AliMe Chat: A Sequence to Sequence and Rerank based Chatbot Engine
AliMe Chat
概览
1. IR Model
Information Retrieval。有一个QA对知识库,给一个问题,选择最相似的问题Pair,得出答案。
缺点:很难处理那些不在QA知识库里面的Long tail问句
2. Generation Model
(Seq2Seq) :基于Question生成一个回答
缺点:会产生一些不连贯或者没意义的回答
3. 小蜜的混合模型
集成了IR和生成式模型。
- 收到一个句子
- IR模型:从QA知识库中选择一些答案作为候选答案
- 打分模型:利用
Attentive Seq2Seq对候选答案进行打分 - 最高得分大于
阈值,直接输出该得分 - 生成式模型:否则,利用生成式模型生成一个回答
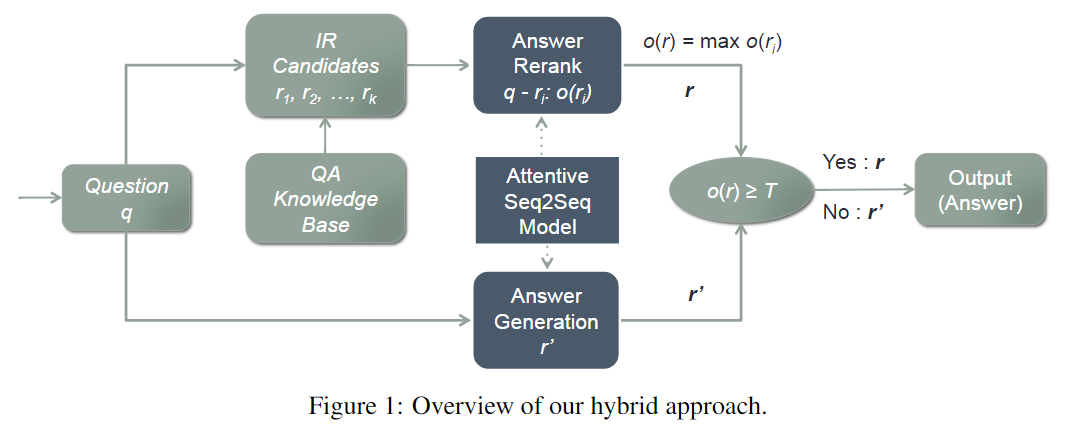
QA知识库
从用户和员工的对话数据中,提取一些问题和答案。也会把几个问题连在一起。最终共9164834个QA对。
IR模型
1. IR步骤
- 建立索引:每个单词 -- 多个问题
- 收到一个问句计算它的词集:分词 -- 去掉停用词 -- 扩展同义词
- 利用词集和索引去找到若干个QA对
- 利用BM25算法,去计算问句和所有候选QA对里问题的相似度
- 选择最相似的QA对
2. BM25算法
BM25通常用来搜索相关性评分。
一个query和一个d 。把query分割成\(K\)个语素\(q_i\)(中文是分词) \[
\rm{score}(q, d) = \sum_{i}^K w_i \cdot r(q_i, d)
\] \(w_i\)是判断一个词与一个文档的相关性权重。这里使用IDF来计算。
- \(N\)是总文档数,\(N(q_i)\)为包含词\(q_i\)的文档数
- \(f_i\) 为\(q_i\)在d中的出现频率,\(g_i\)为\(q_i\)在\(q\)中的出现频率
- \(d_l\) 为\(d\)的长度,\(\rm{avg}(d_l)\)是所有文档的长度
- \(k_1, k_2, b\) 为调节因子,一般\(k_1=2,b=0.75\)
\[ w_i = \rm{IDF}(q_i) = \log \frac{N - N(q_i) + 0.5}{N(q_i) + 0.5} \]
