Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling
背景
语义理解的两个方面
1. 语义理解的两个主要方面
在对话系统中,Spoken language understanding(语言理解)很重要。主要是下面两个关键点:
- 理解说话人的意图 -- 意图检测(Intent Detection)
- 从句子中提取语义成分 -- 槽填充(Slot Filling)
2. 意图检测
意图检测是一个语义句子的分类问题。可以用SVM、DNN来进行分类。
3. 槽填充
槽填充是要读取句子中的一些语义成分,是一个序列标注问题。可以用MEMMs来做。
4. 处理
传统一般是用两个模型去分别处理意图检测和槽填充,现在可以使用一个模型Encoder-Decoder去同时解决这两个问题。
5. 对齐和注意力
序列标注具有明确的对齐信息。
输入n,输出n,相同长度。输入和输出每一个位置严格对齐。Alignment-based RNN。
输入n,输出m,不同长度,本身不具有对齐信息。需要注意力机制来进行对齐。Attention-based Encoder-Decoder。
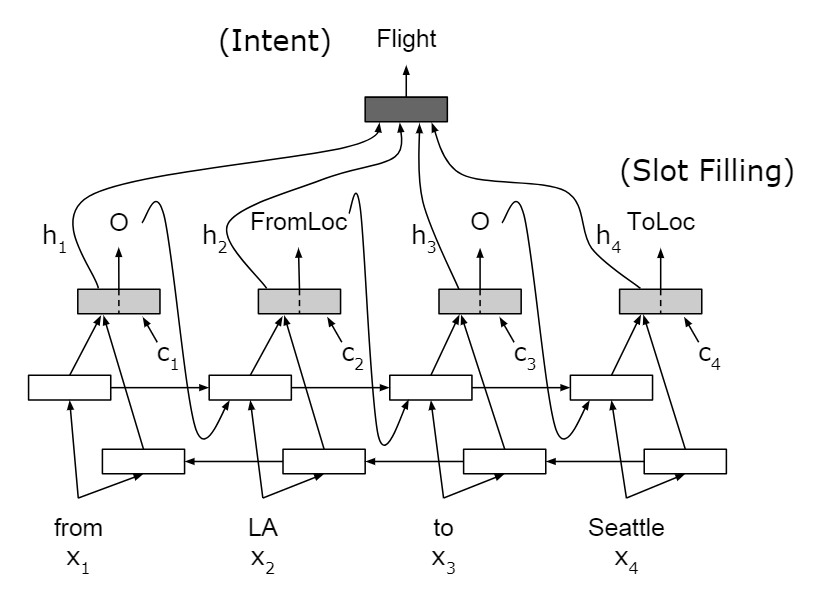
槽填充
1. 问题
槽填充是一个序列标注问题,具有明确的对齐信息。
| 句子 | first | class | fares | from | Boston | to | Denver |
|---|---|---|---|---|---|---|---|
| Slots | B-机舱类别 | I-机舱类别 | O | O | B-出发地 | O | B-目的地 |
意图:订机票。
本质上是学得一个映射函数\(\cal {X \to Y}\)。训练样本:\(\{ (\mathbf x^{(n)}, \mathbf y^{(n)}), n=1,\cdots, N \}\)。
2. RNN 槽填充
符号定义
- \(\mathbf x\) :输入序列
- \(\mathbf y\) :输出序列
- \(y_t\) :第t个单词的slot lable
预测\(y_t\),需要\(\mathbf x\)和\(y_{t-1}\)。
