前面阐述注意力理论知识,后面简单描述PyTorch利用注意力实现机器翻译
Effective Approaches to Attention-based Neural Machine Translation
简介
Attention介绍
在翻译的时候,选择性的选择一些重要信息。详情看这篇文章 。
本着简单和有效的原则,本论文提出了两种注意力机制。
Global
每次翻译时,都选择关注所有的单词。和Bahdanau的方式 有点相似,但是更简单些。简单原理介绍。
Local
每次翻译时,只选择关注一部分的单词。介于soft和hard注意力之间。(soft和hard见别的论文)。
优点有下面几个
- 比Global和Soft更好计算
- 局部注意力 随处可见、可微,更好实现和训练。
应用范围
在训练神经网络的时候,注意力机制应用十分广泛。让模型在不同的形式之间,学习对齐等等。有下面一些领域:
- 机器翻译
- 语音识别
- 图片描述
- between image objects and agent actions in the dynamic control problem (不懂,以后再说吧)
神经机器翻译
思想
输入句子\(x = (x_1, x_2, \cdots, x_n)\) ,输出目标句子\(y = (y_1, y_2, \cdots, y_m)\) 。
神经机器翻译(Neural machine translation, NMT),利用神经网络,直接对\(\color{blue} {p(y \mid x)}\) 进行建模。一般由Encoder和Decoder构成。Encoder-Decoder介绍文章链接 。
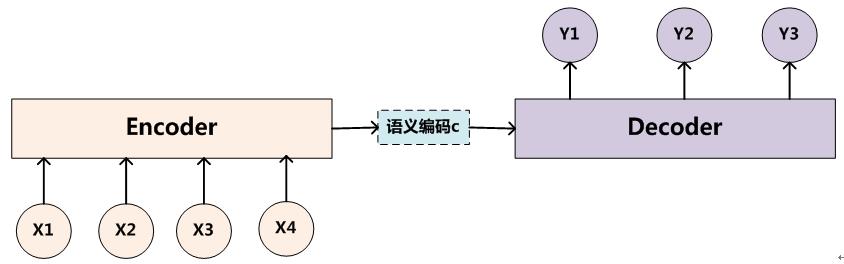
Encoder把输入句子\(x\) 编码成一个语义向量\(s\) (c表示也可以),然后由Decoder 一个一个产生目标单词 \(y_i\) \[ \log p(y \mid x) = \sum_{j=1}^m \log \color{red} {p(y_j \mid y _{<j}, s) } = \sum_{j=1}^m \log p(y_j \mid y_1, \cdots, y_{j-1}, s) \] 但是怎么选择Encoder和Decoder(RNN, CNN, GRU, LSTM),怎么去生成语义\(s\)却有很多选择。
概率计算
结合Decoder上一时刻的隐状态\(\color{blue}{h_{j-1}}\)和encoder给的语义向量\(\color{blue}{s}\),通过函数\(\color{blue}{f}\) ,就可以计算出当前的隐状态\(\color{blue}{h_j}\) : \[
h_j = f(h_{j-1}, s)
\] 通过函数\(\color{blue}{g}\)对当前隐状态\(h_j\)进行转换,再softmax,就可以得到翻译的目标单词\(y_i\)了(选概率最大的那个)。