\[ r(q_i, d) = \frac{f_i \cdot (k_1 + 1)} {f_i + K} \cdot \frac{g_i \cdot (k_2 +1 )}{g_i + k_2} \]
\[ K = k_1 \cdot (1 - b + b \cdot \frac{d_l}{\rm{avg}(d_l)}) \]
特别地,一般\(q_i\)只在\(q\)中出现一次,即\(g_i = 1\), 则 \[ r(q_i, d) = \frac{f_i \cdot (k_1 + 1)} {f_i + K} \] 调节因子
- K :相同\(f_i\)的情况下,文档越长,相似性越低
- b:越大,提高长文档与\(q_i\)的相似性
生成式模型
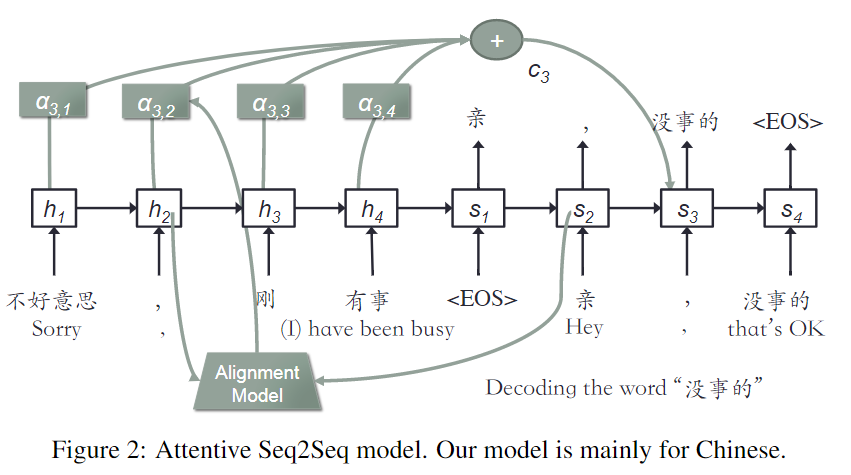
1. Attentive Seq2Seq
- 输入问句的语义信息: \((h_1, h_2, \cdots, h_m)\)
- 上一时刻的单词和隐状态:\(y_{i-1},s_{i-1}\)
- 计算注意力分布:\(\alpha_{ij} = a(s_{i-1}, h_j)\)
- 语义信息:\(c_i = \sum_{j=1}^m \alpha_{ij}h_j\)
- 预测当前单词:\(p(y_i=w_i \mid \theta_i) = p(y_i=w_i \mid y_1, \cdots, y_{i-1}, c_i) = f(y_{i-1}, s_{i-1}, c_i)\)
2. 数据padding
利用Tensorflow的Bucket Mechanism组织。选择(5,5),(5,10),(10,15),(20,30),(45,60)。
3. Softmax
训练时,softmax词表使用目标词汇+512个随机词汇。
4. BeamSearch 解码
每个时刻选择top-k(k=10)
打分模型
打分模型,对所有候选答案计算一个得分,然后选择得分最高的答案。
生成式模型,在解码时会计算各个单词的概率。打分模型和生成式模型使用同一个模型。
打分模型,计算候选回答中每个单词在Decoder时出现的概率。再求平均值作为该回答的得分。 \[ s^{\text{avg}(p)} = \frac{1}{n} \sum_{i=1}^n p(y_i = w_i \mid \theta_i) \]
