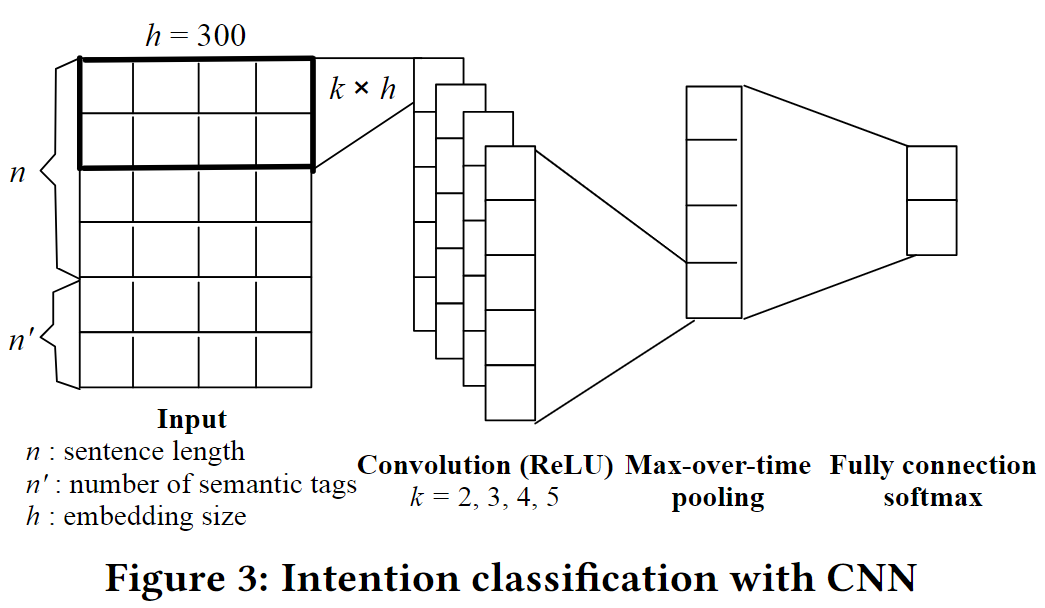
Intent Network
阿里小蜜意图分类。使用CNN学一个sentence embedding来表示用户的意图。后面给到Policy Network。
Belief Tracker
使用BiLSTM-CRF来进行标记句子,提取出slot信息。
| 句子 | first | class | fares | from | Boston | to | Denver |
|---|---|---|---|---|---|---|---|
| Slots | B-机舱类别 | I-机舱类别 | O | O | B-出发地 | O | B-目的地 |
Policy Network
四个关键:episode、reward、state、action。
1. 一轮交互的定义
- episode开始:识别出用户意图为
购买机票 - episode结束:用户
成功购买机票或退出会话
2. 反馈
获取用户的反馈非常关键。
- 收集线上用户的反馈,如用户下单、退出等行为
- 使用预训练环境
预训练环境的两部分反馈
- Action Policy :策略梯度 更新模型。正反馈\(r=1\),负反馈\(r=-1\)
- Belief Tracker:仅使用正反馈作为正例,出现错误由小二标出正确的slots
3. 状态
当前slot:Intent Network得到的Sentence Embedding,再过Belief Tracker得到的slot信息。
使用当前slot+历史slot,过线性层,softmax,到各个Action。
4. 动作
订机票,Action是离散的。主要是:对各个Slot的反问和下单。
整体模型
符号定义
- \(q_i\) :当前用户的问题
- \(a_{i-1}\) :上一轮问题的答案
- \(S_i\) :历史slot信息
\[ \begin{align} & O_i = \rm{IntentNet}(q_i) \\ & C_i = \rm{BeliefTracker}(q_i, a_{i-1}) \\ & X_i = O_i \oplus C_i \oplus S_{i-1} \\ & H_i = \rm{Linear} (X_i) \\ & P(\cdot) = \rm{Softmax}(H_i) \end{align} \]