\(g\)一般是线性变换,维数变化是\([1, h] \to [1, vocab\_size]\)。 \[
p(y_j \mid y _{<j}, s) = \mathrm{softmax} \; g(h_j)
\] 语义向量\(s\) 会贯穿整个翻译的过程,每一步翻译都会使用到语义向量的内容,这就是注意力机制。
本论文的模型
本论文采用stack LSTM的构建NMT系统。如下所示:
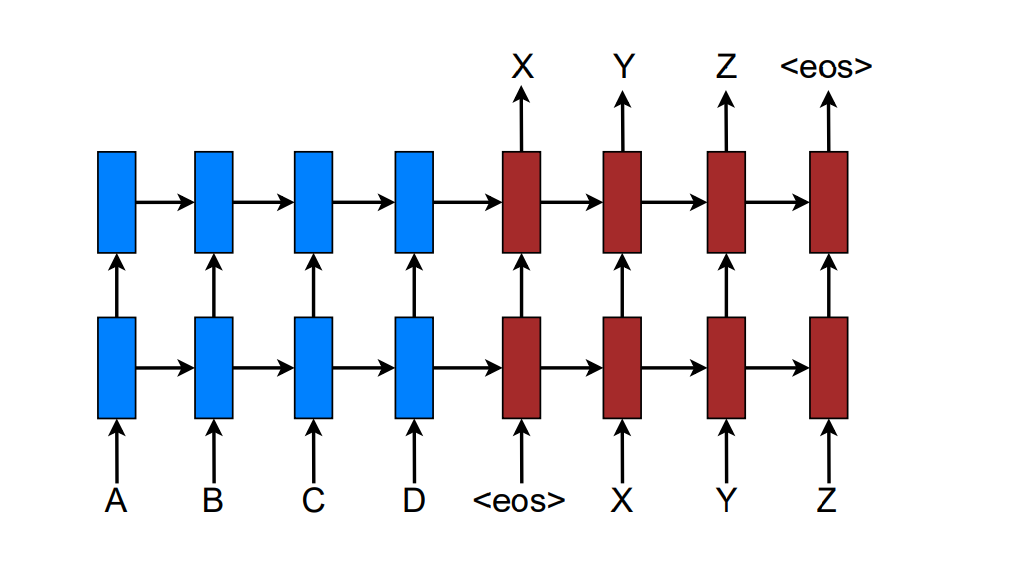
训练目标是 \[ J_t = \sum_{(x, y)} - \log p(y \mid x) \]
注意力模型
注意力模型广义上分为global和local。Global的attention来自于整个序列,而local的只来自于序列的一部分。
解码总体流程
Decoder时,在时刻\(t\),要翻译出单词\(y_t\) ,如下步骤:
- 最顶层LSTM的隐状态 \(h_t\)
- 计算带有原句子信息语义向量\(c_t\)。Global和Local的区别在于\(c_t\)的计算方式不同
- 串联\(h_t, c_t\),计算得到带有注意力的隐状态 \(\hat {h}_t = \tanh (W_c [c_t; h_t])\)
- 通过注意力隐状态得到预测概率 \(p(y_t \mid y_{<t}, x) = \rm {softmax} (W_s \hat h _t)\)
Global Attention
总体思路
在计算\(c_t\) 的时候,会考虑整个encoder的隐状态。Decoder当前隐状态\(h_t\), Encoder时刻s的隐状态\(\bar h _s\)。
对齐向量\(\color{blue}{\alpha_t}\)代表时刻\(t\) 输入序列中的单词对当前单词\(y_t\) 的对齐概率,长度是\(T_x\), 随着输入句子的长度而改变 。\(x_s\)与\(y_t\) 的对齐概率如下: \[ \alpha_t(s) = \mathrm {align} (h_t, \bar h_s) = \frac {score(h_t, \bar h_s)}{ \sum_{i=1}^{T_x} score(h_t, \bar h_i)}, \quad 实际上\mathrm{softmax} \] 结合上面的解码总体流程,有下面的流程 \[ all (\bar h_s) , h_t \to \alpha_t \to c_t . \quad c_t , h_t \to \hat h_t .\quad \hat h_t \to y_t \quad \] 简单来说是\(h_t \to \alpha_t \to c_t \to \hat h_t \to y_t\) 。
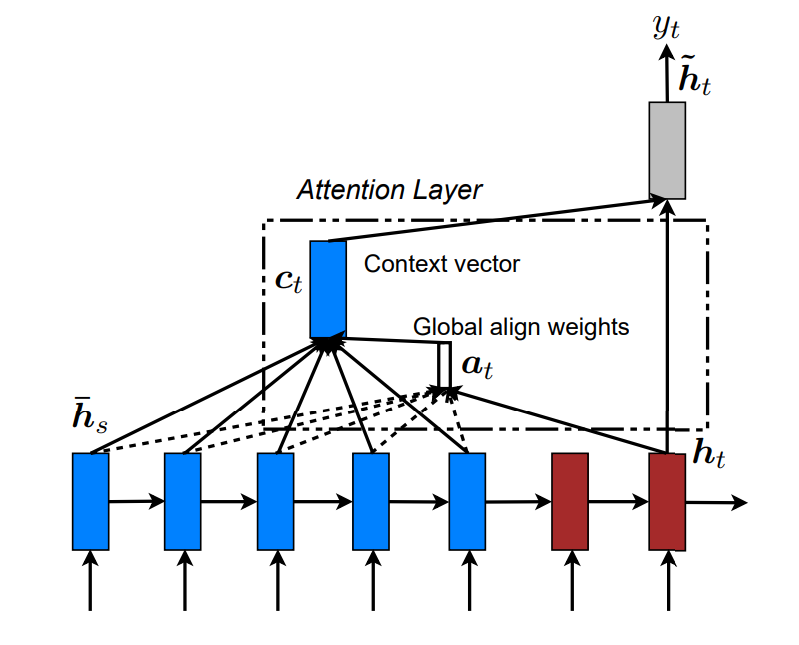
score计算
\(score(h_t, \bar h_s)\) 是一种基于内容content-based的函数,有3种实现方式 \[