评价方法
5个评价规则:
- 语法正确
- 意义相关
- 标准的表达
- 上下文无关 context independent
- not overly generalized
答案的三个级别:
- 2 :适合。满足所有规则
- 1: 一般。满足前三项,不满足后面两项其中一项
- 0:不适合
top-1概率 \[ P_{\rm{top}_1} = \frac{N_{合适} + N_{一般}}{N_{所有}} \]
阿里小蜜助手
小蜜主要包括:助手(Task)服务、客户服务、聊天服务。支持声音、文本输入,支持多轮对话。
系统概览
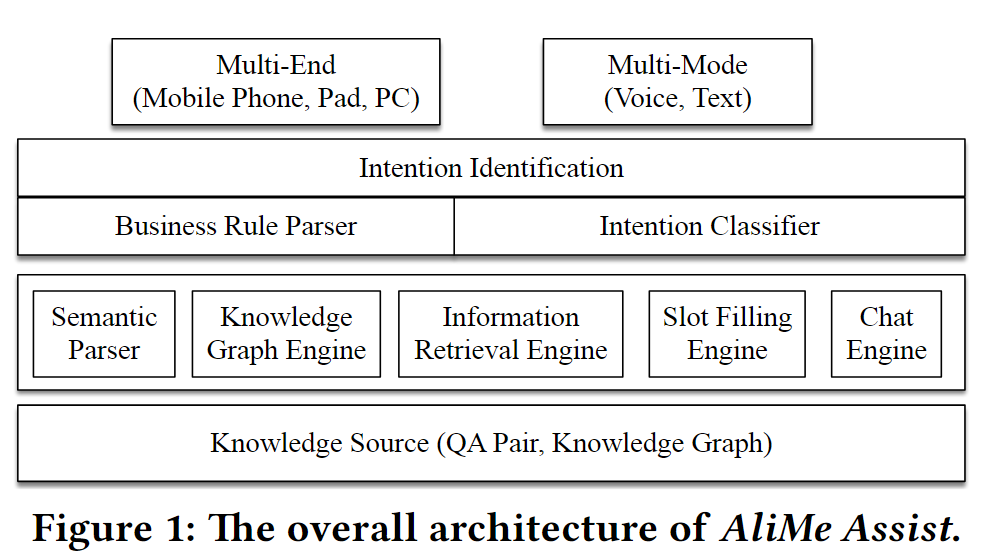
1. 系统概览
- 输入层:接收多个终端和多种形式的输入
- 意图分类层:
Rules Parser直接解析意图,失败则通过Intention Classifier解析意图 - 处理问题组件层:语义解析、知识图引擎、信息提取引擎、Slot Filling引擎、聊天引擎
- 知识库:QA对,知识图。
2. 问题的信息流
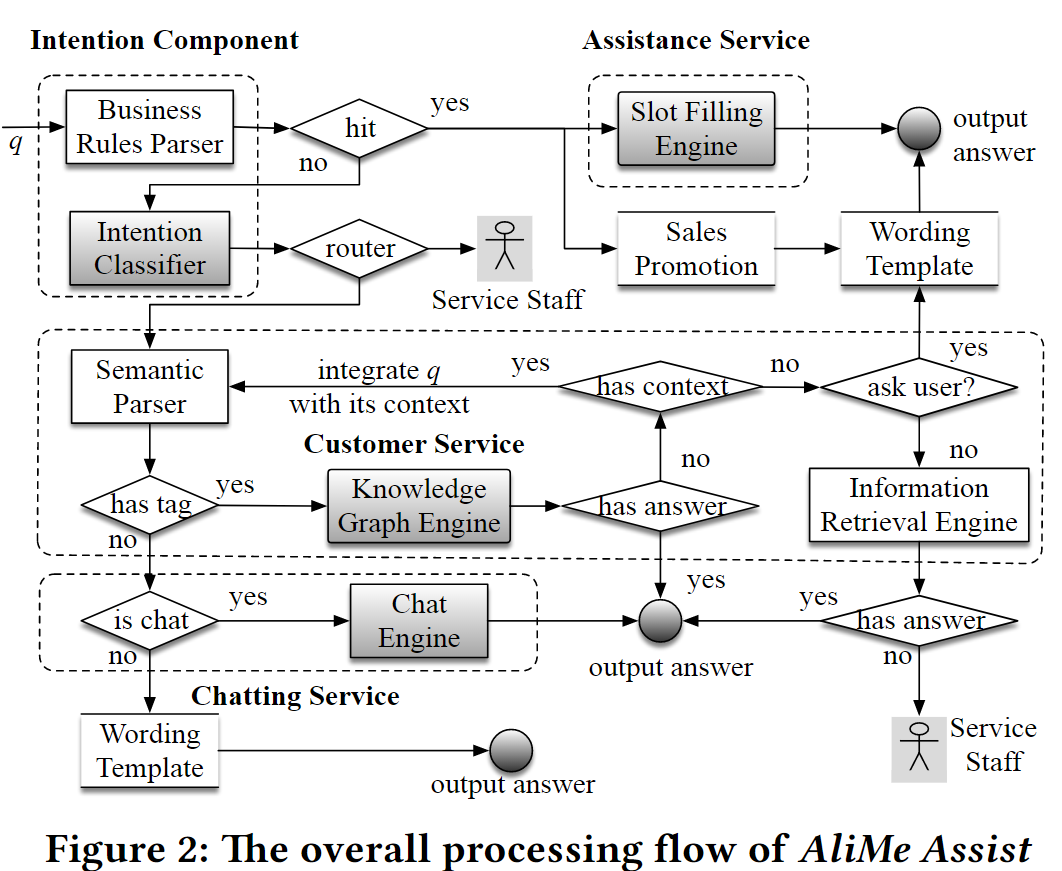
收到一个问句后
1 使用Business Rules Parser (trie-based)去解析q,如果匹配到一个模式
- q是一个任务型的问题(助手服务):给
Slot Filling Engine(槽填充) 直接给答案 - q是一个促销活动:给到
Sales Promotion,回答准备好的答案 - q是请求人工:则先询问客户有什么问题
2 没有匹配到一个模式,给到意图分类器去识别意图,也就是识别出意图的场景(比如退货、退款、人工等)
3 如果场景是要转人工,则直接转人工
4 否则,q给到语义解析器,去识别是否包含语义标签(知识图谱中的实体)
- 如果识别出语义标签,则通过知识图谱去找答案,如果找到直接输出
- 如果知识图谱没有答案
- 如果有上下文,结合上下文和q再去解析语义,再给到语义解析器解析语义标签
- 如果没有上下文,则判断是否要询问用户
- 如果要询问,则通过模板去询问用户
- 如果不用询问,则通过
IR去提取信息,如果有答案,则输出;如果没有,则转人工
5 如果不包含语义标签
- 如果要聊天,则通过聊天引擎去产生结果
- 否则,通过词模板去输出结果
意图分类
对一个问句结合上下文(前面的文件)去识别出它的意图。有3个大范围:
