谷歌神经机器翻译系统,Transformer之前最强的基于RNN的翻译模型
简介
神经机器翻译是自动翻译的端到端的学习方法,克服了传统的基于词典翻译的许多缺点。但仍然有以下的缺点
- 训练和翻译都太慢了,花费代价很大
- 缺乏鲁棒性,特别是输入句子包含生僻词汇
- 精确度和速度也不行
传统NMT缺点
神经机器翻译(NMT)是自动翻译的端到端的学习方法。NMT一般由两个RNN组成,分别处理输入句子和生成目标句子。一般会使用注意力机制,会有效地去处理长句子。
NMT避开了传统基于短语的翻译模型的很多缺点。但是,在实际中,NMT的准确度要比基于短语的翻译模型更差些。
NMT有3个主要的缺点:训练和推理速度太慢,不能有效处理稀有词汇,有时不能完全翻译原句子。
训练和推理速度太慢
训练大数据集,需要大量时间和资源;反馈太慢周期太长。加了一个小技巧,看结果要等很长时间。推理翻译的时候,要使用大量的参数去计算,也很慢。
不能有效处理稀有词汇
有两个方法去复制稀有单词:
- 模仿传统对齐模型去训练1个
copy model - 使用注意力机制去复制
但是效果都不是很好,都不可靠,不同语言的对齐效果差;在网络很深的时候,注意力机制的对齐向量也不稳定。而且,简单的复制过去也不是最好的办法,比如需要直译的时候。
不能完整翻译整个句子
不能覆盖整个输入句子的内容,然后会导致一些奇怪的翻译结果。
GNMT的模型优点
采用的模型:深层LSTM 、Encoder8层、Decoder8层 。我的LSTM笔记。
各层之间使用残差连接促进梯度流,顶层Enocder到底层Decoder使用注意力连接,提高并行性。
进行翻译推断的时候,使用低精度算法,去加速翻译。
处理稀有词汇:使用sub-word单元,也称作wordpieces方法。把单词划分到有限的sub-word (wordpieces)单元集合,输入输出都这样。sub-word结合了字符分割模型的弹性和单词分割模型的效率。
Beam Search 使用长度规范化和覆盖惩罚。覆盖惩罚就是说,希望,翻译的结果句子,尽量多地包含输入句子中的所有词汇。
使用强化学习去优化模型, 优化翻译的BLEU 分数。
先进技术
有很多先进的技术来提高NMT,下面这些都有论文的。
- 利用attention去处理稀有词汇
- 建立翻译覆盖的机制
- 多任务和半监督训练,去合并使用更多数据
- 字符分割的encoder和decoder
- 使用subword单元处理稀疏的输出
系统架构
系统总览
架构
有3个模块:Encoder,Decoder,Attention。
Encdoer:把句子转换成一系列的向量,每一个向量代表一个输入词汇(符号)。