\color{blue}{score(h_t, \bar h_s)} =
\begin{cases}
h_t^T \bar h_s & dot \\
h_t^T W_a \bar h_s & general \\
v_a^T \tanh (W_a [h_t; \bar h_s]) & concat \\
\end{cases}
\] 缺点
生成每个目标单词的时候,都必须注意所有的原单词, 这样计算量很大,翻译长序列可能很难,比如段落或者文章。
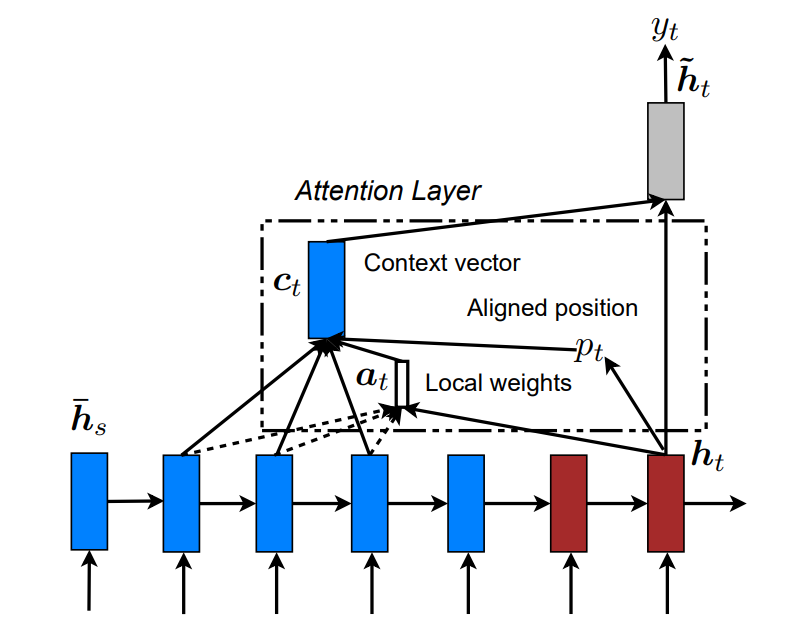
Local Attention
在生成目标单词的时候,Local会选择性地关注一小部分原单词去计算\(\alpha_t, c_t\),这样就解决了Global的问题。如下图
Soft和Hard注意
Soft 注意 :类似global注意,权值会放在图片的所有patches中。计算复杂。
Hard 注意: 不同时刻,会选择不同的patch。虽然计算少,但是non-differentiable,并且需要复杂的技术去训练模型,比如方差减少和强化学习。
Local注意
类似于滑动窗口,计算一个对齐位置\(\color{blue}{p_t}\),根据经验设置窗口大小\(D\),那么需要注意的源单词序列是 : \[ [p_t -D, p_t + D] \] \(\alpha_t\) 的长度就是\(2D\),只需要选择这\(2D\)个单词进行注意力计算,而不是Global的整个序列。
对齐位置选择
对齐位置的选择就很重要,主要有两种办法。
local-m (monotonic) 设置位置, 即以当前单词位置作为对齐位置 \[ p_t = t \] local-p (predictive) 预测位置
\(S\) 是输入句子的长度,预测对齐位置如下 \[ p_t = S \cdot \mathrm{sigmoid} \left(v_p^T \tanh (W_p h_t) \right), \quad p_t \in [0, S] \] 对齐向量计算
\(\alpha_t\)的长度就是\(2D\),对于每一个\(s \in [p_t -D, p_t + D]\), 为了更好地对齐,添加一个正态分布\(N(\mu, \sigma ^2)\),其中 \(\mu = p_t, \sigma = \frac{D}{2}\)。
计算对齐概率: \[ \alpha_t(s) = \mathrm{align} (h_t, \bar h_s) \exp \left( - \frac{(s - \mu)^2}{2\sigma^2}\right) = \mathrm{align} (h_t, \bar h_s) \exp \left( - \frac{2(s - p_t)^2}{D^2}\right) \]
Input-feeding