- 助手。我要订机票
- 信息咨询、解决方案。怎么找回密码
- 聊天。我不开心
每一个大的范围都会进行商业细化。比如助手服务会包含订机票、手机充值。
意图分类由商业规则解析器和意图分类器组成。前者解析失败,才会执行后者
- 规则解析器:一颗很大的trie树,写了很多的规则
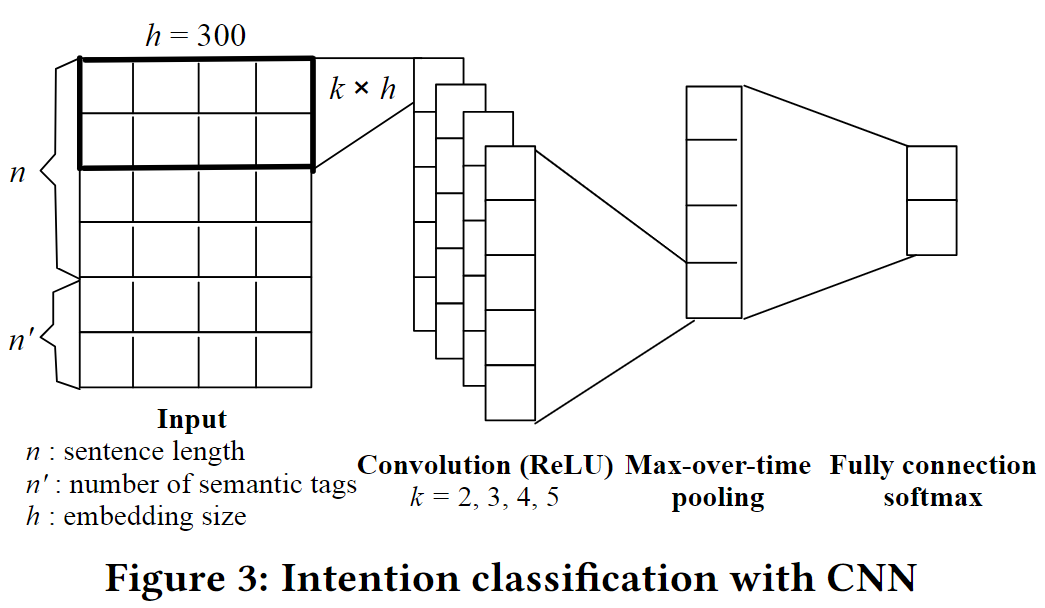
- 意图分类器:CNN
CNN,使用fast-text训练的词向量,fine tuned in CNN
- 输入1:问题q
- 输入2:问题q和上下文(之前的问题)的语义标签
CNN的好处
- 也可以捕获上下文信息(前一个和后一个),足够好、够用的结果就行
- CNN快啊,QPS=200,Query per Second
- 多个卷积池化层或者RNN能实现一个更好的结果,但是扩展性不好?为什么?
TaskBot
主要是以强化学习为中心的端到端的对话管理,由下面三个部分组成:
Intent network
处理用户的输入
使用单层CNN对用户的问句进行编码,得到用户的意图语义向量
Neural belief tracker
提取记录用户的slot信息
- 使用BiLSTM-CRF来提取用户每次输入的slot信息
- 根据上一轮系统的回答和当前用户的问句生成当前的Context信息,给到后面的Policy Network
- 优点是:BiLSTM可以挖掘出当前词的Context信息,而CRF能有效地对标记序列进行建模
Policy networker
决定系统的操作,继续反问用户或者直接产生相应的实际操作
这也是强化学习的核心点,主要包含Episode,Reward,State和Action四个部分。 Episode 在某个场景下,识别出用户该场景的意图,则认为一个Episode开始;执行目的操作或者退出,则认为Episode结束 Reward 收集线上用户的反馈,并根据正负给出相应的Reward。特别注意要使用预训练的环境 State 结合当前新的Slot状态(Context)、历史的Slot信息和用户的当前问句信息,使用线性层+Softmax直接算出各个Actions的概率 Action Action就是系统可以给用户的一些反馈操作,比如继续询问用户、执行一个真实的操作等等。
该Taskbot的瓶颈主要是难以确定用户退出的原因,从而很难给出一些确定的惩罚。