训练是找到一个最大的使概率似然最大的参数\(\theta\) : \[ \arg \max_{\theta} \prod P(y_t \mid y_{t-1}, \mathbf x; \theta) \] 预测是找到最大概率的标记序列\(\mathbf y\) \[ \mathbf {\hat y} = \arg \max_{\mathbf y} P(\mathbf y \mid \mathbf x) \] 3. RNN Encoder-Decoder 槽填充
序列标注有明确的对齐信息,所以先没有使用注意力机制。把\(\mathbf x\)编码为语义向量\(\mathbf c\): \[
P(\mathbf y) = \prod_{t=1}^T P(y_t \mid y_{t-1}, \mathbf c)
\] Seq2Seq可以处理不同长度的映射信息,这时没有明确的对齐信息。但是可以使用注意力机制来进行软对齐Soft Alignment。
两种方法
Seq2Seq方法
Encoder-Decoder with Aligned Inputs
1. 编码
使用双向RNN对输入序列进行编码,\(\mathbf {h_i} = [fh_i, bh_i]\)。
2. 意图识别
最后时刻的隐状态\(\mathbf {h_T}\)携带了整个句子的信息,使用它进行意图分类。
3. 槽填充
用单向RNN作为Decoder。初始\(\mathbf s_0= \mathbf h_T\)。有3种方式:
只有注意力输入
只有对齐输入
有注意力和对齐两个输入
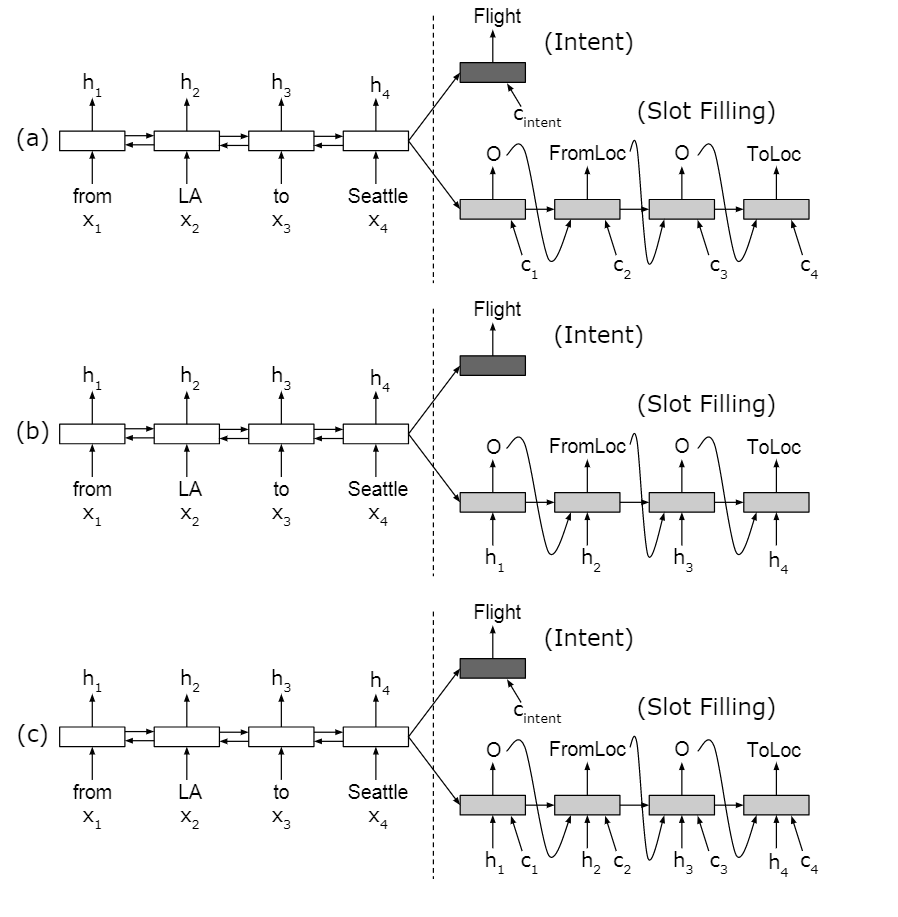
4. 带注意力和对齐输入的RNN槽填充计算方式 \[ s_0 = h_T \] 计算注意力的上下文\(\mathbf c_i\) \[ \alpha_{ij} = \rm{softmax}(e_{ij}) \]
\[ e_{ij} = g(\mathbf s_{i-1}, \mathbf h_k) \]
\[ \mathbf c_i = \sum_{j=1}^T\alpha_{ij} \mathbf h_j \]
计算新的状态 \[ s_i = f(\mathbf s_{i-1}, y_{i-1}, \mathbf h_i, \mathbf c_i) \]
基于注意力的RNN