Decoder:根据这些向量,每一时刻会生成一个目标词汇,直到EOS。
Attention:连接Encoder和Decoder,在解码的过程中,可以让Decoder有权重的有选择的关注输入句子的部分区域。
符号说明
- 加粗小写代表向量,如\(\boldsymbol {v, o_i}\)
- 加粗大写,矩阵,如\(\boldsymbol {U, W}\) 和\(\mathbf{U, W}\)
- 手写体,集合,如\(\mathcal{V, F}\)
- 大写字母,句子,如\(X, Y\)
- 小写字母,单个符号,如\(x_1, x_2\)
Encoder
输入句子和目标句子组成一个Pair \((X, Y)\),其中输入句子\(X = x_1, x_2, \cdots, x_M\) ,\(M\) 个单词,翻译的输出目标句子\(Y = y_1, y_2, \cdots, y_N\) ,有\(N\)个单词。
Encoder其实就是一个转换函数,得到\(M\)个长度固定的向量,也就是其中Encoder对各个\(x_i\)的编码向量 \(\mathbf{x_i}\) : \[ \mathbf {x_1, x_2, \cdots, x_M} = \mathit{EncoderRNN} (x_1, x_2, \cdots, x_n) \] 使用链式条件概率可得到翻译概率\(\color{blue} {P (Y \mid X)}\) ,其中\(y_0\)是起始符号\(SOS\) 。 \[ \begin{align} P(Y \mid X) & = P(Y \mid \mathbf{x_1, x_2, \cdots, x_M}) \\ & =\prod_{i=1}^N P(y_i \mid y_0, \cdots, y_{i-1}; \mathbf{x_1, x_2, \cdots, x_M}) \\ \end{align} \] Decoder
在翻译\(y_i\)的时候, 利用Encoder得到的编码向量\(\mathbf{x_i}\) 和 \(y_0 \sim y_{i-1}\) 来进行计算概率翻译 \[ P(y_i \mid y_0, \cdots, y_{i-1}; \mathbf{x_1, x_2, \cdots, x_M}) \] Decoder是由RNN+Softmax构成的。会得到一个隐状态\(\mathbf{y_i}\) 向量,有2个作用:
- 作为下一个RNN的输入
- \(\mathbf{y_i}\)经过softmax得到概率分布, 选出\(y_i\) 输出符号
Attention