前面的Global和Local两种方式中,在每一步的时候,计算每一个attention (实际上是指 \(\hat h_t\)),都是独立的,这样只是次最优的。
在每一步的计算中,这些attention应该有所关联,当前知道之前的attention才对。实际是应该有个coverage set去追踪之前的信息。
我们会把当前的注意\(\hat h_t\) 作为下一次的输入,并且做一个串联,来计算新的attention,如下图所示
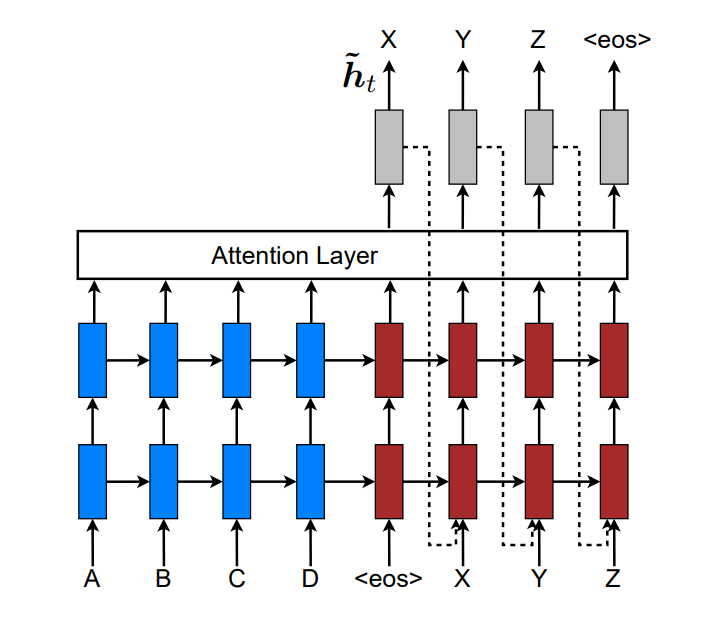
这样有两重意义:
- 模型会知道之前的对齐选择
- 会建立一个水平和垂直都很深的网络
PyTorch实现机器翻译
计算输入语义
比较简单,使用GRU进行编码,使用outputs作为哥哥句子的编码语义。PyTorch RNN处理变长序列
1 | def forward(self, input_seqs, input_lengths, hidden=None): |
计算对齐向量
实际上就是attn_weights, 也就是输入序列对当前要预测的单词的一个注意力分配。
输入输出定义
Encoder的输出,所有语义\(c\),encoder_outputs, [is, b, h]。 is=input_seq_len是输入句子的长度
当前时刻Decoder的\(h_t\), decoder_rnn_output, [ts, b, h] 。实际上ts=1, 因为每次解码一个单词
1 | def forward(self, rnn_outputs, encoder_outputs): |
计算得分
使用gerneral的方式,先过神经网络(线性层),再乘法计算得分
1 | # 过Linear层 (b, h, is) |
softmax计算对齐向量
每一行都是原语义对于某个单词的注意力分配权值向量。对齐向量实际例子
1 | # [b,ts,is] |
计算新的语义
新的语义也就是,对于翻译单词\(w_t\)所需要的带注意力的语义。
输入输出
1 | def forward(self, input_seqs, last_hidden, encoder_outputs): |
当前时刻Decoder的隐状态
输入上一时刻的单词和隐状态,通过GRU,计算当前的隐状态。实际上ts=1
1 | # (ts, b, h), (nl, b, h) |
计算对齐向量
当前时刻的隐状态 rnn_output 和源句子的语义encoder_outputs,计算对齐向量。对齐向量
每一行都是原句子对当前单词(只有一行)的注意力分配。
1 | # 对齐向量 [b,ts,is] |
计算新的语义
原语义和原语义对当前单词分配的注意力,计算当前需要的新语义。
1 | # 新的语义 |
预测当前单词
结合新语义和当前隐状态预测新单词
1 | # 语义和当前隐状态结合 [ts, b, 2h] < [ts, b, h], [ts, b, h] |
总结
1 | # 1. 对齐向量 |