在之前的文章里有介绍论文 和 通俗理解,其实就是影响力模型。原句子的各个单词对翻译当前单词分别有多少的影响力,也叫作对齐概率吧。使用decoder-RNN的输出\(\mathbf{y_{t-1}}\) 向量作为时刻\(t\)的输入。
时刻\(t\),给定\(\mathbf{y_{t-1}}\)
有3个符号定义:
- \(s_i\) : \(y_t\)与\(x_i\)的得分,在luong论文里面有3种计算方式,分别是dot, general和concat。
- \(p_i\) :\(y_t\)与\(x_i\)的对齐概率,\((p_1, p_2, \cdots, p_M)\) 联合起来就是\(y_t\)与\(X\)的对齐向量。其实就是对得分softmax。
- \(\mathbf{a_t}\) :带注意力的语义向量。对于所有的\(x_i\),使用\(y_t\)与它的对齐概率\(p_i\)乘以本身的编码向量\(\mathbf{x_i}\),得到\(x_i\)传达的语义,再对所有的语义求和,即得到总体的带有注意力的语义。
整体详细计算的流程,如下面的公式: \[ \begin {align} & s_i = \mathit{AttentionFunction} (\mathbf{y_{t-1}}, \mathbf{x_i}), \quad i \in [1, M] \\ & p_i = \frac {\exp (s_i)}{\sum_{j=1}^M \exp(s_j)} \quad i \in [1, M] \\ & \mathbf{a_t} = \sum_{i=1}^M p_i \cdot \mathbf{x_i} \quad \color{blue}{对所有带注意力的x_i的语义求和得总体的语义} \end{align} \] 计算打分的函数即\(\mathit{AttentionFunction}\)是一个有隐藏层的前馈网络!实现是Badh这个人的,不是Luong的。
系统架构图说明
架构图如下
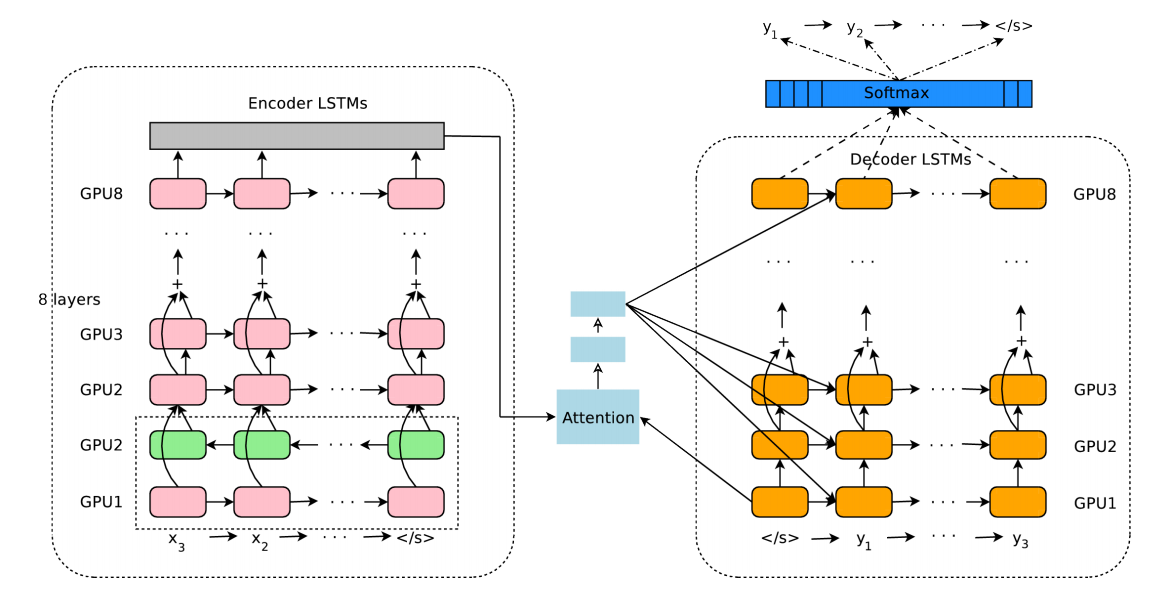
Encoder是8层的LSTM:最底层是双向的LSTM,得到两个方向的信息;上面7层都是单向的。Encoder和Decoder的残差连接都是从第3层开始的。
训练时,会让Encoder最底层的双向的LSTM开始训练,完成之后,再训练别的层,每层都用单独的GPU。
为了提高并行性,Decoder最底层,只是为了用来计算Attention Context。带注意力的语义计算好之后,会单独发给其它的各个层。
经验说明
实验结果得到,要想NMT有好效果,Encoder和Decoder的网络层数一定要够深,才能发现2种语言之间的细微异常规则。和这个同理,深层LSTM比浅层LSTM明显效果好。每加一层,会大约减少10%的perplexity。所以使用deep stacked LSTM。
残差连接
残差网络讲解 。
虽然深层LSTM比浅层LSTM效果好,但是如果只是简单堆积的话,只在几个少数层效果才可以。经过试验,4层的话估计效果还可以,6层大部分都不好,8层的话,效果就相当差了。这是因为网络会变得很慢和很难训练,很大程度是因为梯度爆炸和梯度消失的问题。
根据在中间层和目标之间建立差别的思想,引入残差连接,如下图右边所示。其实就是把之前层的输入和当前的输出合并起来,作为下一层的输入。
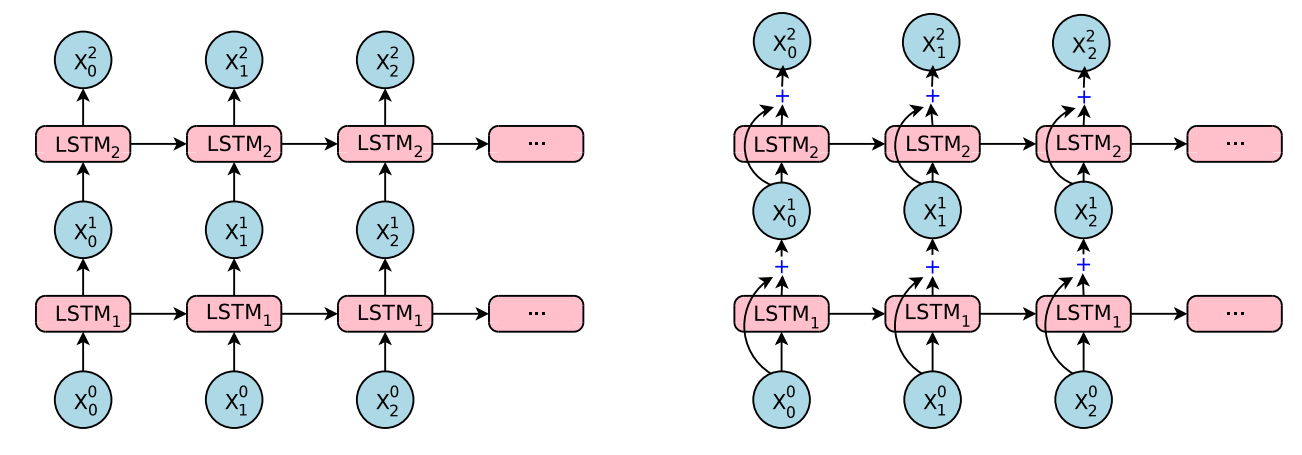
一些参数和符号说明,一下均是时刻\(t\)
- \(\mathbf{x^i_t}\) : 第\(i+1\)层 \(\mathit{LSTM}_{i+1}\)的输入。 即上标代表LSTM的层数,下标代表时间。
- \(\mathbf{W} ^i\) : 第\(i\)层LSTM的参数
- \(\mathbf {h} _t^i\) : 第\(i\)层输出隐状态
- \(\mathbf {c} ^i_t\) : 第\(i\)层输出单元状态
那么\(LSTM_i\)和\(LSTM_{i+1}\)是这样交互的。即层层纵向传递输入,时间横向传递隐状态和单元状态。 \[ \begin{align} & \mathbf{c}_t^i, \mathbf{h}_t^i = LSTM_i(\mathbf{c}_{t-1}^i, \mathbf{h}_{t-1}^i, \mathbf x_{t}^{i-1} ; \; \mathbf W^i ) \\ & \mathbf x_t^i = \mathbf h_t^i \quad\quad\quad\quad \color{blue}{普通连接:i+1层输入=i层隐层输出} \\ & \mathbf{x}_t^i = \mathbf h_t^i + \mathbf{x}_t^{i-1} \quad \color{blue} {残差连接:第i+1层的输入=i层输入+i层隐层输出} \\ & \mathbf{c}_t^{i+1}, \mathbf{h}_t^{i+1} = LSTM_{i+1} (\mathbf c_{t-1}^{i+1}, \mathbf {h} _{t-1}^{i+1}, x_{t}^i ; \; \mathbf W ^{i+1}) \\ \end{align} \] 残差连接可以在反向传播的时候大幅度提升梯度流,这样就可以训练很深的网络。
双向Encoder
一般输入的句子是从左到右,输出也是。但是由于语言的复杂性,有助于翻译的关键信息可能在原句子的不同地方。为了在Encoder中的每一个点都有最好的上下文语义,所以需要使用双向LSTM。
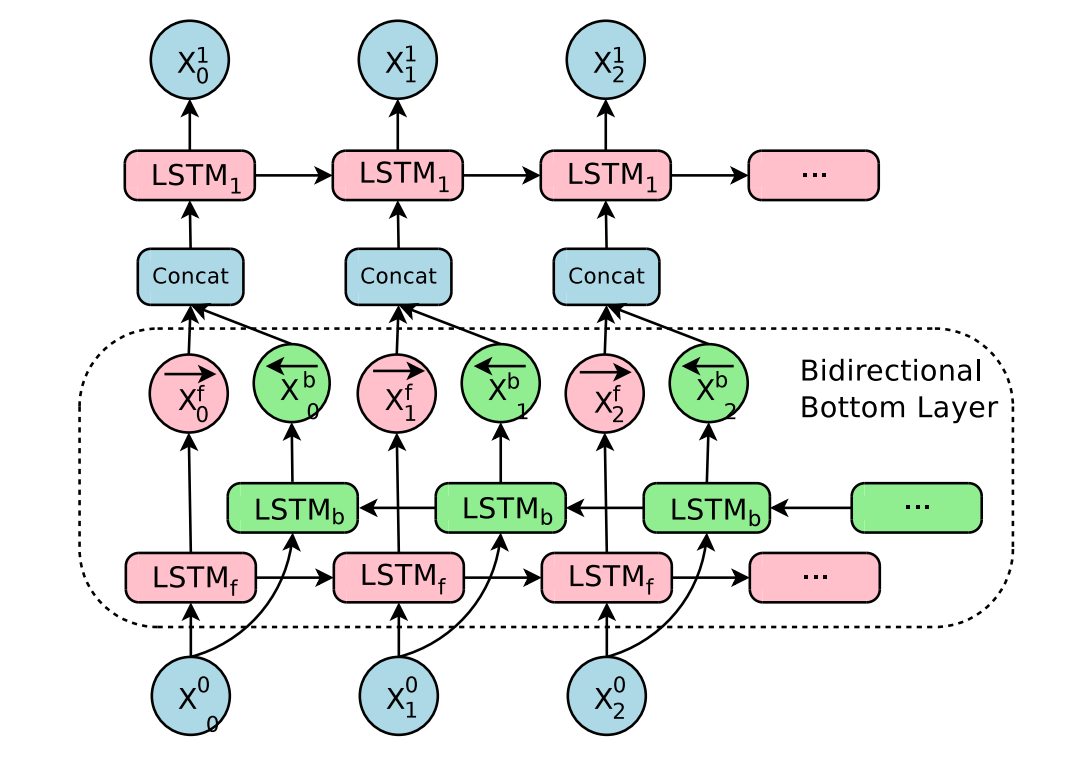
这里只在Encoder的最底层使用双向LSTM,其余各层均使用单向的LSTM。双向LSTM训练完成之后,再训练别的层。
\(LSTM_f\)从左到右处理句子,\(LSTM_b\)从右到左处理句子。把两个方向的信息\(\mathbf{x^f_i}\)和\(\mathbf{x}^b_i\)concat起来,传递给下一层。
模型并行性
模型很复杂,所以使用模型并行和数据并行,来加速。
数据并行
数据并行很简单,使用大规模分布式深度网络(Downpour SGD) 同时训练\(n\)个模型副本,它们都使用相同的模型参数,但是每个副本会使用Adam和SGD去异步地更新参数。每个模型副本一次处理m个句子。一般实验中,\(n=10, m=128\)。
模型并行
除了数据并行以外,模型并行也会加速每个副本的梯度计算。Encoder和Decoder会进行深度去划分,一般每一层会放在一个单独的GPU上。除了第一层的Encoder之外,所有的层都是单向的,所以第\(i+1\)层可以提前运行,不必等到第\(i\)层完全训练好了才进行训练。Softmax也会进行划分,每个处理一部分的单词。
并行带来的约束
由于要并行计算,所以我们不能够在Encoder的所有层上使用双向LSTM。因为如果使用了双向的,上面层必须等到下面层前向后向完全训练好之后才能开始训练,就不能并行计算。在Attention上,我们也只能使用最顶层的Encoder和最底层的Decoder进行对齐计算。如果使用顶层Encoder和顶层Decoder,那么整个Decoder将没有任何并行性,也就享受不到多个GPU的快乐了。
分割技巧
一般NMT都是的词汇表都是定长的,但是实际上词汇表却是开放的。比如人名、地名和日期等等。一般有两种方法去处理OOV(out-of-vocabulary)单词,复制策略和sub-word单元策略。GNMT是使用sub-word单元策略,也称为wordpiece模型。
复制策略
有下面几种复制策略
- 把稀有词汇直接复制到目标句子中,因为大部分都是人名和地名
- 使用注意力模型,添加特别的注意力
- 使用一个外部的对齐模型,去处理稀有词汇
- 使用一个复杂的带有特殊目的的指出网络,去指出稀有词汇
sub-word单元
比如字符,混合单词和字符,更加智能的sub-words。

